Curriculum Learning and Graph Neural Networks (or Graph Structure Learning)
Student : Wenxuan Zeng
School : University of Electronic Science and Technology of China
Date : 2022.4.25 - 2022.4.29
文章目录
1 Curriculum Learning
这部分是对curriculum learning的基础知识进行学习,首先从最经典的开山之作“Curriculum Learning”入手,学习其核心思想。

核心思想: 让模型模仿人类的学习策略,先学习简单的样本,然后逐渐学习困难的样本。
优点: 加速模型的训练速度(先从简单的例子中学习知识,迁移到困难例子时会轻松一些),达到相同性能的前提下,curriculum learning让模型更早收敛;模型能具有更好的泛化性,让模型训练到更好的局部最优值状态。
方法: 根据训练样本训练的难易程度,给不同难度的样本分配不同的权重,一开始给简单的样本最高权重,他们有着较高的概率,接着将较难训练的样本权重调高,最后样本权重统一化了,直接在目标训练集上进行训练。需要注意的是,对Curriculum中样本难度的定义是开放式的,针对不同的实际问题可以设置不同的样本难易程度评价标准。
实验: 作者采用了4个toy experiments来证明curriculum learning的效果:① SVM分类;② 感知机;③ 神经网络形状识别;④ 语言模型。
-
SVM
基于两个二维的高斯分布产生两类数据,并算出贝叶斯分类器的决策面。将严格处于决策面两侧的视为简单样本,其它为噪声样本,即复杂样本。仅用简单样本训练得到的SVM分类器所实现的分类错误率为16.3%,而用所有样本训练得到的SVM分类器错误率则有17.3%,说明简单样本对于模型的训练是有用的。
-
感知机
定义了一种样本难易的规则:输入x向量有一部分元素是干扰量,干扰越少,即干扰位数为0的数目越多,样本越简单。
-
神经网络形状识别
定义了两种不同难度的数据:a. 简单样本(等边三角形、正方形、圆形);b. 复杂样本(三角形、矩阵、椭圆)。先训练简单样本后再识别复杂样本的效果优于直接训练复杂样本。
-
语言模型
这里采用的语言任务是完形填空(预测最后一个词),Curriculum Learning的策略是:先从词库中选择5000个最常见的词(被认为是简单样本),先只用含有这些词的训练样本进行模型的训练。然后扩展到10000,15000,20000个词,这样就实现了先简单后困难的学习过程。
Curriculum Learning的有效性: ① 模型在训练初期不需要花费大量时间去学习困难样本,而只需要学习简单的例子;② 引导模型的训练朝更好的局部最优而进行,并依次实现更好的泛化效果。
2 Curriculum Learning for Graph Neural Networks
通过我初步学习,curriculum learning在GNN领域的应用非常广,比如用于简单且普适的图分类或回归任务、用于图表示学习和对比学习任务、用于GNN的多领域自适应问题、用于GNN的pre-training stage中等等。
2.1 CurGraph: Curriculum Learning for Graph Classification
特点: 课程学习、图分类
动机: 在训练图分类任务时,不同图的分类难度差异很大,所以考虑到采用curriculum learning来学习。由于图数据的不规则性,评估图的难度是有挑战性的。
方法: 本文提出CurGraph,在高阶语义特征空间中分析图的难度,用infomax方法获取图级embedding,用神经密度估计器来建模embedding的分布。然乎根据图embedding的类内和类间分布,计算图的难度分数。得到了难度分数,就可以由易到难进行学习了,为了更平滑的过渡,提出smooth-step方法,利用时变平滑函数过滤困难图。
-
Infomax Curriculum Learning
采用了一种SOTA无监督GNN模型(InfoGraph),获取图级embedding。InfoGraph最大化图级embedding和节点级embedding之间的互信息。这种无监督的方式可以学习到更好的图表示。
用距离定义某个图的邻居:
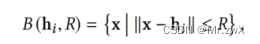
最后计算某个图的难度:
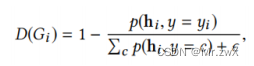
上述中的p代表密度估计,本文采用的是BNAF。
-
Smooth-Step Curriculum Learning
将图的难度划分到S个不同的等级,加入辅助的时变阈值来定义t时刻的困难值,难度值低于阈值的图用于在t时期训练GNN,这样的方式能让训练时图难度的转换更平滑。

实验:
-
图节点分类
在不同的数据集上进行了实验,证明CurGraph的优越性。
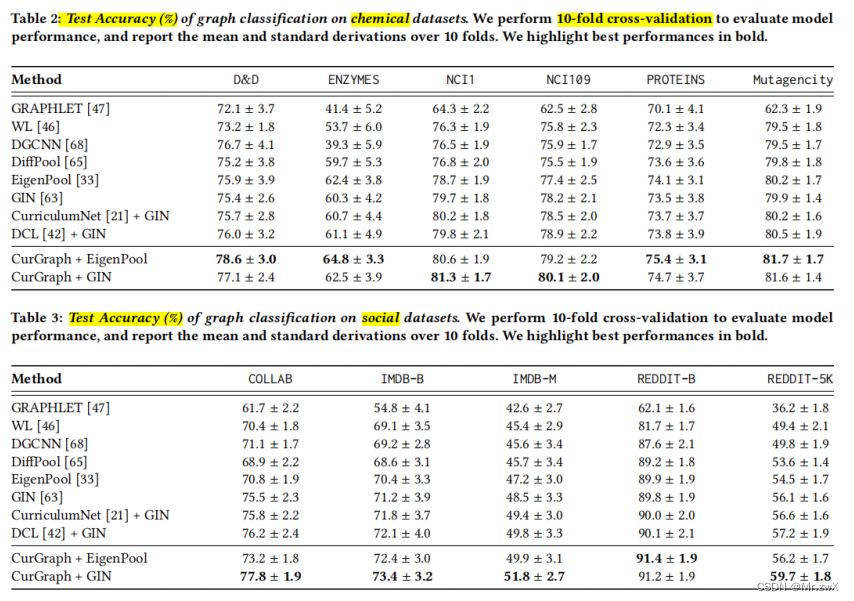
-
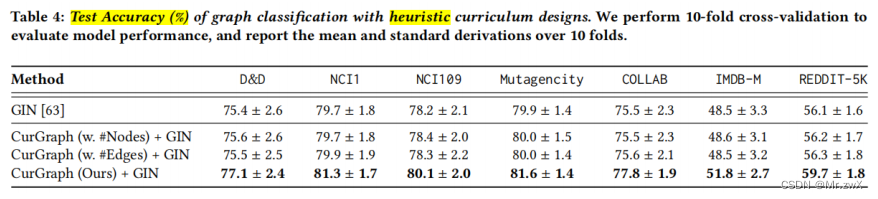
与启发式课程设计的比较
两种启发式课程学习:① #Nodes;② #Edges。观察到由CurGraph提供的困难图往往包含更多的节点和边。
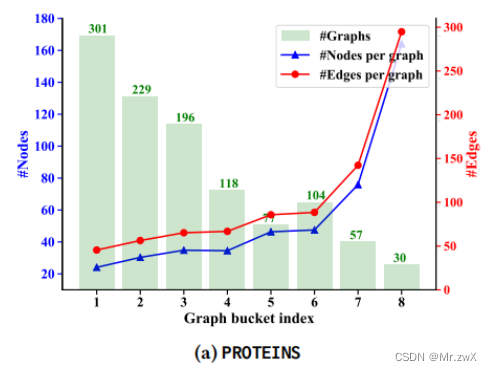
下面是不同难度评估方式的效果对比:
-
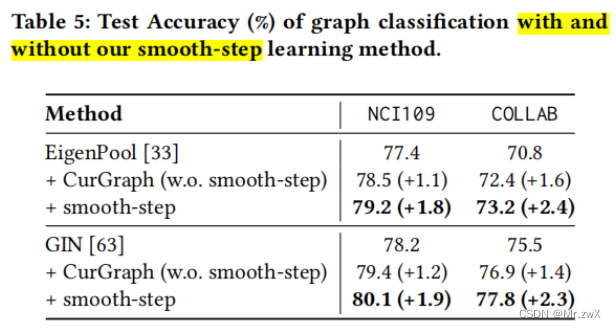
消融实验
采用了smooth-step的模型效果会优于传统课程学习:
-
超参数敏感性
在D&D和IMDB-M数据集上,S=4效果最好;在NCI1数据集上,S=6效果最好。

2.2 CuCo: Graph Representation with Curriculum Contrastive Learning
特点: 课程学习、图对比学习、图表示学习
动机: 由于昂贵的标记数据的限制,基于对比学习的图级表示学习引起了广泛的关注,但是这些方法主要关注正样本的图增强,而对负样本的影响研究较少。
贡献: ① 首次尝试研究负样本对学习图级表示的影响,这在很大程度上被以前的工作忽略了,但对于良好的自监督图级表示学习相当实用和重要;② 提出了一种基于课程对比学习的图表示学习模型,有效地结合了课程学习和对比学习,能够以人类学习的方式自动选择和训练负样本。
方法: 研究负样本对学习图级表示的影响,并提出一种新的自监督图级表示的课程对比学习框架。提出四种图增强的方式获取正负样本,然后用GNN学习图表示。紧接着,提出评分函数对负样本从容易到困难进行排序,起步器函数在每个训练过程中自动选择负样本。
-
图增强
本文介绍4种图增强的方式:① 随机丢弃某些节点及其连接;② 通过随机添加或减少一定比例的边来扰动连接性;③ 特征掩码,提示模型使用其上下文信息恢复掩码的节点特征;④ 使用随机游走从G中采样一个子图的子图
-
图编码器
得到图增强后的图,需要学习表示。本文选择GNN作为图编码器:
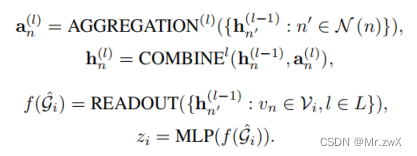
-
记忆对比学习
采样的噪声对比估计损失:
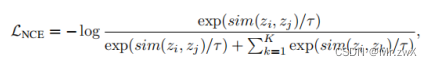
最小化这个loss代表在记忆库中强制使正样本对的得分高于负样本对的得分。为简化计算,本文使用dot-product作为相似度度量函数。
-
负样本采样的课程设置
主要思想是在训练过程中根据负样本的难度对其进行排序,课程学习主要包括三个要素:
① 评分函数(scoring function)
采用cosine相似度、dot-product相似度这两种度量方法。

② 起步器函数(pacing function)
用起步器函数来安排如何将负样本引入训练。
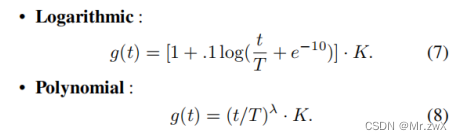
③ 顺序(order)
为了缩小使用基于上升难度水平的评分函数的具体效果,指定了课程的顺序(从最低分数到最高分数排序)、反课程(从最高分数到最低分数排序)或随机排序。
-
Early-stop机制
在训练后期,随着负样本难度的增加,具有相同标签的假负样本的比例会增加,假负样本会影响模型的泛化性能。为了缓解这个问题,设计了一个Early-stop机制。定义了一个耐心超参数p,当损失不再减少时,p值开始下降,一旦p变成0,训练就会停止。
实验:
-
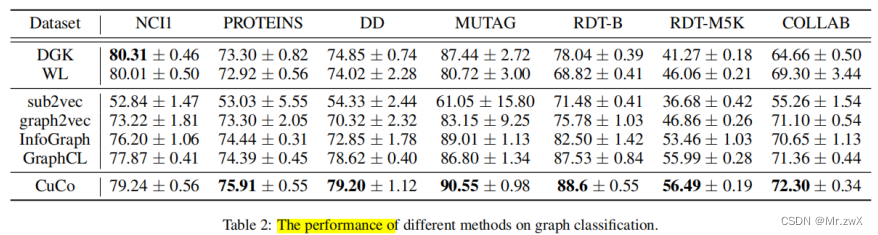
性能对比
-
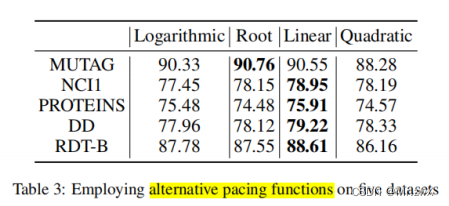
起步器选择
-
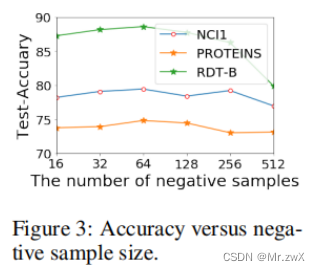
负样本的采样数量
-
训练顺序

-
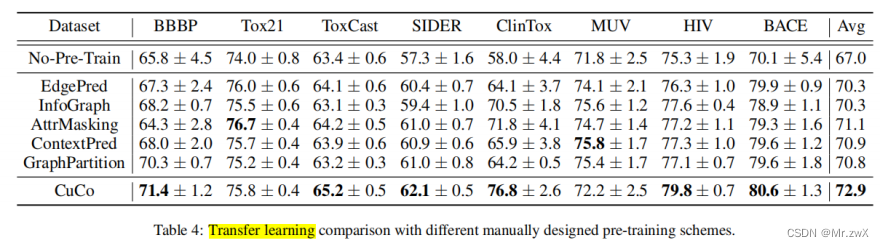
迁移学习
2.3 Curriculum Graph Co-Teaching for Multi-Target Domain Adaptation (CVPR '21)
-
特点: 单源域-多目标源域、课程学习、伪标签生成
-
动机: 解决多领域迁移的问题。
-
贡献: ① 提出了MTDA的课程图协同教学 (CGCT),它利用与双分类器头的协同教学策略、课程学习方式,来学习跨多个目标领域的更鲁棒的表示;② 为了更好地利用领域标签,提出了一种领域感知课程学习 (DCL)策略,使特征对齐过程更平滑
-
方法: 两个角度减轻多领域迁移的问题,特征聚合和课程学习。提出课程图协同学习,用的双分类器头,其中一个是GCN聚合了来自于跨域的类似样本的特征。防止分类器对其自身的噪声伪标签进行过拟合。防止分类器对其自身的噪声伪标签进行过拟合,开发一种与双分类器头的协同教学策略,并辅以课程学习,以获得更可靠的伪标签。另外,当领域标签可用时,提出领域感知课程学习(DCL),这是一种顺序适应策略,首先适应更容易的目标领域,然后是更难的目标领域。
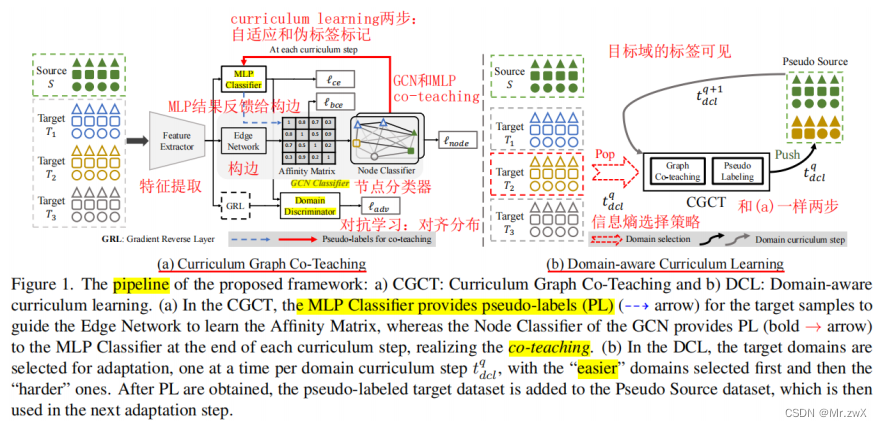
-
(a) Curriculum Graph Co-Teaching
STEP 1:领域自适应
用 f e d g e f_{edge} fedge来生成邻接矩阵,其监督信息是MLP给的,MLP对节点之间的边进行标注(两个节点的标签一致,则它们之间的相似度为1,否则为0):
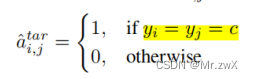
则生成邻接矩阵的loss:
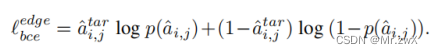
GCN和MLP在源域上的loss:
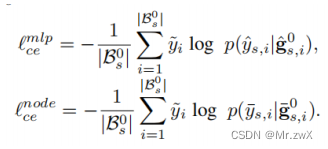
最终优化的目标为:

STEP 2:伪标签标注
用GCN对无标签数据进行标注,小于某个阈值则不参与训练。为什么选GCN的输出进行标注?作者说考虑到GCN进行特征的聚合,相比MLP更具有鲁棒性。然后数据变为:
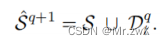
-
(b) Domain-aware Curriculum Learning
作者考虑了目标域带标签的情形。不同目标域与源领域的数据分布的shift程度是不一样的,因此自适应的难度不一样。这里采用了Easy-to-Hard Domain Selection (EHDS) 策略,先适应easy的domain,再适应hard的领域,原因就是模型适应shift较小的领域明显比shift较大的领域容易。
如何衡量哪个domain更容易?作者用信息熵衡量了这个指标:
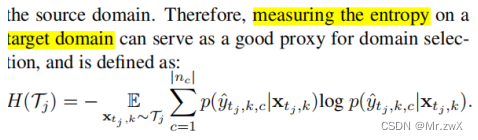
-
除了上面提到的研究之外,还有curriculum learning应用于异构图预训练的推荐系统领域(即使模型采用的Transformer)。
链接:Curriculum Pre-Training Heterogeneous Subgraph Transformer for Top-N Recommendation
3 Graph Structure Learning
下面列出了我认为近两年非常值得一读的graph structure learning方法,我标出了paper采用的主要方法(包括生成语义图、自监督、拓扑相似性、注意力机制、模型参数化/概率化、去噪、VAE生成模型等)。在我之前投KDD 2022的论文中,就采用了自监督、生成模型、注意力机制三种策略去构造优质的图,供GCN训练。

4 Curriculum Learning for Graph Structure Learning
据我近期的调研,我发现专门将curriculum learning应用到图结构学习任务的很少。我想说明一篇我很喜欢的经典论文《Connecting the Dots:Multivariate Time Series Forecasting with Graph Neural Networks》,这篇论文首次将GNN引入到多元时序预测任务中,通过注意力机制实现end-to-end graph structure learning,同时利用curriculum learning策略降低训练时的难度。
这篇paper的框架是这样的:
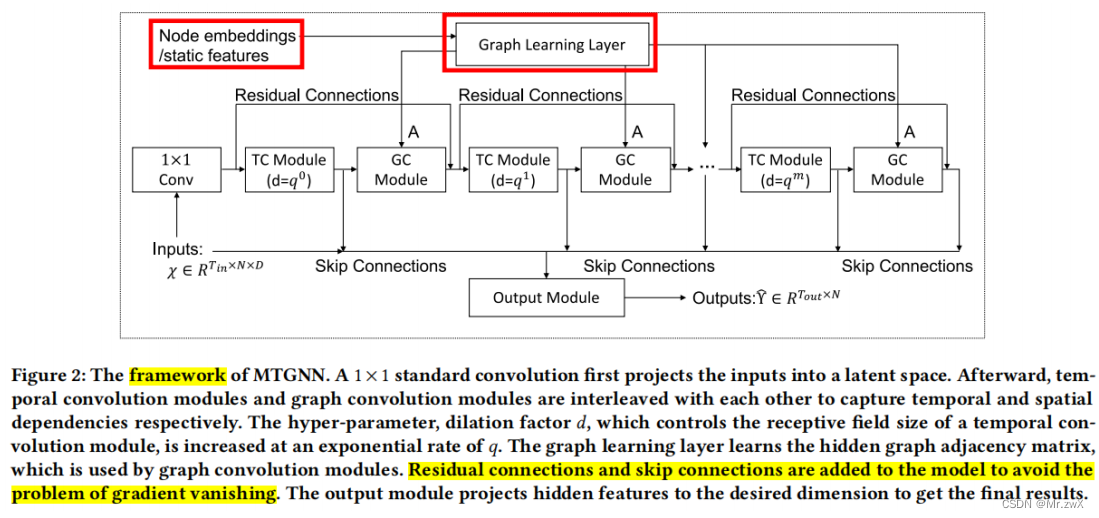
学习图结构的注意力机制:

在multi-step forecasting时,本文提出采用curriculum learning的策略,先从简单的(短期)开始预测,然后逐步扩展到复杂的(长期)的时间步预测。在这个过程中,不断动态地构图进行训练,实验证明这个机制是简单有效的。

不过换句话说,其实将这个过程理解为“curriculum learning应用于graph structure learning”难免有些牵强,因为图结构的学习是一个在训练迭代过程中稳定学习的部分。
所以将curriculum learning应用于graph structure learning这个方面,还有很多很多空间可以让我们去思考。对于这方面,我也有一些初步的思考,比如之前我说的构图时将模型参数化,其实可以从这个角度去设计一种评估节点构图难度的指标,在训练迭代的过程中,逐步进行构图,而不是一步到位,迭代更新一个初期可能不太好的图结构(如果不稀疏,则初期计算量会很大)。
arning应用于graph structure learning”难免有些牵强,因为图结构的学习是一个在训练迭代过程中稳定学习的部分。
所以将curriculum learning应用于graph structure learning这个方面,还有很多很多空间可以让我们去思考。对于这方面,我也有一些初步的思考,比如之前我说的构图时将模型参数化,其实可以从这个角度去设计一种评估节点构图难度的指标,在训练迭代的过程中,逐步进行构图,而不是一步到位,迭代更新一个初期可能不太好的图结构(如果不稀疏,则初期计算量会很大)。