版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/85599316
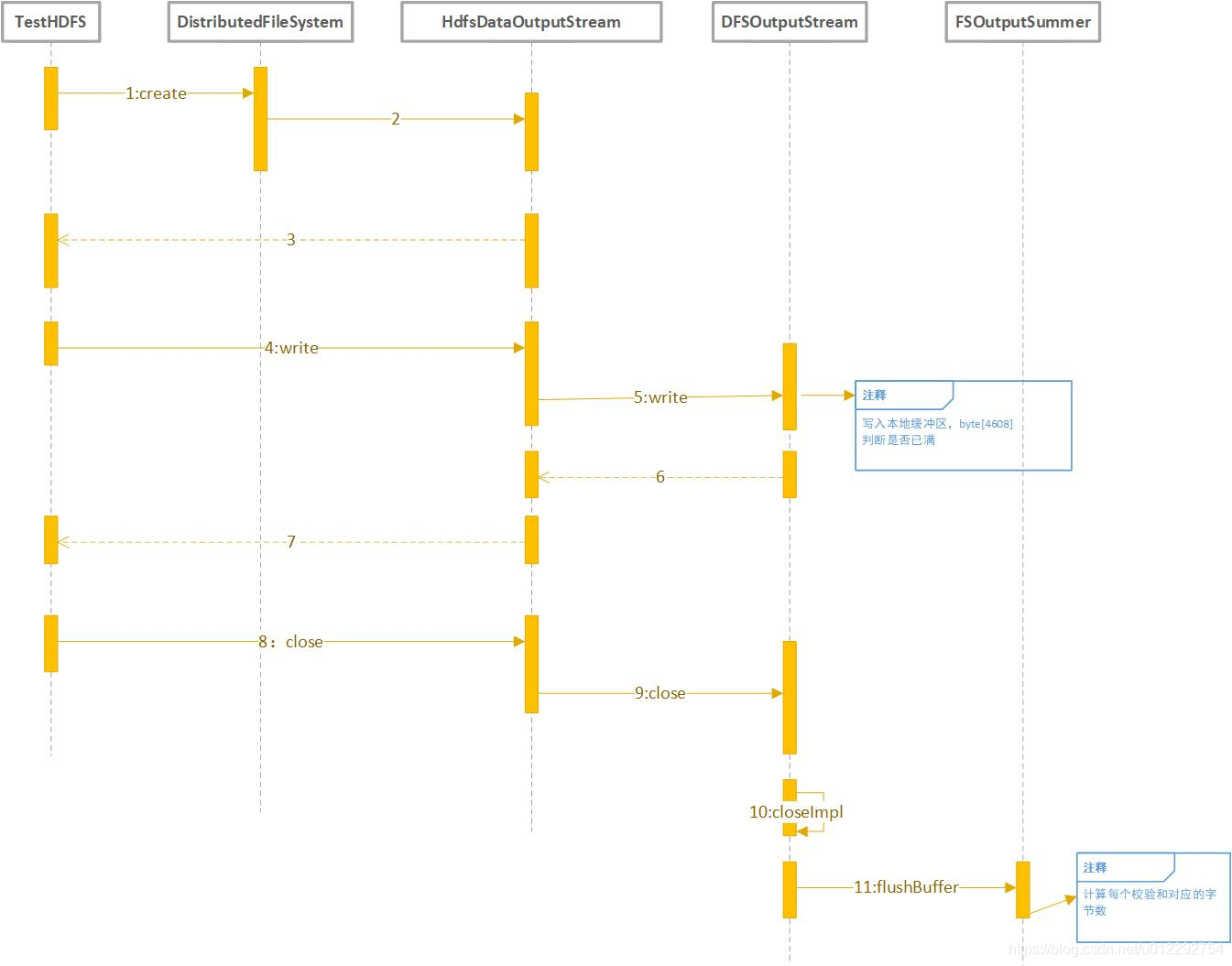
1 HDFS 写入分析
public class TestHDFS {
public void testWrite() throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("/test/a.txt");
FSDataOutputStream fout = fs.create(path);
fout.write("Hello World".getBytes());
fout.close();
}
}
2 MR
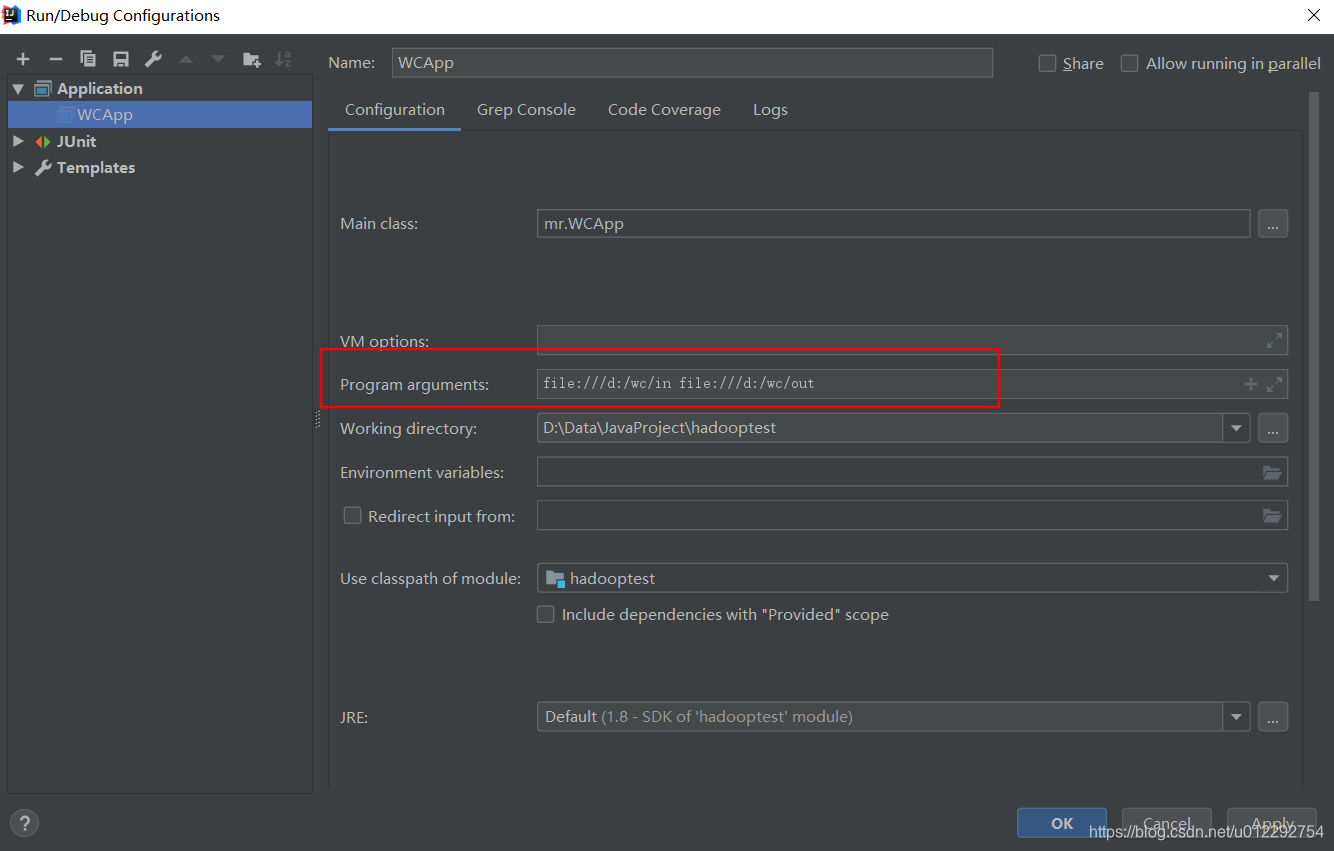
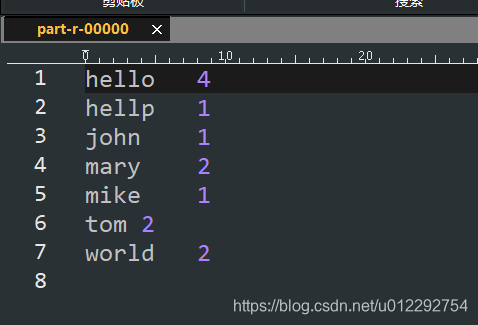
file:///d:/wc
d前面的 / 代表根目录
2.1 单词统计
WCMapper.java
package mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text keyOut = new Text();
IntWritable valueOut = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arr = value.toString().split(" ");
for (String s : arr) {
keyOut.set(s);
valueOut.set(1);
context.write(keyOut,valueOut);
}
}
}
WCReducer.java
package mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable iw : values) {
count = count + iw.get();
}
context.write(key,new IntWritable(count));
}
}
WCApp.java
package mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WCApp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setJobName("WCApp");
job.setJarByClass(WCApp.class);
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WCReducer.class);
job.setNumReduceTasks(1);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(false);
}
}