版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/yuanyi0501/article/details/83031411
MapReduce运行过程
========
- step1 :
- input
- InputFormat
- 读取数据
- 转换成<key, value>
- FileInputFormat
- TextInputFormat
- InputFormat
- input
- step 2:
- map
- ModuleMapper
- map(KEYIN , VALUEIN, KEYOUT, VALUEOUT)
- 默认情况下——>KEYIN :LongWritable VALUEIN : TEXT
- map
- step 3:
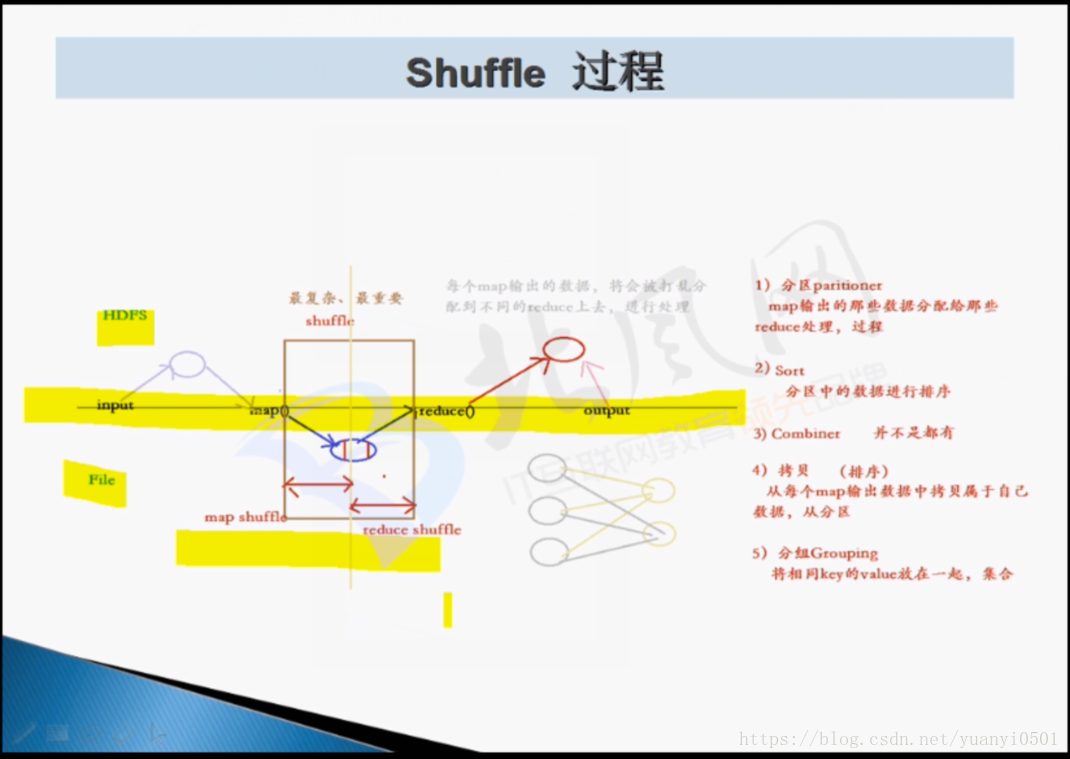
- shuffle
- proceess
- map,output<key, value>
- 输出output一开始放在memory内存缓冲区
- 内存满了之后通过spill,溢写到磁盘中,很多文件。写的过程中有两种操作:
- 分区parttition,基于hash分区
- 排序sort
- 输出之后,磁盘存在很多小文件
- 将小文件合并merge
- 排序
- 形成一个大文件——》在map task运行的机器的本地磁盘
-------------------------------- map结束 ---------------------------------------------
- reduce任务启动,会到map task运行的机器的本地磁盘上,拷贝要处理的数据
- 合并。排序
- 分组group:将相同的key的value放在一起
-MAP-01
<hadoop,1>
——————<hadoop,2>------->combiner在map端合并key
<hadoop,1>
<yarn,1>
<hive,1>
-MAP-02
-MAP-03
-reduce-01
a-zA-Z
- reduce-02
other
总结shuffle过程:
- 分区partition
- 排序sort
- 拷贝copy——用户无法干预
- 分组group
- 压缩compress——可设置
- 合并 combiner map任务端的reduce——可设置
- step 4:
- reduce:
- reduce(KEYIN, VALUEIN,KEYOUT,VALUEOUT)
- map输出的<key, value>数据类型与reduce输入的<key, value>数据类型一致
- reduce:
- step 5:
- output
- OutPutFormat
- FileOutputFormat
- TextOutputFormat
- 每个<key, value>对,输出一行,key和value之间用\t分隔,默认调用key和value的toString()方法
- TextOutputFormat
- output
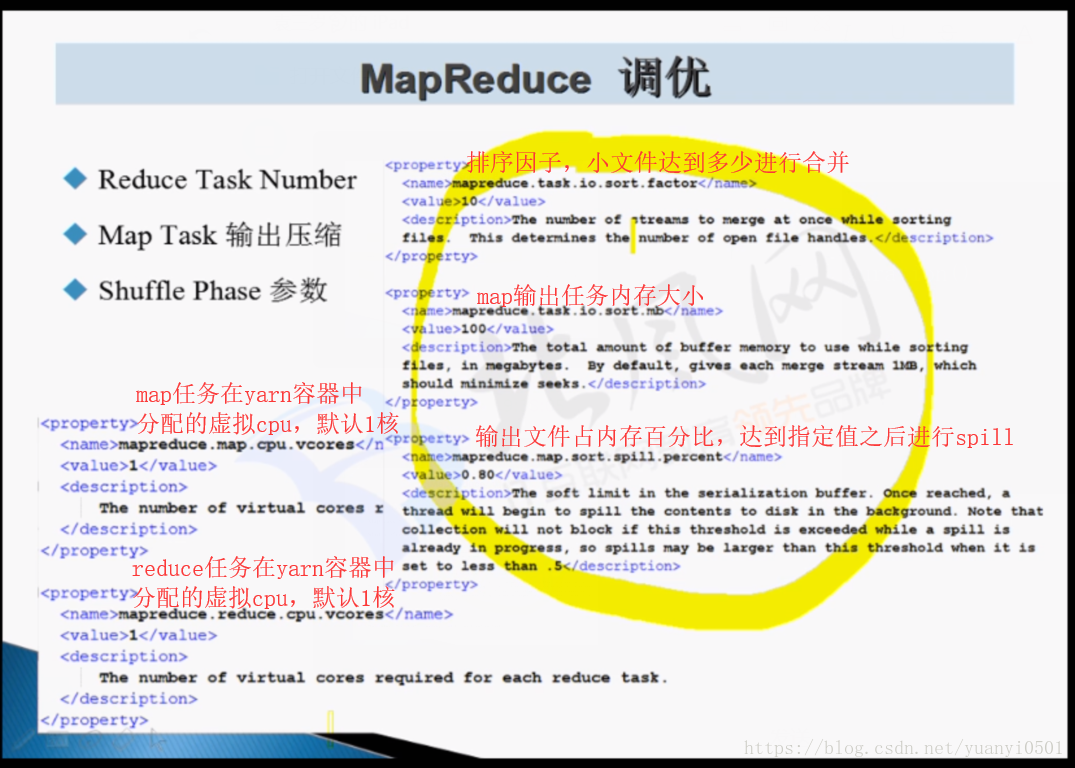
MapReduce调优
- reduce task 数量。设置的两种方法:
- mapreduce.job.reduces
- job.setNumReduceTasks(1);
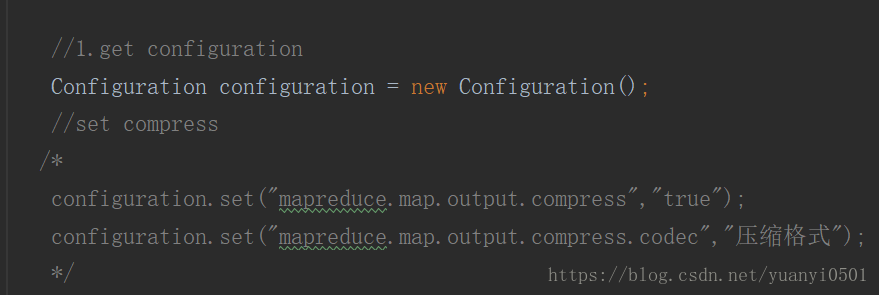
- map task 输出压缩
- shuffle 参数