一、定义
语义图像分割的目标是标记图像每个像素的类别。因为我们需要预测图像中的每个像素,所以此任务通常被称为密集预测。
二、参考资料
论文:U-Net: Convolutional Networks for Biomedical Image Segmentation
三、网络结构
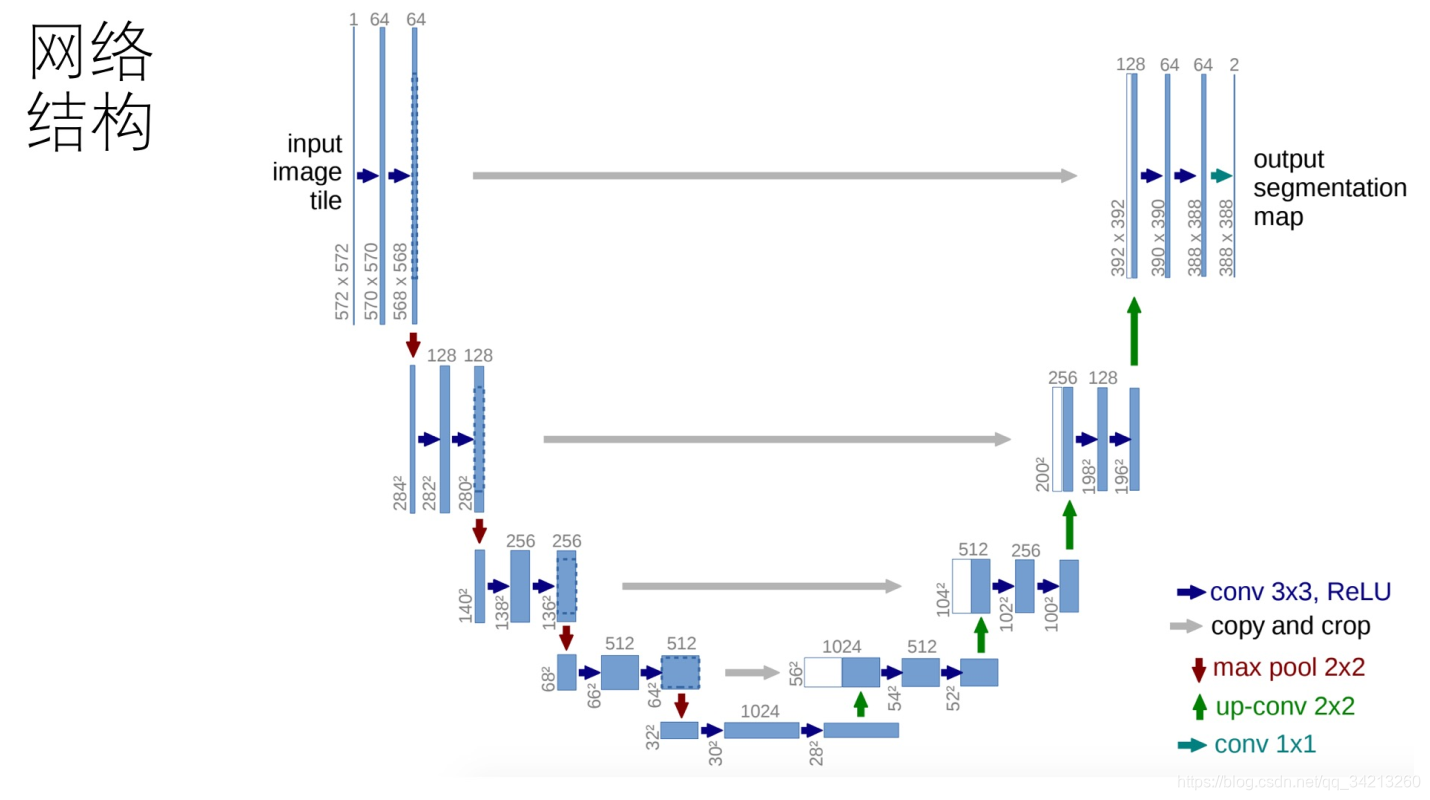
四、Transposed Convolutions/ Deconvolution/up convolutions
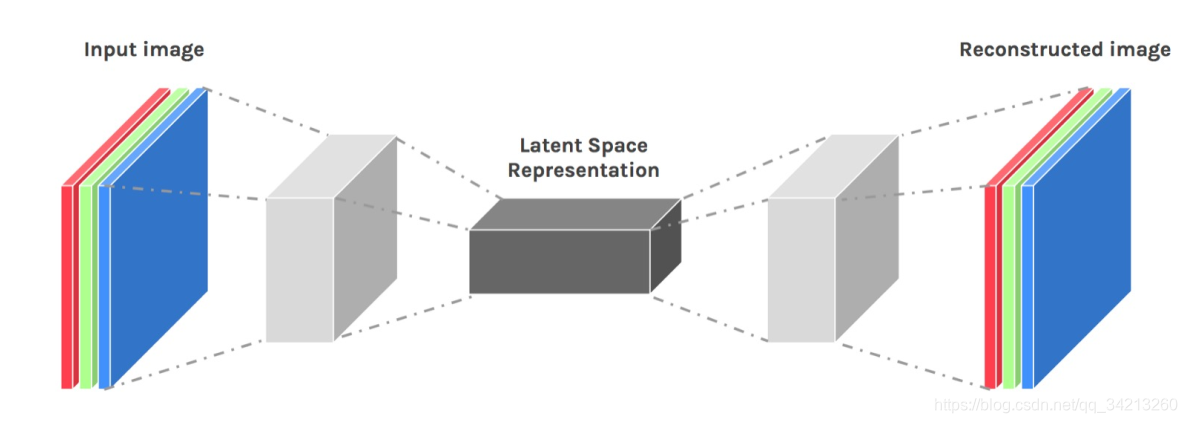
卷积和池化的输出相对于输入尺寸缩小。池化通过增加视场,帮助我们理解图像中的物体是什么,但是这个操作也丢失了物体的位置信息
●在语义分割中,我们不但需要知道图像中的物体是什么,还需要知道物体在哪儿我们需要一种将图像放大同时保留位置信息的操作
●Transposed Convolution是图像过采样(up sampling)的最佳选择,它通过误差向后传递学习最佳的权值使得低分辨率图像转换为高分辨率图像的效果最好.

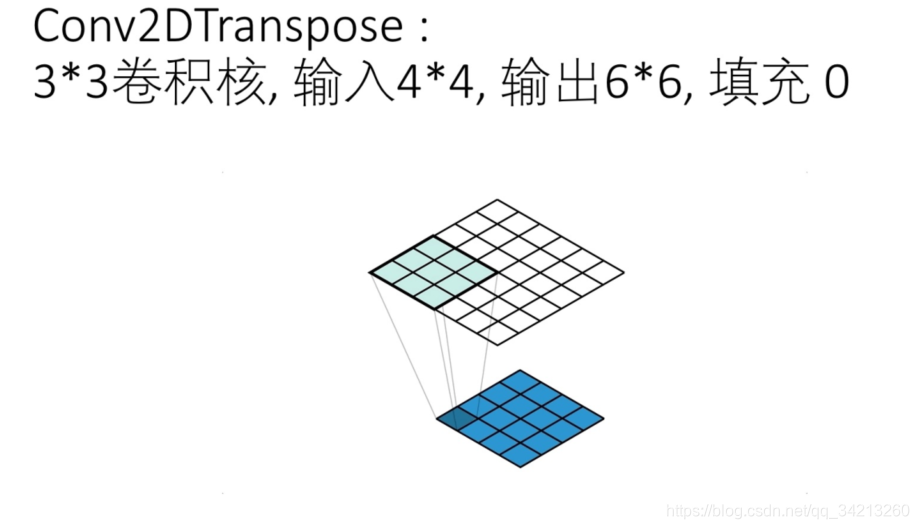
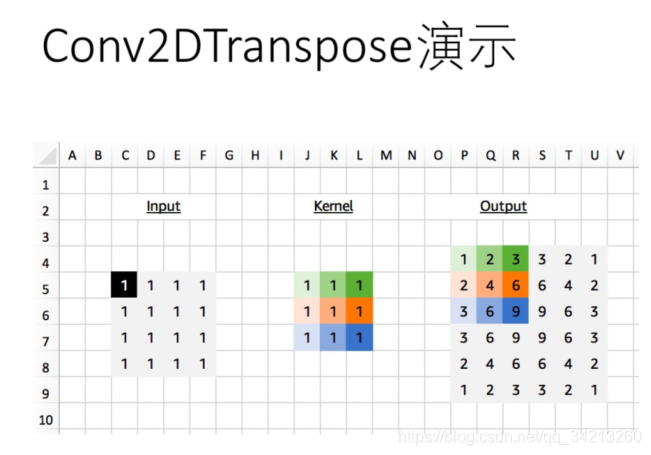 你可能已经发现输出的边缘积累比中心位置少。通常这不是问题,因为内核权重会为此进行调整,也可能是负的。
你可能已经发现输出的边缘积累比中心位置少。通常这不是问题,因为内核权重会为此进行调整,也可能是负的。
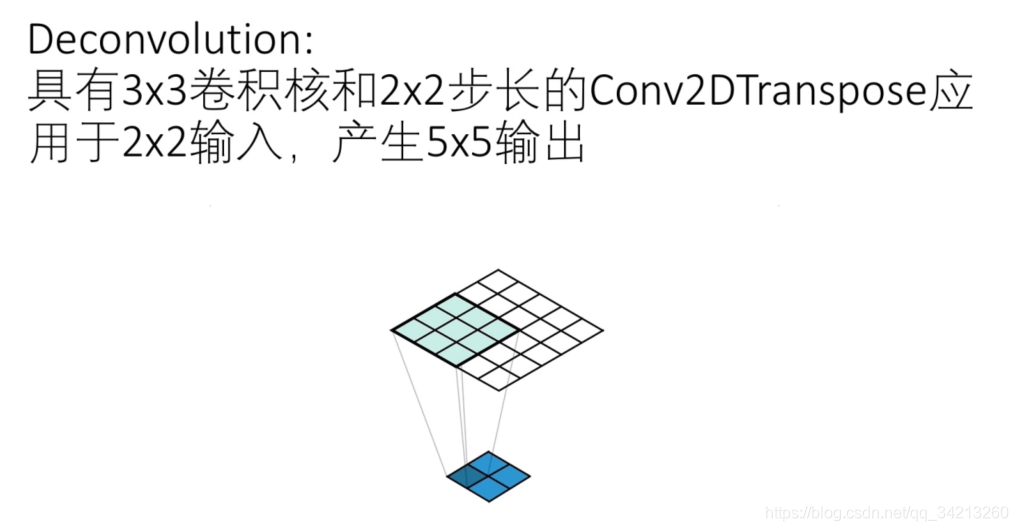
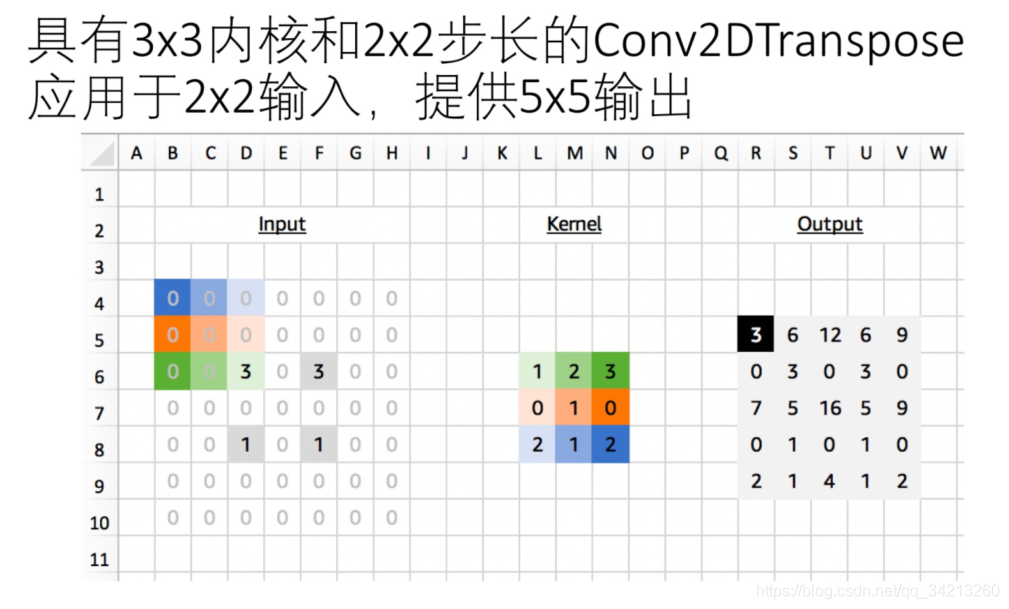
Conv2DTranspose的问题
●1.与插值法(双三次插值bicubic)或者最近临插值相比, Conv2DTranspose是监督式学习算法,是需要训练的
●2.会产生棋盘效应,其中一个解决方案是先插值,再使用Conv2DTranspose
 https://distill.pub/2016/deconv-checkerboard/
https://distill.pub/2016/deconv-checkerboard/
五、代码示例:
代码下载:https://download.csdn.net/download/qq_34213260/12460227
练习数据:https://www.kaggle.com/c/tgs-salt-identification-challenge/data