论文全称:《Fully Convolutional Networks for Semantic Segmentation》
论文地址:https://arxiv.org/pdf/1411.4038.pdf
论文代码:
python caffe版本 https://github.com/shelhamer/fcn.berkeleyvision.org
python TensorFlow版本 https://github.com/shekkizh/FCN.tensorflow
https://github.com/MarvinTeichmann/tensorflow-fcn
python keras版本 https://github.com/aurora95/Keras-FCN
python pytorch版本 https://github.com/wkentaro/pytorch-fcn
目录
目录
这篇论文据说是语义分割的开山之作,是在2014年11月提交到arXiv上的,距离现在已经有四年多时间。这篇论文之前已经有人提出了FCN,但是之前的工作都没有这篇论文那样端到端训练,而且也是第一次在语义分割任务上使用了pre-trained预训练模型。虽然当年的R-CNN是基于区域的CNN目标检测系列的第一篇论文,但是R-CNN把检测和分割放到一起没有FCN的效果那么好,所以2014年之后的很多语义分割的网络都是基于FCN创新。
如果对语义分割不太了解可以查看
[深度学习]从全卷积网络到大型卷积核:深度学习的语义分割全指南
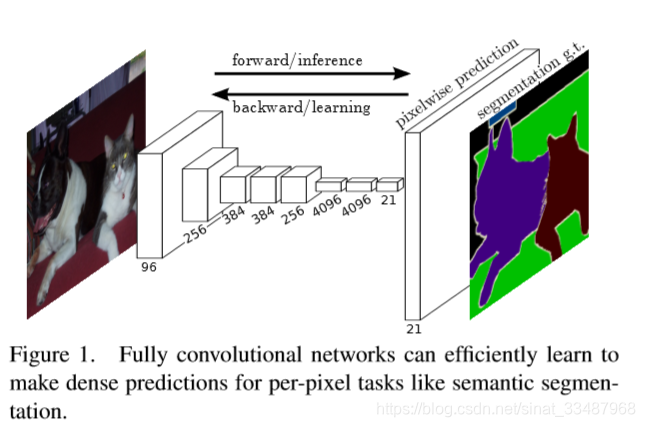
创新之处
- 使用可以end-to-end训练的Fully Convolutional Net和 fine-tuning pre-trained model
- 上采样(Upsampling)生成heatmap
- “skip” architecture结合粗糙的高层语义信息和细致的浅层语义信息
下面详细展开每一个创新点。
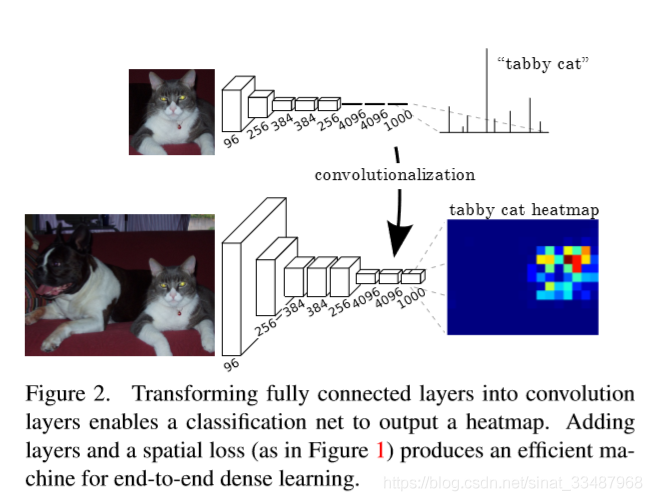
Convolutionlization 卷积化
如上图是将图像的分类网络中最后的全连接层使用1*1的卷积替换。这就是所谓卷积化。卷积层加全连接层的网络最后输出的维度 是大小固定的,不适用于图像分割的任务,为了使得最后的输出根据输入图像大小变化而变化,所以采用了全卷积的网络,这样就能接受任意大小和比例的图像输入。
Upsampling 上采样
虽然将分类网络重新定义为全卷积的,可以生成任意大小输入的输出映射,但是输出维度通常通过子采样被减少了。所以需要upsampling使得输出的heatmap与输入的图像大小一致才能做到语义分割。为此该论文尝试使用三种方式,分别是:
1.Shift-and-stitch
2.简单的双线性插值
3.通过学习的deconvolution反卷积
第一个方法可以参考关于FCN 论文中的 Shift-and-stitch 的详尽解释。
第二个方法可以参考双线性插值算法的详细总结。
详细说说反卷积。反卷积也被称为转置卷积。反卷积和卷积是一个相反的过程,卷积是多个生成一个,反卷积是一个生成多个。考虑转置卷积的最简单方法是首先计算给定输入形状的直接卷积的输出形状,然后反转转置卷积的输入和输出形状。

普通卷积过程

反卷积过程
“skip” architecture 跳跃连接
为了结合粗糙的高层语义信息和细致的浅层语义信息,提出了DAG。由于更细的尺度预测看到的像素更少,所以预测需要更少的层,因此从更浅的净输出中进行预测是有意义的。将精细层和粗层结合起来,可以使模型在局部进行预测时尊重全局结构。他们连接的方式如下图。FCN采取解决方法是将pool4、pool3、和特征map融合起来,由于pool3、pool4、特征map大小尺寸是不一样的,所以融合应该前上采样到同一尺寸。这里的融合是拼接在一起,不是对应元素相加。
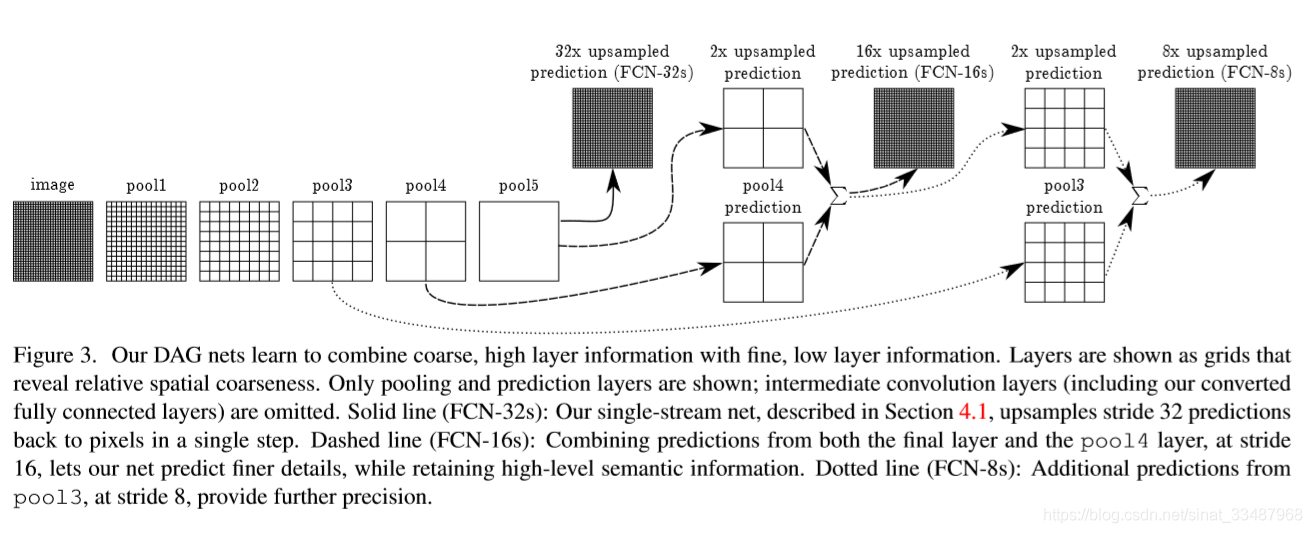
FCN8s是上面讲的pool4、pool3和特征map融合,FCN16s是pool4和特征map融合,FCN32s是只有特征map,得出结果都是细节不够好。

代码详细
代码来源:https://github.com/shelhamer/fcn.berkeleyvision.org/blob/master/voc-fcn8s/net.py
是基于python语言的caffe实现的。只讨论其中的一个版本FCN-8s,数据集是voc。
首先需要定义一些能够服用的函数,比如重复多次的卷积加ReLU,maxpool等。
def conv_relu(bottom, nout, ks=3, stride=1, pad=1):
conv = L.Convolution(bottom, kernel_size=ks, stride=stride,
num_output=nout, pad=pad,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
return conv, L.ReLU(conv, in_place=True)
def max_pool(bottom, ks=2, stride=2):
return L.Pooling(bottom, pool=P.Pooling.MAX, kernel_size=ks, stride=stride)
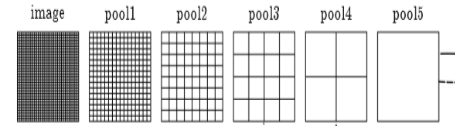
然后开始定义基础网络结构,下面的代码与上面的图片相对应。
n.conv1_1, n.relu1_1 = conv_relu(n.data, 64, pad=100)
n.conv1_2, n.relu1_2 = conv_relu(n.relu1_1, 64)
n.pool1 = max_pool(n.relu1_2)
n.conv2_1, n.relu2_1 = conv_relu(n.pool1, 128)
n.conv2_2, n.relu2_2 = conv_relu(n.relu2_1, 128)
n.pool2 = max_pool(n.relu2_2)
n.conv3_1, n.relu3_1 = conv_relu(n.pool2, 256)
n.conv3_2, n.relu3_2 = conv_relu(n.relu3_1, 256)
n.conv3_3, n.relu3_3 = conv_relu(n.relu3_2, 256)
n.pool3 = max_pool(n.relu3_3)
n.conv4_1, n.relu4_1 = conv_relu(n.pool3, 512)
n.conv4_2, n.relu4_2 = conv_relu(n.relu4_1, 512)
n.conv4_3, n.relu4_3 = conv_relu(n.relu4_2, 512)
n.pool4 = max_pool(n.relu4_3)
n.conv5_1, n.relu5_1 = conv_relu(n.pool4, 512)
n.conv5_2, n.relu5_2 = conv_relu(n.relu5_1, 512)
n.conv5_3, n.relu5_3 = conv_relu(n.relu5_2, 512)
n.pool5 = max_pool(n.relu5_3)
接着是全卷积部分。这一部分有三个分支。这里解释一下我之前理解错误的一个地方,下图中有三个密集的输出,但是真实的网络中只有一个输出,比如FCN-32s,FCN-16s,FCN-8s。所以这里的代码是FCN-8s就不存在FCN-32s和FCN-16s的密集输出。
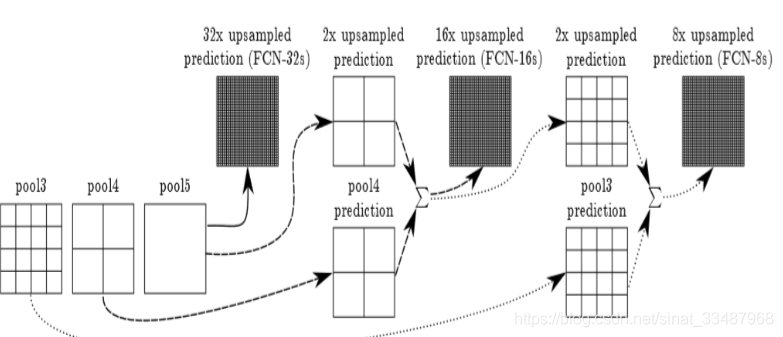
第一个分支:其中n.upscore2对应于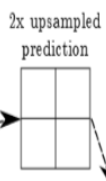
# fully conv
n.fc6, n.relu6 = conv_relu(n.pool5, 4096, ks=7, pad=0)
n.drop6 = L.Dropout(n.relu6, dropout_ratio=0.5, in_place=True)
n.fc7, n.relu7 = conv_relu(n.drop6, 4096, ks=1, pad=0)
n.drop7 = L.Dropout(n.relu7, dropout_ratio=0.5, in_place=True)
n.score_fr = L.Convolution(n.drop7, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.upscore2 = L.Deconvolution(n.score_fr,
convolution_param=dict(num_output=21, kernel_size=4, stride=2,
bias_term=False),
param=[dict(lr_mult=0)])第二个分支:首先得对pool4做一层卷积。这里特别注意一下crop()函数,论文里面也提到过,他的主要作用是进行裁切。Eltwise()则是用于将两个feature以相加的方式组合在一起,因为这里设定了operation是Sum,其实还可以是点乘等操作。
这里的Eltwise就对应于: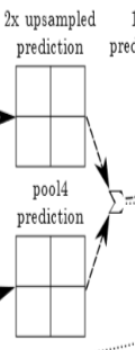
n.score_pool4 = L.Convolution(n.pool4, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.score_pool4c = crop(n.score_pool4, n.upscore2)
n.fuse_pool4 = L.Eltwise(n.upscore2, n.score_pool4c,
operation=P.Eltwise.SUM)
n.upscore_pool4 = L.Deconvolution(n.fuse_pool4,
convolution_param=dict(num_output=21, kernel_size=4, stride=2,
bias_term=False),
param=[dict(lr_mult=0)])最后一个分支包括了密集的输出:跟上一个分支类似,只不过结合的feature变成了pool3。n.upscore8就对应于:
n.score_pool3 = L.Convolution(n.pool3, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.score_pool3c = crop(n.score_pool3, n.upscore_pool4)
n.fuse_pool3 = L.Eltwise(n.upscore_pool4, n.score_pool3c,
operation=P.Eltwise.SUM)
n.upscore8 = L.Deconvolution(n.fuse_pool3,
convolution_param=dict(num_output=21, kernel_size=16, stride=8,
bias_term=False),
param=[dict(lr_mult=0)]) n.score = crop(n.upscore8, n.data)
n.loss = L.SoftmaxWithLoss(n.score, n.label,
loss_param=dict(normalize=False, ignore_label=255))将n.upscore8和label softmax 得出loss。
最后奉上源码
import caffe
from caffe import layers as L, params as P
from caffe.coord_map import crop
def conv_relu(bottom, nout, ks=3, stride=1, pad=1):
conv = L.Convolution(bottom, kernel_size=ks, stride=stride,
num_output=nout, pad=pad,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
return conv, L.ReLU(conv, in_place=True)
def max_pool(bottom, ks=2, stride=2):
return L.Pooling(bottom, pool=P.Pooling.MAX, kernel_size=ks, stride=stride)
def fcn(split):
n = caffe.NetSpec()
pydata_params = dict(split=split, mean=(104.00699, 116.66877, 122.67892),
seed=1337)
if split == 'train':
pydata_params['sbdd_dir'] = '../data/sbdd/dataset'
pylayer = 'SBDDSegDataLayer'
else:
pydata_params['voc_dir'] = '../data/pascal/VOC2011'
pylayer = 'VOCSegDataLayer'
n.data, n.label = L.Python(module='voc_layers', layer=pylayer,
ntop=2, param_str=str(pydata_params))
# the base net
n.conv1_1, n.relu1_1 = conv_relu(n.data, 64, pad=100)
n.conv1_2, n.relu1_2 = conv_relu(n.relu1_1, 64)
n.pool1 = max_pool(n.relu1_2)
n.conv2_1, n.relu2_1 = conv_relu(n.pool1, 128)
n.conv2_2, n.relu2_2 = conv_relu(n.relu2_1, 128)
n.pool2 = max_pool(n.relu2_2)
n.conv3_1, n.relu3_1 = conv_relu(n.pool2, 256)
n.conv3_2, n.relu3_2 = conv_relu(n.relu3_1, 256)
n.conv3_3, n.relu3_3 = conv_relu(n.relu3_2, 256)
n.pool3 = max_pool(n.relu3_3)
n.conv4_1, n.relu4_1 = conv_relu(n.pool3, 512)
n.conv4_2, n.relu4_2 = conv_relu(n.relu4_1, 512)
n.conv4_3, n.relu4_3 = conv_relu(n.relu4_2, 512)
n.pool4 = max_pool(n.relu4_3)
n.conv5_1, n.relu5_1 = conv_relu(n.pool4, 512)
n.conv5_2, n.relu5_2 = conv_relu(n.relu5_1, 512)
n.conv5_3, n.relu5_3 = conv_relu(n.relu5_2, 512)
n.pool5 = max_pool(n.relu5_3)
# fully conv
n.fc6, n.relu6 = conv_relu(n.pool5, 4096, ks=7, pad=0)
n.drop6 = L.Dropout(n.relu6, dropout_ratio=0.5, in_place=True)
n.fc7, n.relu7 = conv_relu(n.drop6, 4096, ks=1, pad=0)
n.drop7 = L.Dropout(n.relu7, dropout_ratio=0.5, in_place=True)
n.score_fr = L.Convolution(n.drop7, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.upscore2 = L.Deconvolution(n.score_fr,
convolution_param=dict(num_output=21, kernel_size=4, stride=2,
bias_term=False),
param=[dict(lr_mult=0)])
n.score_pool4 = L.Convolution(n.pool4, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.score_pool4c = crop(n.score_pool4, n.upscore2)
n.fuse_pool4 = L.Eltwise(n.upscore2, n.score_pool4c,
operation=P.Eltwise.SUM)
n.upscore_pool4 = L.Deconvolution(n.fuse_pool4,
convolution_param=dict(num_output=21, kernel_size=4, stride=2,
bias_term=False),
param=[dict(lr_mult=0)])
n.score_pool3 = L.Convolution(n.pool3, num_output=21, kernel_size=1, pad=0,
param=[dict(lr_mult=1, decay_mult=1), dict(lr_mult=2, decay_mult=0)])
n.score_pool3c = crop(n.score_pool3, n.upscore_pool4)
n.fuse_pool3 = L.Eltwise(n.upscore_pool4, n.score_pool3c,
operation=P.Eltwise.SUM)
n.upscore8 = L.Deconvolution(n.fuse_pool3,
convolution_param=dict(num_output=21, kernel_size=16, stride=8,
bias_term=False),
param=[dict(lr_mult=0)])
n.score = crop(n.upscore8, n.data)
n.loss = L.SoftmaxWithLoss(n.score, n.label,
loss_param=dict(normalize=False, ignore_label=255))
return n.to_proto()
def make_net():
with open('train.prototxt', 'w') as f:
f.write(str(fcn('train')))
with open('val.prototxt', 'w') as f:
f.write(str(fcn('seg11valid')))
if __name__ == '__main__':
make_net()