Segmenter: Transformer for Semantic Segmentation
https://arxiv.org/pdf/2105.05633.pdf
https://github.com/rstrudel/segmenter
![]()

Figure 1: Our approach for semantic segmentation is purely transformer based. It leverages the global image context at every layer of the model. Attention maps from the first Segmenter layer are displayed for three 8×8 patches and highlight the early grouping of patches into semantically meaningful categories. The original image (top-left) is overlayed with segmentation masks produced by our method.
Abstract
Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus.
In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution-based methods, our approach allows to model global context already at the first layer and throughout the network. We build on the recent Vision Transformer (ViT) and extend it to semantic segmentation.
To do so, we rely on the output embeddings corresponding to image patches and obtain class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. We leverage models pre-trained for image classification and show that we can fine-tune them on moderate sized datasets available for semantic segmentation. The linear decoder allows to obtain excellent results already, but the performance can be further improved by a mask transformer generating class masks.
We conduct an extensive ablation study to show the impact of the different parameters, in particular the performance is better for large models and small patch sizes. Segmenter attains excellent results for semantic segmentation. It outperforms the state of the art on the challenging ADE20K dataset and performs on-par on Pascal Context and Cityscapes.
话题引入:图像分割往往在图像 patch 的级别上模棱两可,并需要上下文信息达成标签一致。本文介绍了一种用于语义分割的 transformer 模型——Segmenter。
算法特点:与基于卷积的方法相比,本文的方法允许在第一层和整个网络中建模全局上下文。以最近的 ViT 为基础,并将其扩展到语义分割。为此,本文依赖于与图像 patch 对应的输出嵌入,并使用逐点线性解码器(point-wise linear decoder)或一个 mask transformer 解码器从这些嵌入中获得类标签。本文利用了用于图像分类的预训练模型,并表明本文的模型可以在用于语义分割的中等规模数据集上微调它们。线性解码器已经可以获得优秀的结果,但性能可以由 mask transformer 产生类掩模进一步提高。
实验结果:广泛的消融研究了不同参数的影响,特别是性能更好的大模型和小 patch 尺寸。分割器获得了良好的语义分割效果。它在具有挑战性的 ADE20K 数据集上的性能优于现有水平,在Pascal Context 和 Cityscapes 上的性能与现有水平相当。
Introduction
Recent approaches to semantic segmentation typically rely on convolutional encoder-decoder architectures where the encoder generates low-resolution image features and the decoder upsamples features to segmentation maps with perpixel class scores. State-of-the-art methods deploy Fully Convolutional Networks (FCN) [42] and achieve impressive results on challenging segmentation benchmarks [9, 21, 53, 54, 56, 58, 61]. These methods rely on learnable stacked convolutions that can capture semantically rich information and have been highly successful in computer vision. The local nature of convolutional filters, however, limits the access to the global information in the image. Meanwhile, such information is particularly important for segmentation where the labeling of local patches often depends on the global image context. To circumvent this issue, DeepLab methods [7, 8, 9] introduce feature aggregation with dilated convolutions and spatial pyramid pooling. This allows to enlarge the receptive fields of convolutional networks and to obtain multi-scale features.
Following recent progresses in NLP [47], several segmentation methods explore alternative aggregation schemes based on channel or spatial [20, 21, 57] attention and point-wise [61] attention to better capture contextual information.
Such methods, however, still rely on convolutional backbones and are, hence, biased towards local interactions. An extensive use of specialised layers to remedy this bias [7, 9, 20, 54] suggests limitations of convolutional architectures for segmentation.
目前研究现状:
最近的语义分割方法通常依赖于卷积编码器-解码器架构,其中编码器生成低分辨率图像特征,解码器对特征进行采样,以逐像素类分数分割地图。最先进的方法部署了全卷积网络 (FCN),并取得很好的结果。这些方法依赖于可学习的堆叠卷积,可以捕获语义丰富的信息。然而,卷积滤波器的局部特性限制了对图像中全局信息的访问。同时,这些信息对于分割尤为重要,局部 patches 的标记往往依赖于全局图像上下文。为了规避这个问题,DeepLab 引入了膨胀卷积的特征聚合和空间金字塔池。这样可以扩大卷积网络的接收域,获得多尺度特征。
随着自然语言处理的最新进展,一些分割方法探索了基于通道或空间注意和点方向注意的替代聚合方案,以更好地捕获上下文信息。
不足:然而,这样的方法仍然依赖于卷积 backbone,因此偏向于局部交互。广泛使用专门的层来纠正这种偏差,表明了卷积结构在分割方面的局限性。
To overcome these limitations, we formulate the problem of semantic segmentation as a sequence-to-sequence problem and use a transformer architecture [47] to leverage contextual information at every stage of the model. By design, transformers can capture global interactions between elements of a scene and have no built-in inductive prior, see Figure 1. However, the modeling of global interactions comes at a quadratic cost which makes such methods prohibitively expensive when applied to raw image pixels [10]. Following the recent work on Vision Transformers (ViT) [17, 46], we split the image into patches and treat linear patch embeddings as input tokens for the transformer encoder. The contextualized sequence of tokens produced by the encoder is then upsampled by a transformer decoder to per-pixel class scores. For decoding, we consider either a simple point-wise linear mapping of patch embeddings to class scores or a transformer-based decoding scheme where learnable class embeddings are processed jointly with patch tokens to generate class masks.
We conduct an extensive study of transformers for segmentation by ablating model regularization, model size, input patch size and its trade-off between accuracy and performance. Our Segmenter approach attains excellent results while remaining simple, flexible and fast. In particular, when using large models with small input patch size the best model reaches a mean IoU of 50.77% on ADE20K, surpassing all previous state-of-the-art convolutional approaches by a large margin of 4.6%. Such improvement partly stems from the global context captured by our method at every stage of the model as highlighted in Figure 1.
算法介绍和结论:
为了克服这些限制,本文将语义分割问题定义为序列到序列问题,并使用 transformer 架构在模型的每个阶段利用上下文信息。根据设计,transformer 可以捕获场景元素之间的全局交互,并且没有内置的感应先验,见图 1。然而,全局交互的建模需要二次方成本,这使得这些方法在应用于原始图像像素时非常昂贵。
继 Vision Transformers (ViT) 的最新研究之后,将图像分割成小块,并将线性小块嵌入作为 Transformers 编码器的输入 tokens。然后由 transformer 解码器将编码器产生的上下文化 tokens 序列上采样为逐像素类分数。对于解码,本文考虑一个简单的逐点线性映射的 patch 嵌入到类分数,或者一个基于 transformer 的解码方案,其中可学习的类嵌入与 patch tokens 一起处理以生成类 mask。本文进行了广泛的研究 transformer 分割烧蚀模型正则化,模型大小,输入 patch 大小和它的精度和性能之间的权衡。
Method
Segmenter is based on a fully transformer-based encoder-decoder architecture mapping a sequence of patch embeddings to pixel-level class annotations. An overview of the model is shown in Figure 2. The sequence of patches is encoded by a transformer encoder described in Section 3.1 and decoded by either a point-wise linear mapping or a mask transformer described in Section B. Our model is trained end-to-end with a per-pixel cross-entropy loss. At inference time, argmax is applied after upsampling to obtain a single class per pixel.
整体介绍:
Segmenter 基于一个完全基于转换器的编码器-解码器架构,它将一系列 patch 嵌入映射到像素级的类注释。模型的概览如图 2 所示。patch 序列由第 3.1 节中描述的变压器编码器编码,并由第 B 节中描述的逐点线性映射或 mask Transformer 解码。本文的模型采用逐像素交叉熵损失的端到端训练。在推理时,上采样后应用 argmax,获得每个像素单类。

Encoder
- embedding
An image
is split into a sequence of patches
where (P, P) is the patch size, N = HW/P^2 is the number of patches and C is the number of channels. Each patch is flattened into a 1D vector and then linearly projected to a patch embedding to produce a sequence of patch embeddings
where
. To capture positional information, learnable position embeddings
are added to the sequence of patches to get the resulting input sequence of tokens
.
内容 embedding:首先,输入的 x 分解为 ![]() ,然后每个 patch 拉伸成 1D 向量
,然后每个 patch 拉伸成 1D 向量 ,最后通过线性变换到为 embedding
(
![]() 表示线性变换从 P^2C 维到 D 维)。
表示线性变换从 P^2C 维到 D 维)。
位置 embedding:![]()
最终 embedding:![]()
- transformer encoder
A transformer encoder composed of L layers is applied to the sequence of tokens z_0 to generate a sequence of contextualized encodings
. A transformer layer consists of a multi-headed self-attention (MSA) block followed by a point-wise MLP block of two layers with layer norm (LN) applied before every block and residual connections added after every block:
where i ∈ {1, ..., L}.

共 L 层 transformer encoder;
每层包括 1 个 MSA block,1 个 point-wise MLP block (每个 block 包括两层);
每个 block 之前是 LN 层;
每个 block 之后都用 残差连接 连接输出与输入。
- self-attention
The self-attention mechanism is composed of three point-wise linear layers mapping tokens to intermediate representations, queries
, keys
and values
. Self-attention is then computed as follows
The transformer encoder maps the input sequence z0 =
of embedded patches with position encoding to
, a contextualized encoding sequence containing rich semantic information used by the decoder.

不多说了,就是普通的 self-attention。
最后这段讲了下输出,用以引出下文,文章逻辑上的连贯。
Decoder
The sequence of patch encodings
is decoded to a segmentation map
where K is the number of classes. The decoder learns to map patch-level encodings coming from the encoder to patch-level class scores. Next these patch-level class scores are upsampled by bilinear interpolation to pixel-level scores. We describe in the following a linear decoder, which serves as a baseline, and our approach, a mask transformer, see Figure 2.
patch 编码序列 ![]() 被解码为分割映射
被解码为分割映射 ![]() ,其中 K 为类的数量。解码器学习将来自编码器的 patch-level 编码映射到 patch-level 类分数。接下来,这些 patch-level 的类分数通过双线性插值到像素级分数上采样。下面描述了作为 baseline 的线性解码器和 mask transformer,见图2。
,其中 K 为类的数量。解码器学习将来自编码器的 patch-level 编码映射到 patch-level 类分数。接下来,这些 patch-level 的类分数通过双线性插值到像素级分数上采样。下面描述了作为 baseline 的线性解码器和 mask transformer,见图2。
- Linear
A point-wise linear layer is applied to the patch encodings
to produce patch-level class logits
. The sequence is then reshaped into a 2D segmentation map
and bilinearly upsampled to the original image size to obtain the final segmentation map
输入的 ![]() 首先经过 point-wise linear layer 变换到
首先经过 point-wise linear layer 变换到 ![]() ;
;
![]() reshape 到
reshape 到 ![]() ;
;
![]() 再经过双线性上采样到原图像尺寸,得到最后的分割图像
再经过双线性上采样到原图像尺寸,得到最后的分割图像 ![]() 。
。
- Mask Transformer
For the transformer-based decoder, we introduce a set of K learnable class embeddings cls =
where K is the number of classes. Each class embedding is initialized randomly and assigned to a single semantic class. It will be used to generate the class mask. The class embeddings cls are processed jointly with patch encodings z_L by the decoder as depicted in Figure 2.
class embedding:
class embedding ![]() 随机初始化;
随机初始化;
同 patch encodings ![]() 一起处理。
一起处理。
The decoder is a transformer encoder composed of M layers. Our mask transformer generates K masks by computing the scalar product between patch embeddings
and class embeddings
output by the decoder. The set of class masks is computed as follows
where the softmax is applied over the class dimension. m =
is a set of patch sequences, for instance
denotes the probability that patch i belongs to class j. The mask sequences are softly exclusive to each other i.e.
for all
. Each mask sequence is then reshaped into a 2D mask to form
and bilinearly upsampled to the original image size to obtain the final segmentation map
. To enhance decoding and perform finegrained segmentation, the patch encodings
are bilinearly upsampled by a factor of two before being passed through the decoder
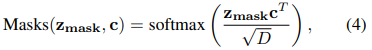
transformer encoder:
M 层;
mask transformer 通过计算 patch embeddings ![]() 和 class embeddings
和 class embeddings ![]() 的标量乘积 (公式 4),生成 K 个 mask 图;
的标量乘积 (公式 4),生成 K 个 mask 图;
第 i 个 mask 图表示的是在该类别上,像素点属于这个第 i 类事物的概率;
mask sequence 进一步 reshaped 到 2 维 ![]() ;
;
再经过 bilinearly upsampled 得到最终分割图像 ![]() 。
。