HDFS又名为分布式文件系统,即为文件系统,接下来从以下几个方面进行介绍:
1 分布式文件系统
2 HDFS简介
3 HDFS相关概念
4 HDFS体系结构
5 HDFS存储原理
6 HDFS数据读写过程
7 HDFS编程实践
以上主要参考厦门大学林子雨老师大数据课程,推荐学习地址:http://dblab.xmu.edu.cn/blog/category/big-data/
- 分布式文件系统
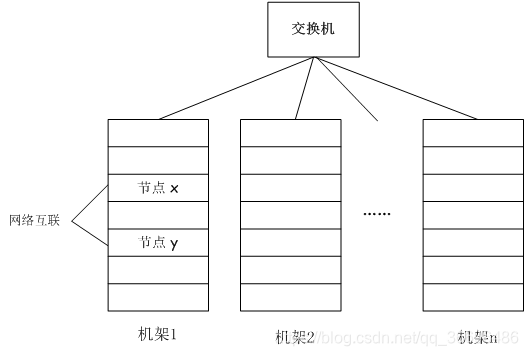
分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群
与之前使用多个处理器和专用高级硬件的并行化处理装置不同的是,目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销
如图所示:
而HDFS的应满足:
●兼容廉价的硬件设备
●流数据读写
●大数据集
●简单的文件模型
●强大的跨平台兼容性
- HDFS主要的功能
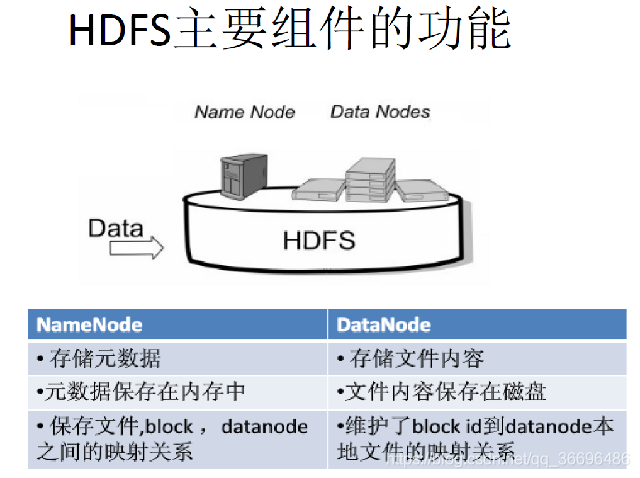
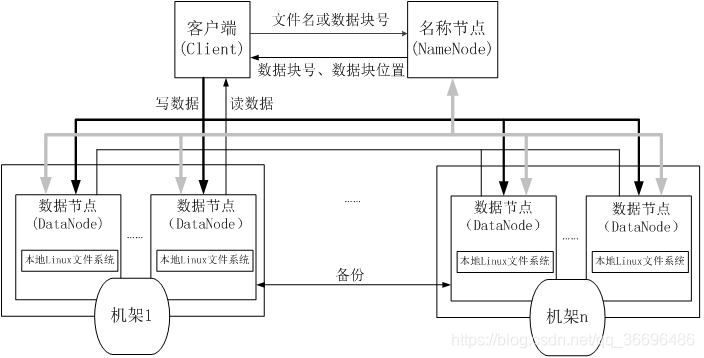
HDFS具体结构如下:
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
名称节点记录了每个文件中各个块所在的数据节点的位置信息
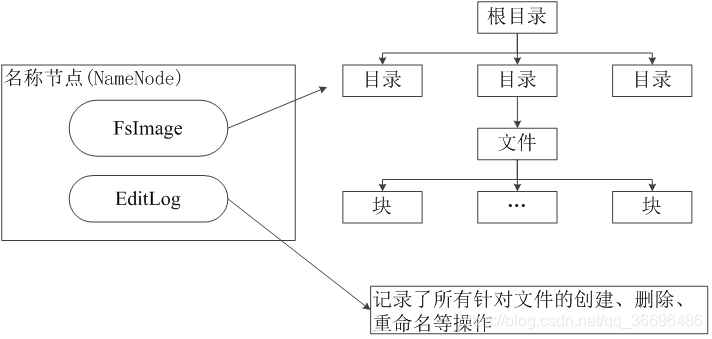
- FsImage
FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示,并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据
FsImage文件没有记录文件包含哪些块以及每个块存储在哪个数据节点。而是由名称节点把这些映射信息保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
- 名称节点的启动过程
在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件
名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新
- EditLog
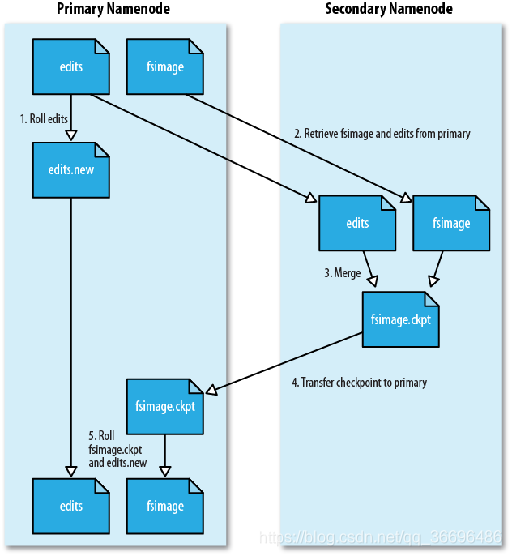
在名称节点运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文件将会变得很大
虽然这对名称节点运行时候是没有什么明显影响的,但是,当名称节点重启的时候,名称节点需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式,一直无法对外提供写操作,影响了用户的使用
解决方法:
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上
- 数据节点DataNode
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
** HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)(如图3-4所示)。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的
**
- 编程实战
使用eclipse操作HDFS读文件:
/*FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类
Hadoop为FileSystem这个抽象类提供了多种具体实现
DistributedFileSystem就是FileSystem在HDFS文件系统中的具体实现
FileSystem的open()方法返回的是一个输入流FSDataInputStream对象,在HDFS文件系统中,具体的输入流就是DFSInputStream;FileSystem中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统中,具体的输出流就是DFSOutputStream。
*/
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test");
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
写文件:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
byte[] buff = "Hello world".getBytes(); // 要写入的内容
String filename = "test"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println("Create:"+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
