线性回归之误差分析
首先回顾下上一节得到的曲线长这样:
图来源于李宏毅大神~

error主要来源于两方面:
bias:标准差
variance:方差
简单的来理解一下bias(标准差)及variance(方差)
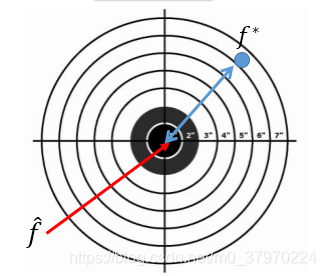
比如:“预测宝可梦进化后的战斗力的例子”
我们知道一定存在一个最佳的数学模型来预测新的“宝可梦”进化后战斗力,记为 (这也是我们辛辛苦苦想找的)
但是,我们每次实验结果得到最好的模型并非就是 ,我们记为
那我们进行多次实验,就会得到多个 ,假如进行n次实验,我们取平均得:
故:
(离靶心有多远)
variance方差:简单的理解就是数据的离散程度,方差越大越离散,反之越集中。

上面我们N个样本的平均值为m,无限接近
,但不等于
,数学期望等于
,数据越多越集中在
附近

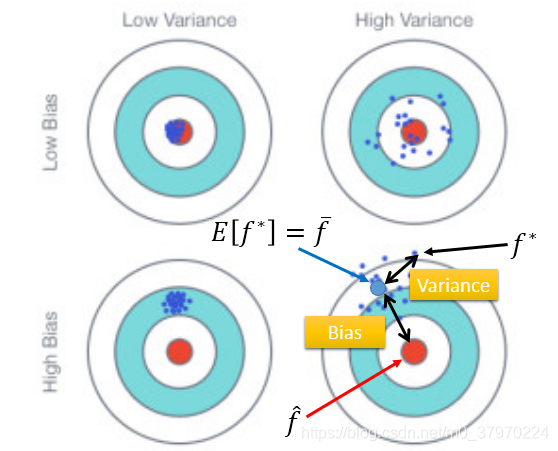
所以,我们希望找到 low baise 和 low variance
实验
场景:小智分别用一次、二次…五次的模型各做了100次实验(即100个 ),每次实验在野外随机抓10只“宝可梦”。
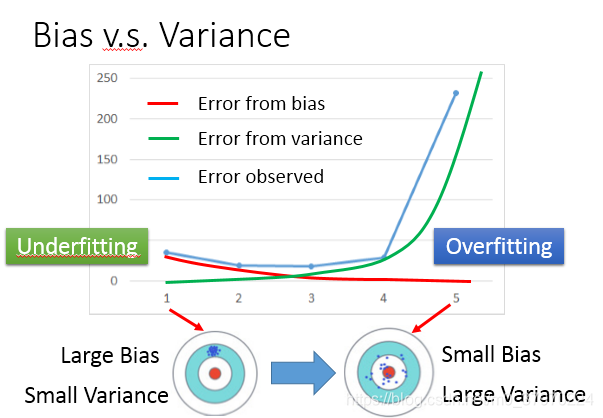
得出方差的结论如下:
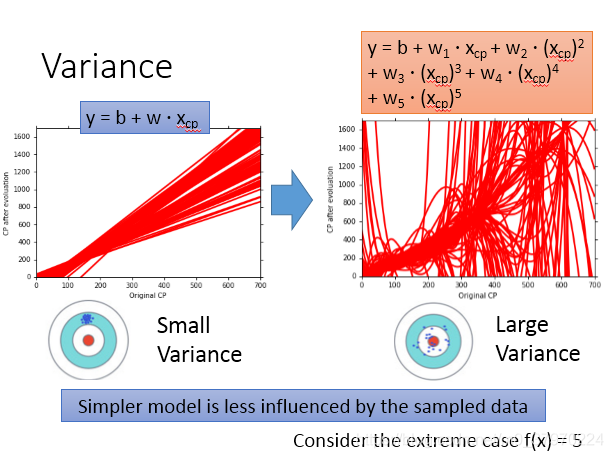
低次模型具有较小的方差,高次模型具有较大的方差
关于bais方面:
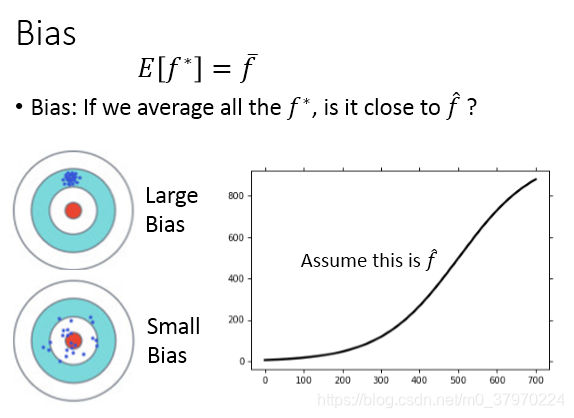
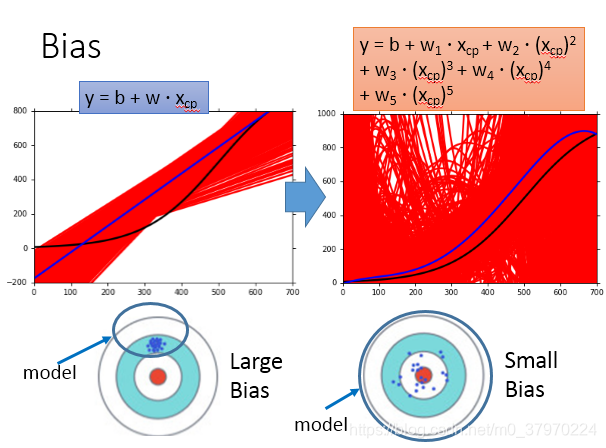
低次的模型具有较大的bias,而高次的模型具有较小的bias
试着来解释一下:
高次的模型包含的Function Sets范围更大,更容易把靶心(
)包含进来。
而低次的模型包含范围更小,容易漏掉靶心
所以我们要权衡这两者:
问题来了:
如果bias大,该怎么办?
bias大说明靶心可能不在你设计的模型中,你需要重新设计模型(更复杂),可能需要考虑更多的因变量
问题来了:
如果variance大,该怎么办?
variance大说明过拟合啦~
过拟合可以增加数据量、正则化、dropout等…
具体参见过拟合的策略