learning graph embedding with adversarial training methods
发表于IEEE T CYBERNETICS 2020.
abstract
众多的图嵌入任务关注于保存图结构或者最小化图数据上的重构损失。这些方法忽略了latent code的embedding distribution,可能会导致许多情况下较差的representation。本文中提出了一种图嵌入的adversarially regularized framework(对抗性正则化框架)。the adversarial training principle被用于使latent code来匹配一个prior gaussian或者uniform distribution。基于这个框架我们发展了两种对抗模型的变体:ARGA,ARVGA。众多的实验结果证明了我们方法的有效性。
key point:以往的图嵌入方法忽略了latent code的embedding distribution,可能会导致许多情况下较差的representation。(在学习图嵌入的过程中需要考虑到合理的分布)。
1. introduction
我们框架不仅仅是需要最小化拓扑结构的重构损失,而且需要使得学习到的latent embedding来匹配一个先验分布。
4.proposed algorithm
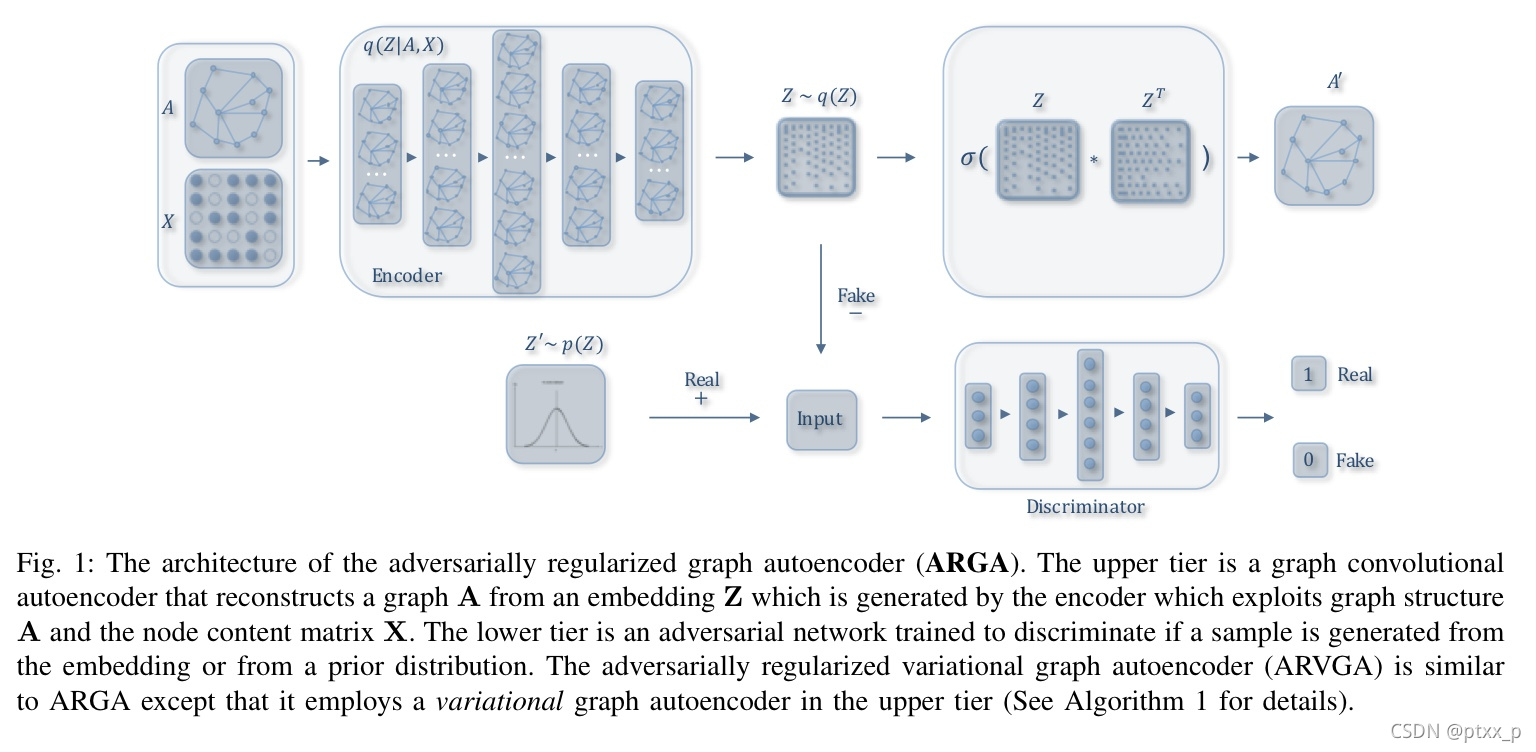
adversarially regularized graph autoencoder(ARGA):
包括两个部分:graph convolutional autoencoder(输入为图A以及节点内容X,用于学习一个latent representation Z)、adversarial regularization(用于通过对抗训练模块来使得latent codes匹配一个先验分布,判别现在 z i ∈ Z z_i \in Z zi∈Z是来自于encoder还是来自于先验分布)。
4.1 graph convolutional autoencoder
两个基础性的问题:1.如何在encoder中同时综合结构信息以及内容信息 2.哪种信息需要通过decoder进行重构。
graph convolutional encoder model G ( X , A ) G(X,A) G(X,A):
频域卷积过程:
其中 Z ( l ) , Z ( l + 1 ) Z^{(l)},Z^{(l+1)} Z(l),Z(l+1)分别是卷积的输入以及输出, A A A为定义的邻接矩阵, Z 0 = X ∈ R n × m Z^0 = X \in \mathbb{R}^{n \times m} Z0=X∈Rn×m, n , m n,m n,m分别代表节点的数目以及特征的数目。

G ( X , A ) G(X,A) G(X,A)使用了两层的GCN卷积,我们的文章中,还发展了两种编码模型的变体:graph encoder,variational graph encoder。
graph encoder定义如下:
即graph convolutional encoder G ( Z , A ) = q ( Z ∣ X , A ) G(Z,A)=q(Z|X,A) G(Z,A)=q(Z∣X,A),同时编码了图结构以及节点内容为一个表征 Z = q ( Z ∣ X , A ) = Z ( 2 ) . Z = q(Z|X,A)=Z^{(2)}. Z=q(Z∣X,A)=Z(2).
variational graph encoder定义为一个inference model:
其中 μ = Z ( 2 ) \mu = Z^{(2)} μ=Z(2)是mean vectors z i z_i zi的矩阵, l o g σ = f l i n e a r ( Z ( 1 ) , A ∣ W ′ ( 1 ) ) log \sigma = f_{linear}(Z^{(1)},A|W^{'(1)}) logσ=flinear(Z(1),A∣W′(1))其中 W ′ ( 1 ) = W ( 0 ) W^{'(1)}=W^{(0)} W′(1)=W(0),和第一层的 μ \mu μ共享权重。
decoder model:
用于重构图数据。ARGA decoder p ( A ^ ∣ Z ) p(\hat{A}|Z) p(A^∣Z)预测在两个节点之间是否存在一个link。更具体来说,我们训练一个link prediction layer基于图嵌入:
这里的预测值 ( ^ A ) \hat(A) (^A)应该和ground truth A A A接近。
graph autoencoder model:
embedding Z Z Z以及重构图 A ^ \hat{A} A^可以被表示如下:
optimization:
对于graph encoder,我们最小化图数据的重构损失:
对于variational graph encoder,我们优化变分下界:
其中 p ( Z ) p(Z) p(Z)为先验分布,可以是uniform distribution或者gaussian distribution
4.2 adversarial model D ( Z ) \mathcal{D}(Z) D(Z)
我们的模型的基础idea是使得潜在分布 Z Z Z匹配一个先验分布,通过对抗训练模型来实现。adversarial model基于标准MLP建立,输出层只有一维with a sigmoid function。adversarial model acts为一个辨别器来辨别一个latent code是来自于the prior p z p_z pz(positive)或者graph encoder G ( X , A ) G(X,A) G(X,A)(negative)。通过最小化二分类器的交叉熵,embedding 最终会在训练过程中被regularized 以及improved,cost被定义如下:
p z p_z pz为先验分布。
adversarial graph autoencoder model:
训练带有辨别器 D ( Z ) \mathcal{D}(Z) D(Z)的encoder model:
其中 G ( X , A ) G(X,A) G(X,A)为generator, D ( Z ) \mathcal{D}(Z) D(Z)为discriminator。
4.3 algorithm explanation

4.4 decoder variations
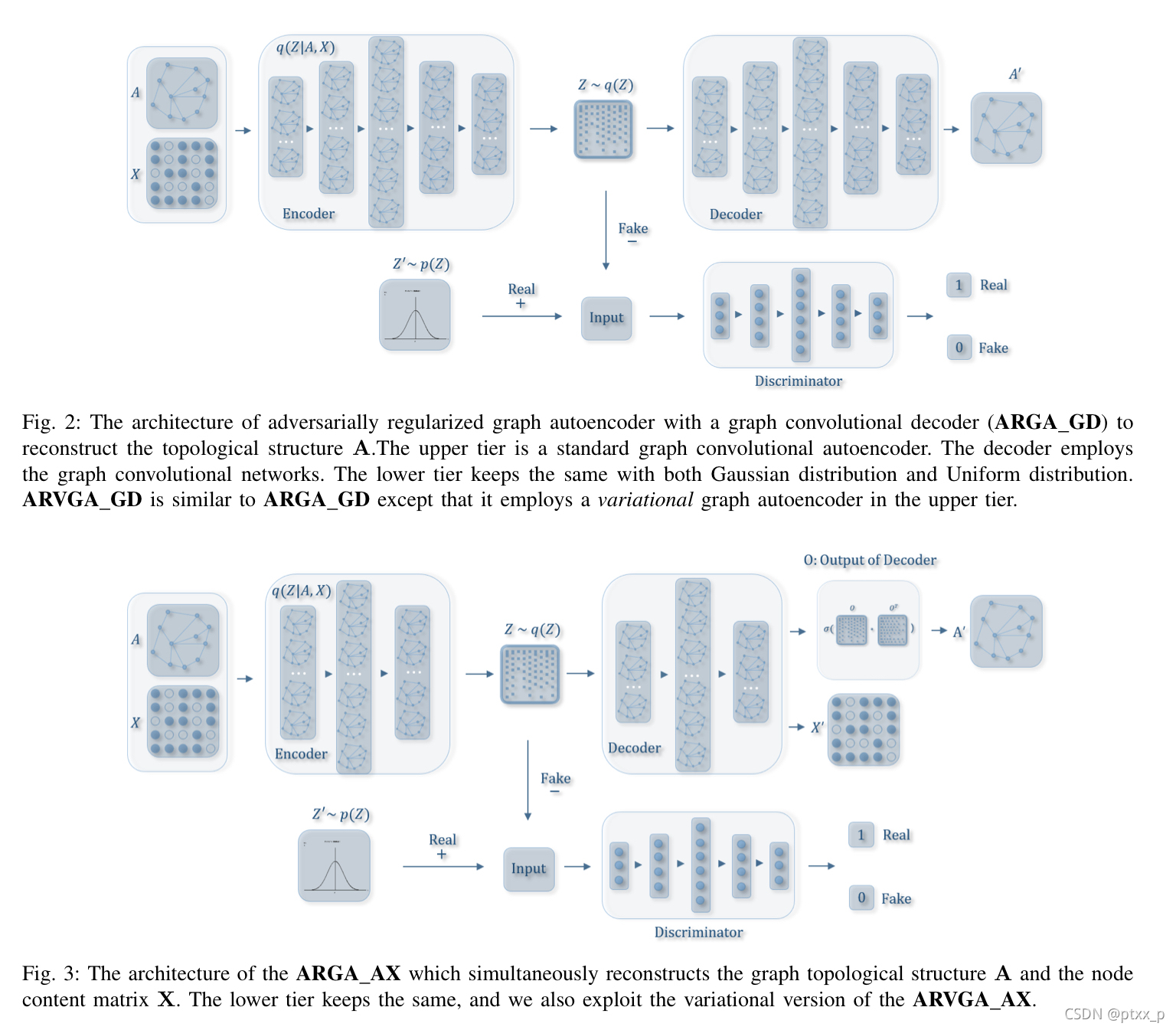
在ARGA和ARVGA模型中,decoder只是embedding z的点积的link prediction layer。但是decoder也可以是图卷积层或者链接预测层与图卷积decoder层的组合。
GCN decoder for graph structure reconstruction(ARGA_GD):
修改encoder通过添加两个图卷积层来重构图结构。这种方法的变体被称为ARGA_GD。在这种方法中,decoder的输入是encoder的embedding,图卷积的decoder的构建过程如下:
其中, Z , Z D , O Z,Z_D,O Z,ZD,O分别是从图encoder中学习得到的embedding,图decoder第一层和第二层的输出。重构损失计算如下:
GCN decoder for both graph structure and content information reconstruction(ARGA_AX):
我们修改了第二层图卷积层的维度为与每个节点关联特征的数目,因此第二层的输出为 O ∈ R n × f ∋ X . O \in \mathbb{R}^{n \times f }\ni X. O∈Rn×f∋X.重构损失由两种error构成。首先是重构损失:
之后是节点内容的重构损失:
最终的重构损失为: L O = L A + L X . L_O=L_A+L_X. LO=LA+LX.