语义分割
PAN Pyramid Attention Network for Semantic Segmentation
FCN作为backbone的结构对小型目标预测不佳,论文认为这存在两个挑战。
- 物体因为多尺度的原因,造成难以分类。针对这个问题,PSPNet和DeepLab引入了PSP和ASPP模块引入多尺度信息。论文引入了像素级注意力用于帮助提取精准的high-level 特征。
- **high-level的特征偏向于对类别分类,缺乏空间信息.**针对这个问题,常见的操作是采用U-shape结构网络,例如SegNet、Refinenet等。使用low-level帮助high-level恢复图片细节。然后这些都是很耗时的,论文提出了有效的decoder结构,称之为Global Attention Upsample(GAU),可以提取high-level的全局上下文用于对low-level信息加权。
Contributuions
- 提出了Feature Pyramid Attention module(FPA)将不同尺度上下文特征嵌入到现存的FCN结构上
- 提出了Global Attention Upsample(GAU),一个有效的decoder模块
- 基于FPA和GAU,提出了Pyramid Attention Network(PAN)网络,在VOC2012 and cityscapes上获得了先进表现
Feature Pyramid Attention
PSPNet和DeepLab使用的PSP或ASPP结构结构如下:

PSPNet使用池化操作会有空间信息上的损失。DeepLab使用扩张卷积会存在缺少局部信息和”griding”(卷积核退化)现象。
受到注意力机制的启发,论文认为可使用注意力机制,将全局上下文信息作为先验知识引入到通道选择。但是仅仅有通道注意力机制是不够的,这依旧缺乏逐像素信息。论文提出了FPA模块,该模块融合了多尺度信息,以3×3,5×5,7×7三个卷积做金字塔结构,因为high-level的特征分辨率较小,故使用大的卷积核带来的计算负担不会太多。同时论文引入了全局池化分支用于进一步提升性能。如图所示:
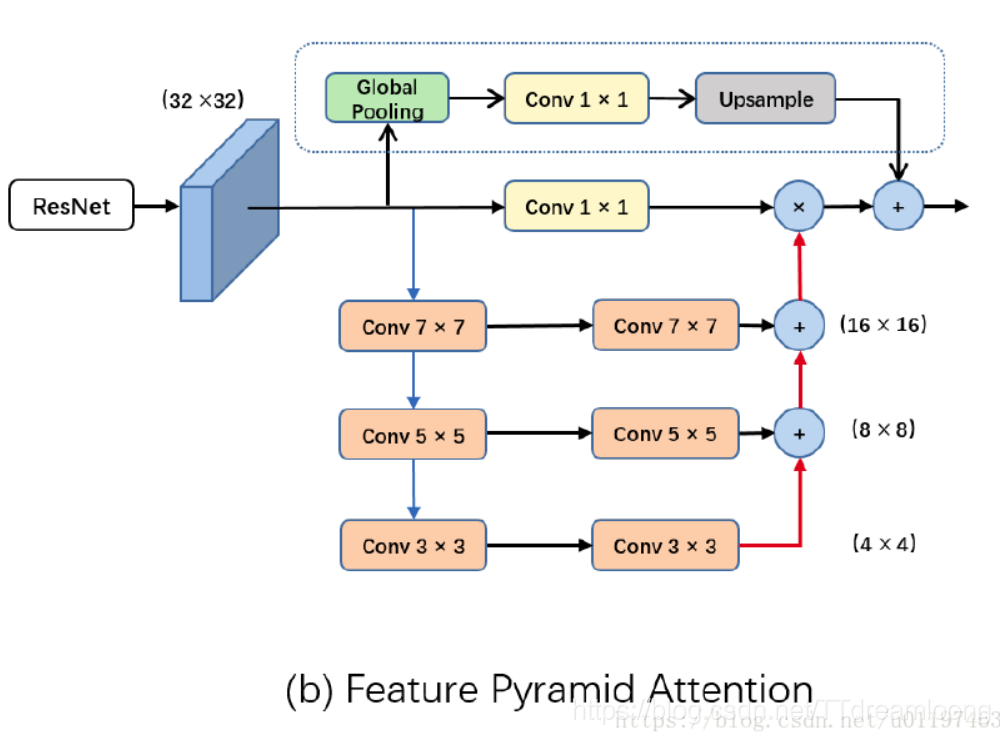
得益于金字塔结构,FPA可以融合多尺度信息,产生更佳的像素级注意力应用于high-level特征。不同于PSPNet或ASPP需要做通道降维,论文的做法是上下文信息与原始的特征做逐像素乘。
Global Attention Upsample
现存的decoder结构上,如PSPNet和Deeplab都是直接双线性差值上采样得到预测结果,这可以看成是一个naive decoder。
DUC使用了多通道做reshape操作得到预测结果。这两类都缺乏多尺度信息,难以恢复空间信息。常见的encoder-decoder架构主要考虑使用使用多尺度信息逐步恢复边界,但是这些结构都较为复杂,带了较大的计算消耗。
因为high-level中有着丰富的语义信息,这可以帮助引导low-level的选择,从而达到选择更为精准的分辨率信息。论文提出了GAU结构,通过全局池化提供的全局信息作为指引选择low-level特征。其结构如下:

具体来讲,使用3×3卷积用于对低级特征做通道处理,然后使用全局池化后的信息做加权,得到加权后的low-level特征,再上采样,然后再与high-level信息相加。
Network Architecture
基于PFA和GAU, 论文提出了完整的PAN架构.

使用带有扩张卷积策略的Resnet101作为backbone,res5b使用dialted rate=2,最初的7×7卷积换成了3个3×3卷积。使用FPA模块去获取密集的像素级注意力信息,结合全局上下文,通过GAU模块最终产生了预测图。
本文来自 DFann 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/u011974639/article/details/82222866?utm_source=copy
Understanding Convolution for Semantic Segmentation
Abstract
本文介绍了两种操控卷积相关运算(convolution-related operations)方法用于提高语义分割效果:
- 设计密集上采样卷积(dense upsampling convolution,DUC)生成预测结果,这可以捕获在双线性上采样过程中丢失的细节信息。
- 设计混合空洞卷积框架(hybrid dilated convolution,HDC),用于减轻扩张卷积产生的”gidding issue”影响,扩大接收野聚合全局信息。
Introduction
大部分应用在语义分割任务上的CNN系统可分为三类:
- **全卷积神经网络。**例如FCN. 使用卷积层代替FC层,提高训练和推断效率,并可接收任意大小输入;
- 使用CRF. 结构预测用于捕获图片内的本地和长距离依赖,用于细化分割结果;
- **使用空洞卷积。**增加中间featue map的分辨率,可在保持相同计算成本的同时提高预测精度。
大部分提高预测准确率的系统可分为两类:
- **使用更优秀的特征提取模型。**即使用VGG16、ResNet等预训练架构。这些更深的模型可对更复杂的信息建模,学习更有区分力的feature并可更好的区分类别。
- **使用CRF作为后端处理,**集成CRF到模型内构成end2end训练,并将额外的信息例如边缘合并到CRF内。
本文以另一个角度来提升性能,考虑到现在大多数模型分为encoding和decoding两部分:
- 对于decoding:大多数模型在最终预测图的基础上,采用双线性插值上采样直接获得与输入同分辨率的输出,双线性插值没有学习能力并且会丢失细节。本文提出了密集上采样卷积(dense upsampling convolution,DUC),取代了简单的双线性插值,学习一组上采样滤波器用于放大低分辨率的feature。DUC支持end2end,便于融入FCN网络架构中。
- 对于encoding:使用扩张卷积可以扩大感受野,减少使用下采样(下采样丢失细节比较严重)。本文指出空洞卷积存在”girdding”问题(卷积核退化),即空洞卷积在卷积核两个采样像素之间插入0值,如果扩张率过大,卷积会过于稀疏,捕获信息能力差。 本文提出了混合扩展卷积架构(hybrid dilation convolution,HDC): 使用一组扩展率卷积串接一下构成block,可扩大感受野的同时减轻”gridding”弊端。
从另一个角度想:DUC将整个label map(H,W,L)分为为d^2个等大小的子图(subparts),每个子图和大小和Fout输出的feature map大小相同。也就是说将label map切分为(h,w,d2×L).
模型的整体结构如下,DUC应用在输出部分:

DUC以原始分辨率像素级解码,并且能够自然的集成到FCN框架中,使得整个编码和解码能以end2end方式训练。
作者:DFann
来源:CSDN
原文:https://blog.csdn.net/u011974639/article/details/79460893?utm_source=copy
版权声明:本文为博主原创文章,转载请附上博文链接!