HDFS文件系统——编辑日志和镜像文件详细介绍
我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Datanode则会保留真实的数据,对于Namenode来说,最重要的两个文件就是Fsimage和Edits了,它们记录了用户的一系列在文件系统中的操作并保存了文件索引
1. 初始化文件系统基本步骤
为了演示这两个文件的详细介绍,我们首先需要格式化文件系统,由于之前搭建了高可用,因此必须严格按照顺序执行命令,具体步骤如下:
1. 关闭所有进程
stop-all.sh
xzk.sh stop
2. 使用xcall命令删除所有节点/home/centos/ha文件夹
xcall.sh rm -rf /home/centos/ha
3. 启动zookeeper,注意zk一定要先启动!!!
xzk.sh start
4. 启动s102-s104节点的journalnode进程
hadoop-daemons.sh start journalnode
5. 在zookeeper上初始化元数据,注意这一步一定要先进行,否则Namenode将会格式化失败!!!
hdfs zkfc -formatZK
6. 格式化HDFS
hdfs namenode -format
7. 将s101上的ha文件夹发送到s105上去
scp -r /home/centos/ha root@s105:/home/centos
8. 启动HDFS文件系统
多次初始化Namenode导致Datanode无法启动问题解决
由于hadoop是通过元数据中VERSION下存有的Cluster ID来标识几个节点是否是同一集群的,因此多次初始化会使得namenode和datanode的clusterID不一致,即不是同一集群,从而导致这个问题,解决方案有两个:
1. 重复上述步骤
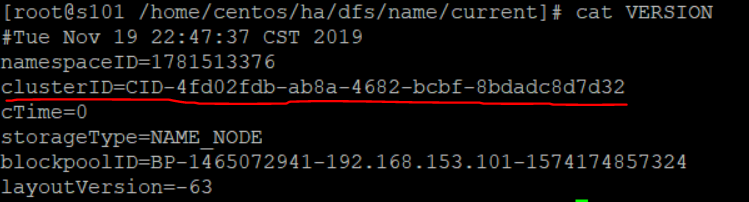
2. 查看主节点的Cluster ID,将这个ID复制到从节点的VERSION文件中去即可,路径为/home/centos/ha/dfs/data/current,查看主节的ID为:
2. 编辑日志和镜像文件详细介绍
我们首先查看一下最原始的Namenode下的文件有哪些:

VERSION文件加载了Cluster ID,seen_txid记录的是transaction id,事务ID,镜像文件后缀序列从0起步,存储真正的索引文件,包括但不限于权限,大小以及文件名,编辑日志即edits_inprogress文件序号从1起步,记录了hadoop从开启到关闭,用户的所有操作
为了探究在进行某步操作时,编辑日志以及镜像文件这两个文件究竟发生了什么样的变化,需要进行测试:
put一个文件到HDFS上去,hdfs dfs -put /root/wc.txt /,第一个实验我们将root家目录下预先放好的名为wc.txt的文件put到HDFS的根目录下
查看current目录下的文件,发现是这样的结构:
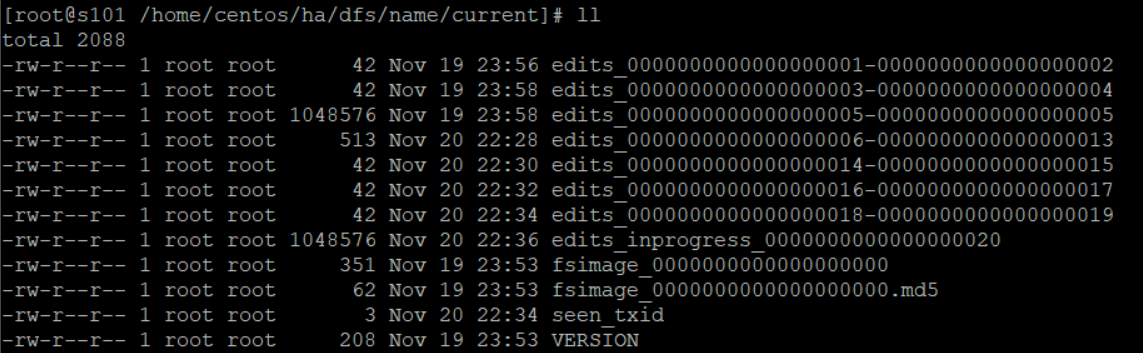
发现出现了类似于edits_0000000000000000001-edits_0000000000000000002这样的文件,后缀总是用两个数字作为编号,而edits_inprogress文件又重新生成了一份,而从目录信息中的时间又可知,编辑日志是每两分钟滚动一次的,每滚动一次就将edits_inprogress文件实例化成edits文件,而同时又新生成一份edits_inprogress文件,后缀的序号是旧的edits文件后缀最大序号加1
那么这个edits文件里面到底是什么内容呢,由于这个文件无法直接cat查看,为了一探究竟,我们使用了hdfs oev -i edits_0000000000000000006-0000000000000000013 -o ~/edits.xml -p xml命令进行查看,得到以下信息:
<?xml version="1.0" encoding="UTF-8"?> <EDITS> <EDITS_VERSION>-63</EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA> <TXID>6</TXID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD</OPCODE> <DATA> <TXID>7</TXID> <LENGTH>0</LENGTH> <INODEID>16386</INODEID> <PATH>/wc.txt._COPYING_</PATH> <REPLICATION>3</REPLICATION> <MTIME>1574260053772</MTIME> <ATIME>1574260053772</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME>DFSClient_NONMAPREDUCE_-929106461_1</CLIENT_NAME> <CLIENT_MACHINE>192.168.153.101</CLIENT_MACHINE> <OVERWRITE>true</OVERWRITE> <PERMISSION_STATUS> <USERNAME>root</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> <RPC_CLIENTID>48f6f0ee-0e35-4b0f-86b1-b2df41b2c4cd</RPC_CLIENTID> <RPC_CALLID>3</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> <DATA> <TXID>8</TXID> <BLOCK_ID>1073741825</BLOCK_ID> </DATA> </RECORD> <RECORD> <OPCODE>OP_SET_GENSTAMP_V2</OPCODE> <DATA> <TXID>9</TXID> <GENSTAMPV2>1001</GENSTAMPV2> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD_BLOCK</OPCODE> <DATA> <TXID>10</TXID> <PATH>/wc.txt._COPYING_</PATH> <BLOCK> <BLOCK_ID>1073741825</BLOCK_ID> <NUM_BYTES>0</NUM_BYTES> <GENSTAMP>1001</GENSTAMP> </BLOCK> <RPC_CLIENTID></RPC_CLIENTID> <RPC_CALLID>-2</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_CLOSE</OPCODE> <DATA> <TXID>11</TXID> <LENGTH>0</LENGTH> <INODEID>0</INODEID> <PATH>/wc.txt._COPYING_</PATH> <REPLICATION>3</REPLICATION> <MTIME>1574260055275</MTIME> <ATIME>1574260053772</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME></CLIENT_NAME> <CLIENT_MACHINE></CLIENT_MACHINE> <OVERWRITE>false</OVERWRITE> <BLOCK> <BLOCK_ID>1073741825</BLOCK_ID> <NUM_BYTES>75</NUM_BYTES> <GENSTAMP>1001</GENSTAMP> </BLOCK> <PERMISSION_STATUS> <USERNAME>root</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> </DATA> </RECORD> <RECORD> <OPCODE>OP_RENAME_OLD</OPCODE> <DATA> <TXID>12</TXID> <LENGTH>0</LENGTH> <SRC>/wc.txt._COPYING_</SRC> <DST>/wc.txt</DST> <TIMESTAMP>1574260055288</TIMESTAMP> <RPC_CLIENTID>48f6f0ee-0e35-4b0f-86b1-b2df41b2c4cd</RPC_CLIENTID> <RPC_CALLID>9</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_END_LOG_SEGMENT</OPCODE> <DATA> <TXID>13</TXID> </DATA> </RECORD> </EDITS>
原来,简简单单一个put操作竟分成了那么多个操作步骤,仔细查看,可知,一共分成了,
OP_START_LOG_SEGMENT OP_ADD OP_ALLOCATE_BLOCK_ID OP_SET_GENSTAMP_V2 OP_ADD_BLOCK OP_CLOSE OP_RENAME_OLD
这7个步骤,在最后一个步骤中将之前的._COPYING_后缀去掉,正式重命名为原文件名,而每增添一个操作步骤,事务ID即TXID就会自增1,难怪我们在current目录下发现了edits_0000000000000000006-0000000000000000013这个文件,原来这两个数字就是事务ID的开始和结束编号!!!
我们查看了Edits文件,现在再来看一下fsimage文件是怎样的:
<?xml version="1.0"?> <fsimage> <NameSection> <genstampV1>1000</genstampV1> <genstampV2>1002</genstampV2> <genstampV1Limit>0</genstampV1Limit> <lastAllocatedBlockId>1073741826</lastAllocatedBlockId> <txid>41</txid> </NameSection> <INodeSection> <lastInodeId>16387</lastInodeId> <inode> <id>16385</id> <type>DIRECTORY</type> <name></name> <mtime>1574261024683</mtime> <permission>root:supergroup:rwxr-xr-x</permission> <nsquota>9223372036854775807</nsquota> <dsquota>-1</dsquota> </inode> <inode> <id>16387</id> <type>FILE</type> <name>wc.txt</name> <replication>3</replication> <mtime>1574261024676</mtime> <atime>1574261024495</atime> <perferredBlockSize>134217728</perferredBlockSize> <permission>root:supergroup:rw-r--r--</permission> <blocks> <block> <id>1073741826</id> <genstamp>1002</genstamp> <numBytes>75</numBytes> </block> </blocks> </inode> </INodeSection> <INodeReferenceSection></INodeReferenceSection> <SnapshotSection> <snapshotCounter>0</snapshotCounter> </SnapshotSection> <INodeDirectorySection> <directory> <parent>16385</parent> <inode>16387</inode> </directory> </INodeDirectorySection> <FileUnderConstructionSection></FileUnderConstructionSection> <SnapshotDiffSection> <diff> <inodeid>16385</inodeid> </diff> </SnapshotDiffSection> <SecretManagerSection> <currentId>0</currentId> <tokenSequenceNumber>0</tokenSequenceNumber> </SecretManagerSection> <CacheManagerSection> <nextDirectiveId>1</nextDirectiveId> </CacheManagerSection> </fsimage>
我们可以发现,镜像文件fsimage实际上就是记录了整个HDFS文件系统的树形结构,比如父目录是什么,子文件是什么它们的用户是谁,权限是什么,在什么时候创建的等等详细信息,也就是真正的索引文件
2.1 HDFS启动过程详解
1. 加载镜像文件
将镜像文件中存储的索引信息载入到内存

2. 加载编辑日志
将edits_inprogress文件实例化为edits文件(hdfs dfsadmin -rollEdits),创建新的edits_inprogress文件
3. 保存检查点,更新镜像文件
将旧的镜像文件,执行新的edits文件的操作步骤,生成新的镜像文件到磁盘
4. 进入到安全模式
以上三个步骤操作时,集群会处于仅可读的状态,此状态被称为安全模式
![]()
5. datanode报告信息
启动之后,datanode会每隔三秒钟向namenode发送ping信息,证明自己还活着,因此,查看这一页面,如果发现Last contact的秒数大于3,就说明某一Datanode已经死亡

2.2 Secondarynamenode(辅助名称节点)讲解
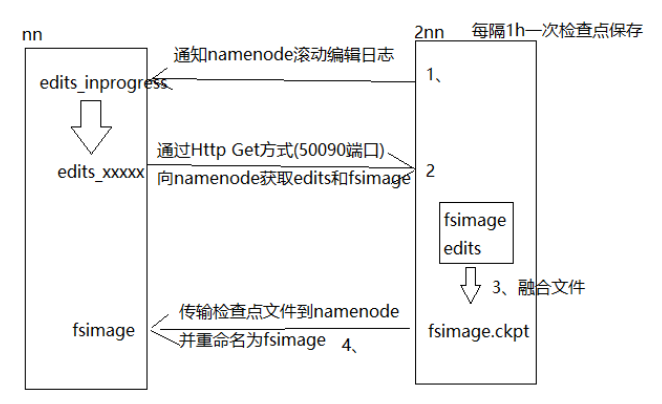
之前提到,由于在进行编辑日志和镜像文件融合的过程中会进入到Safe mode,这个动作进行的频率是每一小时一次,而一旦进入到安全模式用户是没办法进行任何操作的,因此会造成麻烦,于是引入辅助名称节点的概念,相当于edit继续记录,但是合并的过程给到Secondarynamenode去做了,合并过程不需要进入到safe mode,其实就是为了在合并的时候仍然可以对用户提供服务;另一个好处就是Secondarynamenode相当于是对主节点做了一个备份,保证了一个安全性,具体工作流程见下图:
2.3 手动操作编辑日志和镜像文件的方法
手动滚动编辑日志:
hdfs dfsadmin -rollEdits
手动融合镜像文件:
需要首先进入安全模式
hdfs dfsadmin -safemode enter
融合过程也会触发重新滚动编辑日志的操作
hdfs dfsadmin -saveNamespace
离开安全模式
hdfs dfsadmin -safemode leave