Adaptive Affinity Fields for Semantic Segmentation
本文没有提出新的框架,主要工作是提出了新的学习思路和loss:Affinity及AAF。
目前的问题:
目前,在语义分割的任务中,当有较大的训练数据和更深入、更复杂的网络架构,基于像素的分类方法在前景像素和背景像素接近或混合在一起时,从根本上缺乏空间分辩能力,即当前景的视觉证据较弱时,分割效果较差。
随着越来越强大的像素分类器和通过条件随机域(CRF)或生成对抗网络(GAN)合并结构先验,语义分割已经取得了很大的进展。
CRF通过视觉外观的相似性(如原始像素值)来衡量像素之间的标签一致性。通过消息传递算法求解最优标记。CRF可以作为后处理步骤,也可以作为深度神经网络中的插件模块。除了耗时的迭代推理程序外,CRF对视觉外观变化也很敏感。
GAN是最近在神经网络输出中加入结构规则的一种替代方法。具体来说,通过一个鉴别器网络测试预测的标签映射是否与训练集中的真值标签映射相似。GAN是出了名的难训练,尤其容易出现模型不稳定和模式崩溃的情况。
相关工作:
我们提出了一种更简单的方法,只在训练时学习了语义分割的空间结构。我们提出了自适应亲和域(AAF)的概念来捕获和匹配标签空间中相邻像素之间的关系,而不是使用CRF或GAN在单个像素上强制使用语义标签和在相邻像素之间匹配标签。
本文中提出的AAF和CRF以及GAN进行比较,数据集选用Cityscapes,评价标准为mIOU:

AAF有3个显著的优点:1,有通用的表示方式;2,比GAN更易训练,比CRF效率更高,3,更适用于可视化域更改
AAF:
Method overview:

学习自适应亲和力场的语义分割。自适应亲和域由两部分组成:具有多个核大小的亲和域损失和相应的分类对抗性权重。注意,自适应亲和域只在训练过程中引入,推理过程中没有额外的计算。
1.From Pixel-wise Supervision to Region-wise Supervision(从像素监督到区域监督)
Pixel-wise交叉熵损失:
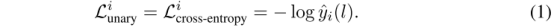
然而,这种一元损失没有考虑语义标签的相关性和场景结构。不同类别的对象以某种模式相互作用。例如,汽车通常在路上,而行人在人行道上;建筑物被天空包围,但从不在天空之上。此外,某些特定类别的形状出现得更频繁,如火车上的矩形、自行车上的圆圈和杆子上的直线。这种类间和类内像素关系是信息的,可以作为结构推理集成到学习中。因此,我们提出了一个额外的区域损失来惩罚不一致的一元预测,并鼓励网络学习这种内在的像素关系。
Region-wise损失:

其中,N(·)表示邻域,n是像素的总数,y^表示预测值,y表示ground-truth
2.Affinity Field Loss Function(亲和场损失函数)
如果像素i和它的邻居j有相同的分类标签,我们施加一个分组力,鼓励在i和j处的网络预测相似。否则,我们施加一个分离力,把它们的标签预测分开,如下图(个人认为这个图不严谨,在训练阶段的学习过程中,由于每一层feature map都只是对一个类别进行比对,每个像素点的概率是对该类别进行判断的概率,然后调整阈值进行二分类任务,再根据ground-truth学习正确的像素点分布):

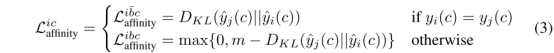
其中,KL散度为:
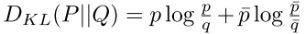
Y^j( c )表示类c中j的预测概率,其余同理,可以看到Affinity Field Loss Function鼓励对相同的ground-truth标签的两个像素进行类似的网络预测,而不管它们的实际标签是什么;同时,会使网络预测在两个不同的ground-truth标签像素上产生偏差,而不管它们的实际标签是什么。这种成对排斥的集合有助于创建清晰的分割边界。
3.Adaptive Kernel Sizes from Adversarial Learning(对抗性学习的自适应内核尺寸)
对于固定的核尺寸训练得到的网络误差较大,本文提出的内核尺寸自适应可以使得每个类别的理想内核大小都随平均对象大小和对象形状复杂性而变化。本文提出了一个自适应大小的亲和域损失函数,优化了循环中每个类别的亲和域大小的权重:
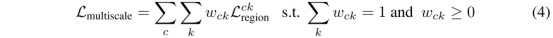
在内核大小为k*k的特定类通道c上使用相应的加权Wck进行操作。
本文将自适应内核大小选择过程描述为优化一个二人极小极大博弈:当分段器总是试图最小化总损失时,不同内核大小在损失中的权重应该试图最大化总损失,以获取最关键的邻域大小。在形式上,有:
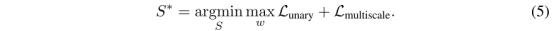

成果:
在PASCALVOC 2012数据集上,以mIOU为评价标准,得出的结果(灰色背景表示使用FCN作为基础架构):

其中:
GAN loss为:
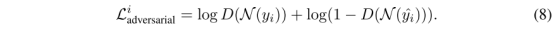
Pixel Embedding loss为contrastive loss:

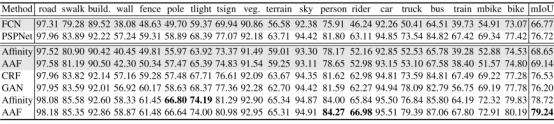
在Cityscapes数据集上,以mIOU为评价标准,得出的结果(灰色背景表示使用FCN作为基础架构):
在GTA5 Part 1数据集上,以mIOU为评价标准,得出的结果:

Boundary-level Evaluation:

自适应亲和域kernel size分析:

下图中,左:PASCALVOC 2012验证集上各类别边缘项在AAF中不同核大小的最优权重。右:有效接受域大小相关的图像斑块可视化,提示核大小如何捕捉不同类别关键区域的形状复杂性。(其中,左图个人的理解是将3×3、5×5、7×7在每一层feature map都跑一遍,然后乘以不同的权重,其中左图不同类别的不同权重比例就是本框架在特定数据集学习后的结果,可以理解为该类别在此数据集下的不同尺寸大小的图片的数量比例)

分别在PASCAL VOC 2012(前4行)、Cityscapes(第5行)、GTA5(后两行)数据集上进行测试:

