本文是对《Inductive represation learning on large graph》一文的浅显翻译与理解,原文章已上传至个人资源,如有侵权即刻删除。
前言
该文是一种归纳式的学习算法,相比现行算法将节点嵌入视为可优化的参数,所提出的 GraphSAGE 算法为每个顶点学习向量表示的映射。
算法提出了 GCN、Mean、LSTM 和 Pooling 四种聚合器,可以将节点及其邻居信息结合在一起进行表示,通过不断地迭代,最终为每个节点都学习出向量表示。
算法的核心目的就在于,用聚合函数将节点的向量表示与其邻居所包含的信息结合起来,且其迭代次数,即深度k越大,则保留的高阶相似性就越多。
Title
《Inductive represation learning on large graph》(2017)
——NIPS2017
Author: William L.Hamilton; Rex Ying
Main Body
1 核心算法
全文主要围绕一个核心算法与四个聚合器展开的。

输入:G(V,E);每个节点特征;深度k;权重矩阵W;聚合函数;节点邻居
输出:每个节点的表征
基本流程:
初始化每个节点的0步表征为其自身特征
进入k步循环:
对每个节点计算:
将v上一步邻居向量聚合在一起得到一个整体的邻居向量;
将v上一步向量与得到的邻居向量结合计算得到k步向量;
分母对h每维加和求模,分子的每维与该值作对比,就将范围限制到了(0,1)之间,相当于sotmax;
第k步向量即为节点向量。
2 聚合器
算法介绍了四种聚合器,除上文核心算法中提到的GCN聚合器外,还有Mean、LSTM和Pooling三种聚合器。
对Mean有:
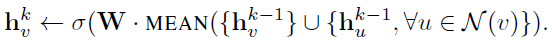
对Pooling有:
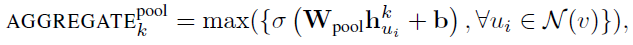
3 损失函数
损失函数最终优化的是节点向量的相似度:
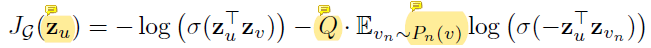
此处的zn即上文算法最终得到的zv,而此处的zv反而是其邻居向量。
超参数有:权重矩阵W;深度k;
4 前向传播算法

算法中输入输出与前文算法唯一不同就在于,节点的取值从全节点集变成了批采样集B。
基本流程:
初始化k步为B,k值再不断减少进入循环:
每步先将上一步的值赋予;
对每个在B中的u节点,再将其邻居节点集也合并到B中(注意到Nk也是在节点的邻居中随机采样,且上下步的采样互不影响);
后续算法与算法一相同,唯一要注意的是:
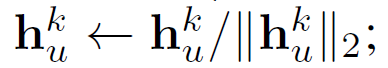
任何属于B^k节点的表示都可以计算,因为它们在k-1步的节点表示及邻居节点表示都已经在上半部分代码中计算过了。
