(一)SeconderyNameNode 第二名称节点作用
1.解决Editlog不断增大的问题(定期地和名称节点进行通讯,当EditLog文件达到一定程度,就停止使用EditLog文件,名称节点停止当前EditLog的使用,并生成新的Editlog,同时将老的EditLog丢给第二名称节点 ,第二名称节点处理将就得Editlog和FsIamge合并,生成新的FsImage后交给名称节点)
2.充当名称节点的冷备份
冷备份是当第一名称节点发生故障后,必须停止一段时间,慢慢恢复,再提供对外服务
名称节点也称管家
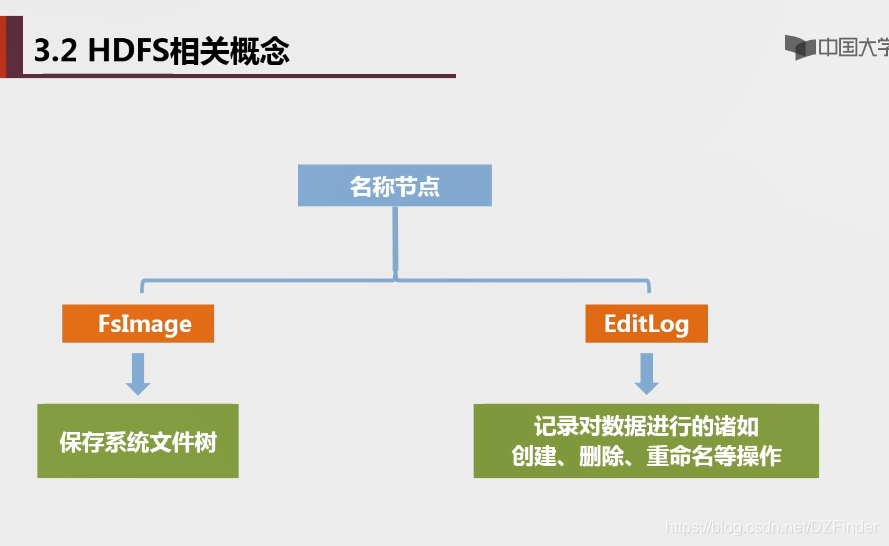
DataNode数据节点作用是保存数据
(二)HDFS存储原理
(1)冗余数据机制,一个数据块会被默认的保存三次,好处:
1、加快数据传输速度
2、很容易检查数据错误
3、保证数据可靠性
冗余备份一旦低于用户的设置量,会立即进行复制来达到用户设置量
(三)数据管理策略
(1)数据存放策略:采用随机算法计算,每个块放置在不同的数据节点(机器)
(2)数据读取策略:1、就近机制,HDFS提供的API来确定一个数据节点所属的机架ID,当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表包含数据节点,用API来确定客户端这些数据节点所属的机架ID,当发现某块数据副本对应的机架ID和客户端对应的机架ID相同时优先选择该副本读取数据,如果没有发现,就随机选取一个副本读取数据。
(3)数据的错误与恢复
1、总管家名称节点出错,先暂停服务,从SecondaryNameNode的冷备份上恢复过来,恢复结束以后再提供对外服务(仅1.0需要停止,2.0版由于有热备份,可以理解恢复服务
2、数据节点出现错误,查错:数据节点每隔一段时间会给名称节点发送心跳信息,当某个发生故障后,名称节点收不到心跳信息,探测到这个数据节点已经不可用,会将它的状态列表的状态标记为宕机,把存储在故障机上的数据,重新复制分发到其他正常的机器上(不仅是故障时调整冗余数据的位置,当负载不均衡时,也能将数据块从负载高的机器调到其他负载低的机器)
3、数据出现错误,客户端读取数据后会对数据进行校验码校验,如果校验码不对,则数据出现错误,再进行恢复和冗余的在此复制
(四)HDFS数据读取过程
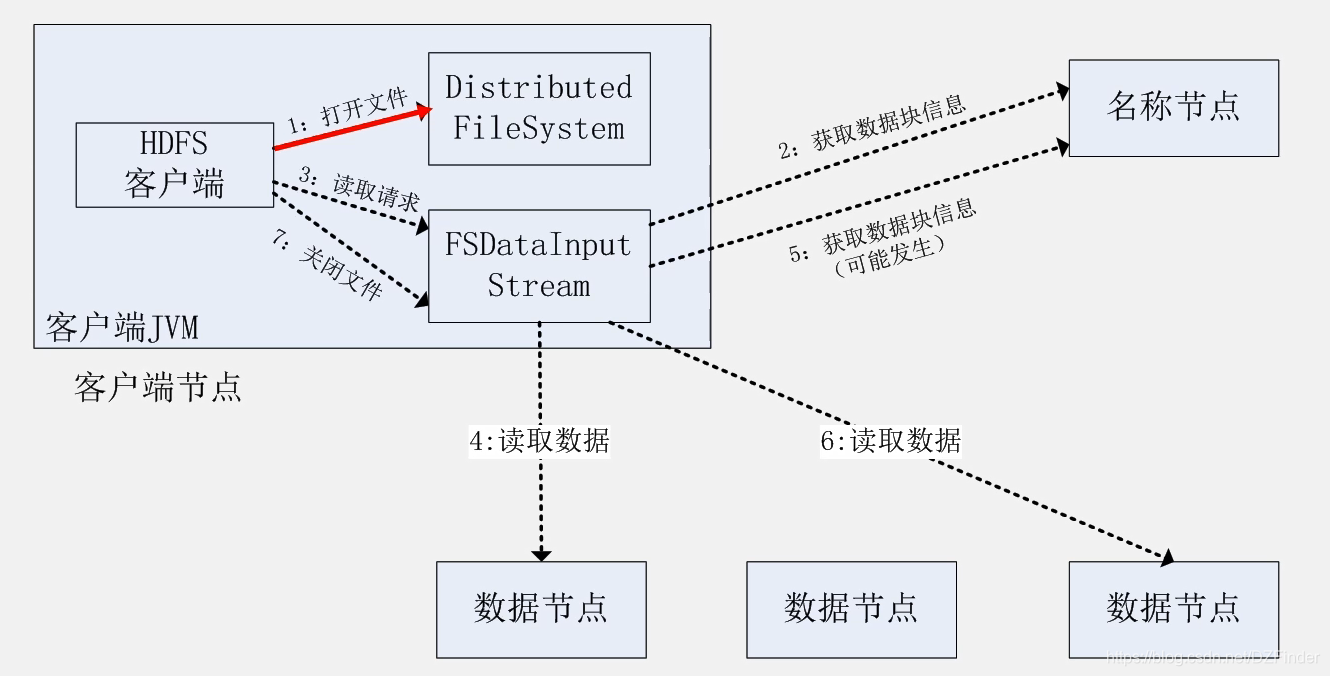
1、打开文件
HDFS客户端打开文件(创建输入流)
2、获取数据块信息
FSD(输入流类型FsDataInputStream)从名称节点获取数据块位置信息,名称节点返回已排序的文件开始的头部信息
3、读取请求
FSD读取客户端请求,选择距离客户端最近的数据节点建立连接
4、读取数据
FSD从数据节点读取数据
5、获取数据块信息(可能发生)
若有剩余信息还未读取完,FSD再从名称节点获取数据块信息,若已完成所有读取则停止获取
6、读取数据
FSD再从数据节点读取数据(3、4、5、6是循环过程,直到读取完所有数据后结束)
7、关闭文件
关闭输入流
(五)HDFS数据写入过程
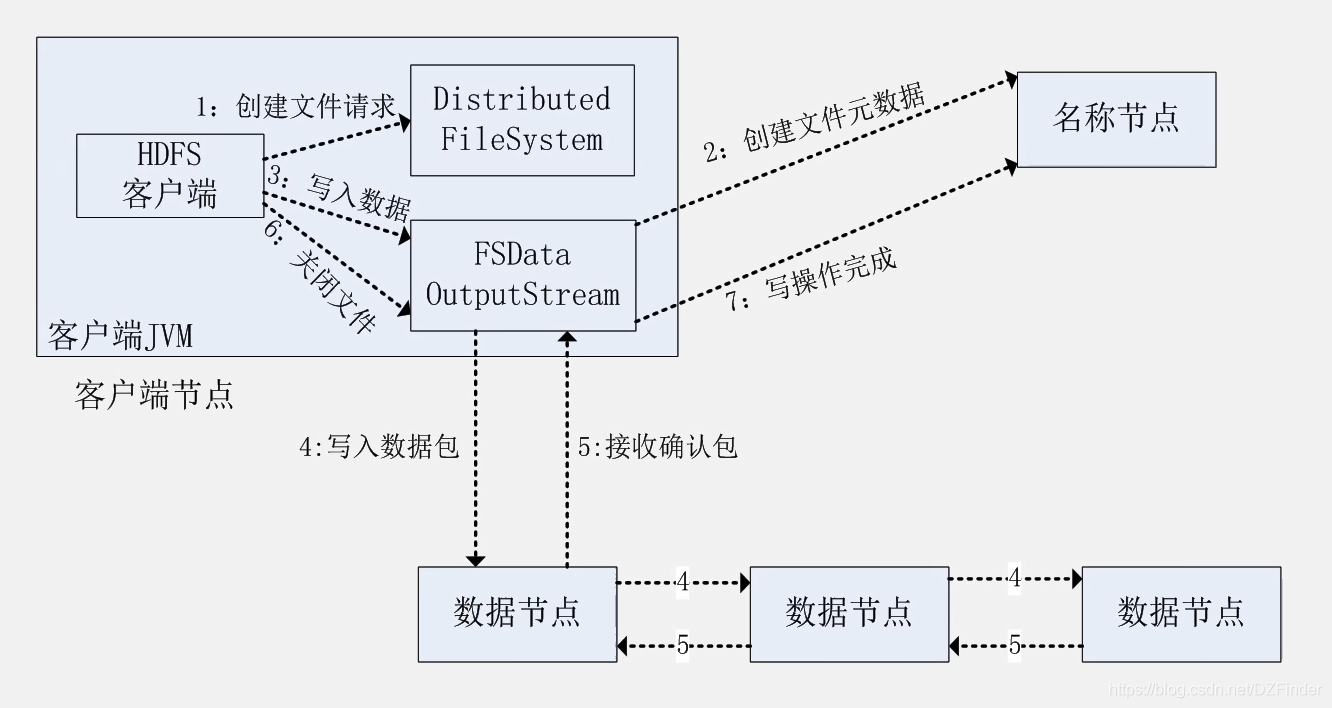
1、创建文件请求
2、创建文件元数据:
FSD询问名称节点,名称节点检查,检查文件是否存在,检查客户端是否有权限创建这个文件
3、写入数据:
通过输出流写数据,把整个数据分成包,放进输出流队列,FSD像名称节点申请位置
4、写入数据包:
摆一个数据保存在多个不同的数据节点,将分包打包成数据包,发送给第一节点,第一节点再发给第二,复制几次发送几次 ,流水线复制
5、接收确认包:
由最后一个数据节点依次接力向前传送接收确认信息,直到第一个数据节点确认所有数据包已接收
6、关闭文件
