线性回归
目录
- 线性回归
把李宏毅的“宝可梦”线性回归的视频又刷了一遍~
是时候记录下来啦~
一、线性回归
首先,什么是线性回归?
无非就是一个函数
举个“宝可梦”的例子:
小智在野外抓了一只皮卡丘,皮卡丘进化后是雷丘,小智想知道雷丘的战斗力如何?
小智去问大木博士,博士只给了小智10只宝可梦的详细信息(进化前和进化后的属性信息都知道),让小智建立线性回归模型预测下?
小智觉得皮卡丘进化后的战斗力与它当前的战斗力有关,然后就开始建立模型了!

模型很简单:
就是战斗力
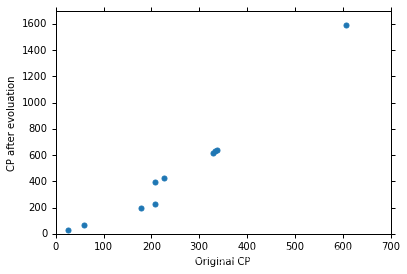
小智把10只“宝可梦”的
(进化前的战斗力)和
(进化后的真正战斗力)绘制在图上:
损失函数记为:

样本真正值:
模型预测值:
展开代入:

显然,损失函数我们只要确定w,b两个参数
不同的参数对应不同的方法
最小的损失对应最好的方法

如何求得最小的loss及对应的参数呢?那就是Gradient Descent
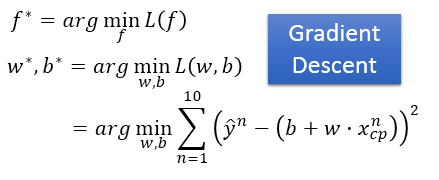
思想:
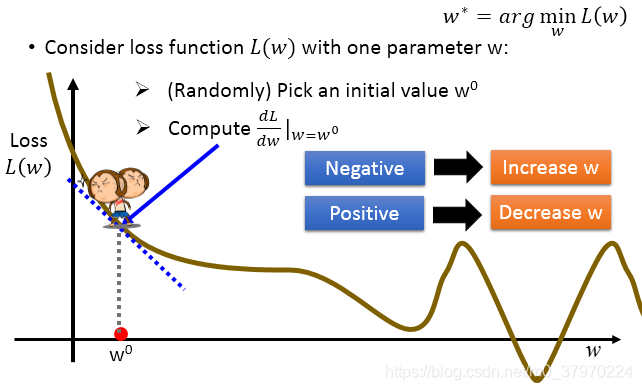
1. 随机选择初始值
2. 计算 处的导数,
3. 该处导数为负数,增加w,反之减少w。当等于0时,停下来
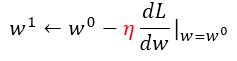
其中
表示步长,即 learning rate,学习率
如果是两个参数呢,那也一样,记为:
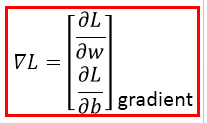
那应该是这样的一种情况:
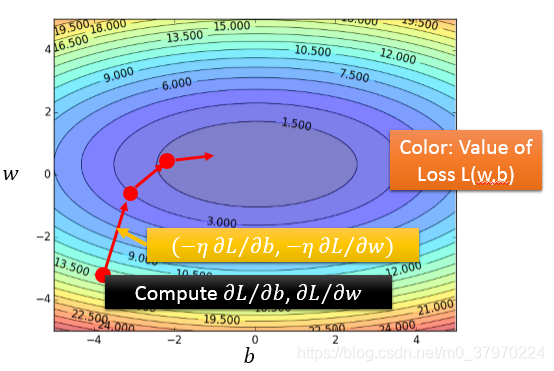
疑问点一:
显然,有点不科学,学过数学的都知道,拐点处、局部最小值的导数均为0。(连续可导函数,最小值处的导数必定为0,导数为0的点未必是最小值)
继续往下看
然后,我们用1次,2次,…5次函数来拟合数据
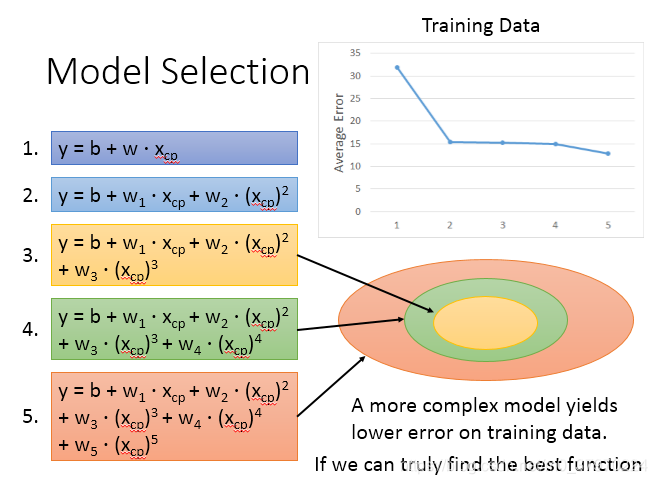
显然,我们的直觉是越高次的曲线,在training set上面拟合的越好。
注:这里你可能会有疑问 是二次的呀,怎么能说是线性的呢?李宏毅老师告诉我们这也是线性的,你可以把它看成另一个属性特征
然后,对比在testing set和training set上的erro,发现高次的overfitting(过拟合),最好的是三次的。
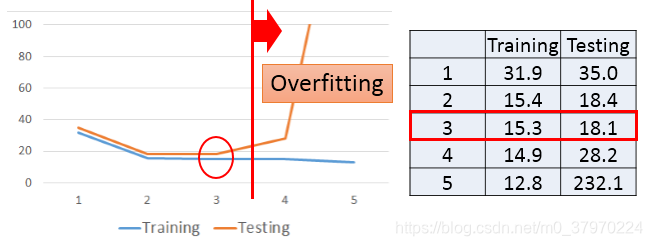
是否可以收集更多的数据,使得模型更精确呢?
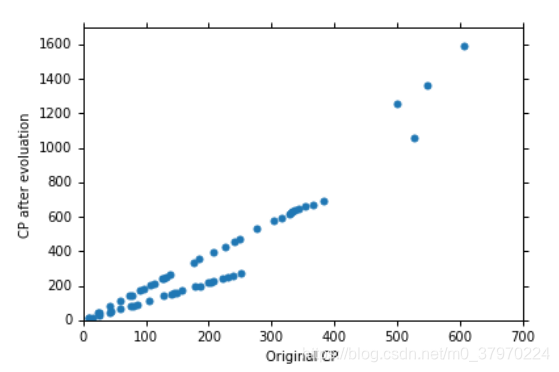
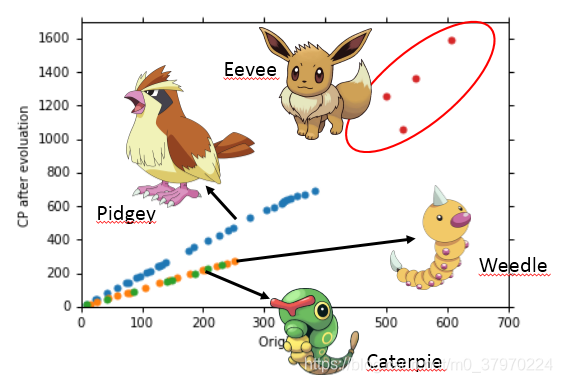
又或者还有其他的影响因素呢?
大木博士说还和种类有关系
小智列出了下面的方程:
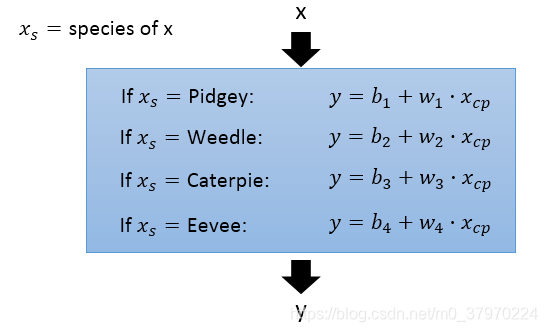
也可合成一个:

最后效果确实比较好。
正则化(Regularization):

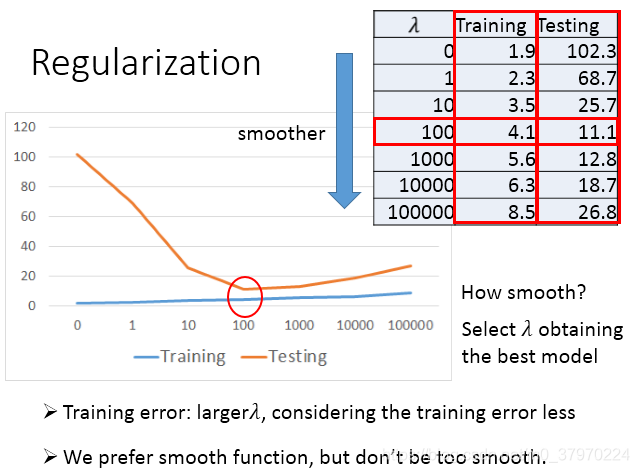
具体的正则化会有一节专门讲~(交叉验证和正则化)
所以,总结下:
留了几个问题:
梯度下降算法导数为0的点~
正则化