回归与分类的区别
和分类问题一样,回归问题也是预测目标值的过程。回归与分类不同点在于,前者预测连续型变量,后者预测离散型变量。
线性回归
- 结果易于理解
- 对非线性的数据拟合不好
- 适用于数值型和标称型数据
线性回归步骤
- 将标称型数据编码为二值数据(one-Hot编码)
- 训练算法得到回归系数
- 利用
R2 评价模型 - 使用回归系数预测数据
回归系数
对于给定的训练数据集
用矩阵表示可以表示为
局部加权线性回归
简单线性回归容易出现欠拟合的现象,也就是说模型对一些线性关系不是很好的训练集误差较大,因此有人提出局部加权线性回归的方法。该算法给待预测点附近的每个点赋予一定权重,距离越近权重越大。加权之后再进行普通线性回归。因此,这种算法每预测一次都需要选择预测点附近的数据子集。因此
其中
一般我们可以采用高斯核(与SVM中的核函数意义相近)来表示每个点的权重:
这样得到的
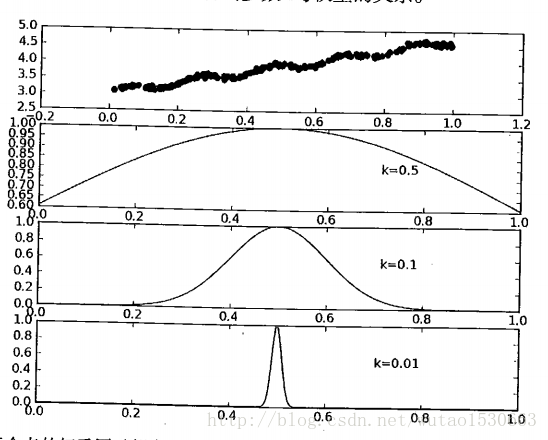
局部加权回归的优缺点
- 缺点:每次进行预测时,算法都需要用到整个数据集,因此占用了很多空间和时间
- 优点 : 能够解决简单线性回归欠拟合的缺点,通过调参也可以缓解过拟合的情况
缩减方法
前面说到,如果
岭回归
岭回归实际上就是在
岭回归可以用于处理特征数量多于样本数的回归问题,还能引入估计偏差(引入罚项),进而有更好的泛化能力。
需要注意的是,由于岭回归引入了
lasso
岭回归相当于给回归系数
根据拉格朗日乘子法可知,岭回归相当于给普通线性回归增加了一个约束,可以等价于:
从这种约束表达形式来看,我们也能更好的理解为什么岭回归要对数据进行标准化处理,如果不进行标准化,那么有可能个别特征的回归系数就会很大,导致别的特征回归系数很小。而lasso方法就是将约束条件改为
虽然形式只是平方项变为绝对值,但是却大大增加了计算的复杂度,lasso约束在
前向逐步回归
前向逐步回归是一种迭代贪心算法,每一步都尽可能减小误差。具体算法步骤如下所示
- 数据标准化使数据满足0均值,单位方差
- 迭代一定次数,在每次迭代过程中:
- 设置当前最小误差lowestError为正无穷
- 对每个特征:
- 增大或缩小:
- 改变一个系数得到新的权重
W - 计算权重
W 的平方误差 - 若小于最小误差,则设最小误差为当前误差,设置
Wbest 为当前W
- 改变一个系数得到新的权重
- 将
W 设置为新的Wbest
- 增大或缩小:
采用前向迭代回归可以帮助对模型的理解,可以找出重要的特征。
缩减方法(岭回归或前向迭代回归)能够增强模型泛化能力,同时也带来了一定得偏差。在偏差(bias)与方差(variance)的平衡中,可以通过交叉验证等方法选择最优模型。