标题
Large-Scale Hierarchical Text Classification with
Recursively Regularized Deep Graph-CNN(HR-DGCNN)
代码:https://github.com/HKUST-KnowComp/DeepGraphCNNforTexts
背景
文本分类领域一直使用词袋模型(BOW)、N-gram模型,随着不同主题粒度的标注数据出现,词袋不够用。深度学习,RNN只能在短文本上充分捕捉语义;层次化RNN(门控)用于长文本,只能被用于常规的文本和正式的语言(?);CNNs类似于n-grams,只能在连续的单词上建模。
对于篇章级别的主题分类,非连续性短语和长距离依赖更为重要。
模型
将文章转换成图
符号
K个所有可能的标签
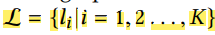
l i l_i li的 K i K_i Ki个子标签
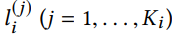
M个{文章,文章对应标签集}的训练实例
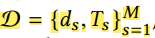
词共现图
- 分词
- 取词根
- 去停用词
- 使用固定大小的窗口计算词共现,如大小为3的窗口,每滑动一次会带来两条边:窗口[2]->窗口[1] 和 窗口[1]->窗口[0]

词共现图的子图
子图生成
- 按度排序
- 按出现次数排序
- 再按"their connections with neighbors"排序(我理解为出度)
- 选取前N的单词
| 单词 | 度 | 出现次数 | 出度? |
|---|---|---|---|
| goalscor | 9 | 2 | - |
| england | 6 | 2 | - |
| club | 5 | 1 | 3 |
| fit | 5 | 1 | 2 |
| high | 5 | 1 | 1 |
| great | 3 | 1 | 2 |
| unit | 3 | 1 | 1 |
| true | 3 | 1 | - |
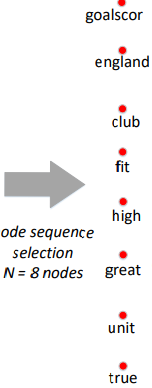
- 对于每个单词,采用广度优先搜索子图(子图节点个数不少于g,如果该轮搜索得到的节点少于g,则加大深度再搜索一轮)

子图正则化
- 从根节点出发(标1)
- 按照广度优先深度排序
- 按照度排序
- 按照其它因素排序
- 选择g个节点(给不满g个节点的子图增加哑节点)
以goalscor为例
| goalscor | england | fit | club | high | |
|---|---|---|---|---|---|
| 序号 | 1 | 2 | 3 | 4 | 舍去 |
| 深度 | 0 | 1 | 1 | 1 | 2 |
| 度 | - | 5 | 5 | 4 | - |
| 其它因素 | ? | ? | ? | ? | - |

embedding
word2vec 50dim
HR-DGCNN
卷积层

- 输入:NxgxD(N:子图数,g子图节点数,D词向量维度)
- 卷积层1: k1个 gxD的卷积,每一个gxD的卷积产生Nx1的向量
- 输出:Nxk1
- 池化层1:在N中选择N/2
- 输出:N/2xk1
- 卷积层2: k2个 5x1???(我觉得是N/2 x1)的卷积核,每一个卷积产生 k1x1的向量
- 输出:k1xk2
- 池化层2:在k1中选择k1/2
- 输出:k1/2xk2
- 卷积层3:k3个1x5的卷积核,滑动步长为3
- 输出:Sxk3
- 池化层3:在S中选择S/2
- 输出:S/2xk3
完全不懂
全连接层&输出

- 全连接层1: S/2xk3xF1
- 输出1:1xF1
- 全连接层2:F1xF2
- 输出2:1xF2
- 全连接层3:F2xF3
- 输出3:1xF3
- 输出层:F3xK
- 输出4:1xK
最后的损失函数:
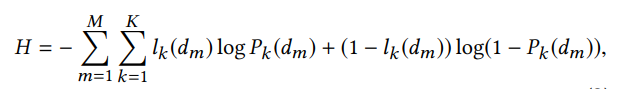
正则化

标签之间也有父与子的关系。
正则化之后的损失函数:
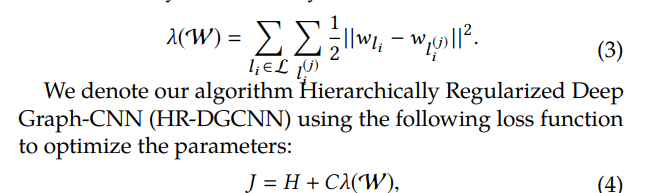

下游任务
层次化文本(篇章)分类
优缺点
把整篇文章看作是一个词节点组成的图,而不能得到其中句子的向量表示。更深层次讲,HR-DGCNN依然走的是CNN的老路:从一开始把篇章转换为图的时候,就在模仿图像领域,把篇章建模成N x g x D的规则矩阵;并且,单词和单词之间的边也只是体现在建图过程中,甚至没有分配一个权重。在计算的时候,也是引入卷积、引入池化。总的来说,个人感觉HR-DGCNN并没有跳脱CNN,而以图的思想来建模整篇文章、或者句子。(本人这方面水平真的真的有限,欢迎评论)
“they viewed a document or a sentence as a graph of word nodes”——《Graph Convolutional Networks for Text Classification》
拓展
暂时没有