文章地址:https://arxiv.org/pdf/1809.03118.pdf
代码地址:https://github.com/lancopku/Seq2Set
文章标题:A Deep Reinforced Sequence-to-Set Model for Multi-Label Classification(多标签分类的深度增强序列集模型)ACL2019
Abstract
多标签分类(MLC)旨在预测给定实例的一组标签。基于预先定义的标签顺序,通过最大似然估计方法训练的序列-序列序列(Seq2Seq)模型已成功地应用于MLC任务,并显示出强大的能力来捕获标签之间的高阶相关性。然而,输出标签本质上是一个无序集,而不是有序序列。这种不一致性往往会导致一些棘手的问题,如对标签顺序的敏感性。为了解决这个问题,我们提出了一个简单而有效的序列到集合模型。提出的模型通过强化学习进行训练,其中奖励反馈被设计成独立于标签顺序。通过这种方式,我们可以减少模型对标签顺序的依赖,并捕获标签之间的高阶相关性。大量的实验表明,我们的方法可以大大超过竞争的基线,以及有效地降低标签顺序的敏感性。
一、Introduction
多标签分类(MLC)旨在为每个样本分配多个标签。它可以应用于许多真实的场景,如文本分类(Schapire和Singer, 2000)和信息检索(Gopal和Yang, 2010)。由于标签之间的复杂依赖性,如何有效地捕获标签之间的高阶相关性是MLC任务的关键挑战(Zhang and Zhou, 2014)。
在涉及到获取标签之间的高阶相关性时,有一条研究路线侧重于探索标签空间的层次结构(Prabhu and Varma, 2014; Jernite et al.,2017; Peng et al., 2018; Singh et al., 2018),,而另一行则努力扩展特定的学习算法(Zhang and Zhou, 2006; Baker and Korhonen, 2017; Liu et al., 2017)。然而,这些工作往往导致棘手的计算成本(Chen et al., 2017)。
最近,基于预先定义的标签顺序,Nam et al. (2017); Yang et al. (2018)成功地将sequence-to-sequence (Seq2Seq)模型应用到MLC任务中,显示出其强大的捕获高阶标签关联的能力,并取得了优异的性能。然而,Seq2Seq模型在MLC任务上存在一些棘手的缺陷。输出标签本质上是一个带有swapping-invariance(意味着交换集合中的任何两个元素都没有区别)的无序集,而不是一个有序序列。这种不一致性通常会导致一些棘手的问题,例如对标签顺序的敏感性。之前的工作(Vinyals et al., 2016)已经表明,顺序对Seq2Seq模型的性能有很大的影响。因此,分类器的性能对预先定义的标签顺序非常敏感。此外,即使该模型准确预测了所有的真标签,但由于与预先定义的标签序列的顺序不一致,仍可能导致不合理的训练损失。
因此,在本研究中,我们提出了一种简单而有效的序列-集合模型,旨在减轻模型对标签顺序的依赖。我们使用强化学习(RL) (Sutton et al., 1999)来指导模型训练,而不是最大化预先定义的标签序列的日志可能性。设计的奖励不仅全面评价了输出标签的质量,而且满足了集的切换不变性,减少了模型对标签顺序的依赖。
本文的主要贡献总结如下:
- 提出了一种简单有效的基于强化学习的序列集(Seq2Set)模型,该模型不仅捕获了标签之间的相关性,而且减轻了对标签顺序的依赖。
- 实验结果表明,我们的Seq2Set模型的性能大大优于基线。进一步的分析表明,我们的方法可以有效地降低模型对标签顺序的敏感性。
二、Methodology
2.1 Overview
这里我们定义了一些必要的符号并描述了MLC任务。给定一个文本序列x包含m个词,多标签分类任务的目标是分配一个子集y包含n个标签在总标签集y到x。从序列的角度学习,一旦输出标签的顺序是预定义的,多标签分类任务可以被视为目标标签序列的生成y条件在源文本序列x。
2.2 Neural Sequence-to-Set Model
我们提出的Seq2Set模型由编码器E和集合解码器D组成,具体介绍如下。
(1)Encoder E
我们将编码器E实现为一个双向LSTM。给定输入文本(x1,…, xm),编码器计算每个词的隐藏状态如下:
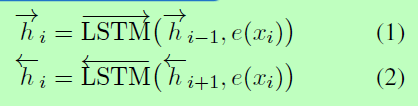
其中e(xi)为xi的嵌入。第i个单词的最终表示是hi,其中分号表示向量连接。
(2)Set decoder D
由于LSTM强大的能力来建模序列依赖性,我们也实现了D作为一个LSTM模型来捕获标签之间的高阶相关性。实际上,第t时刻集合解码器D的隐藏状态st计算为:
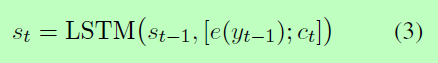
在[e(yt-1); ct]表示向量的级联e(yt-1)和ct, e(yt-1)是标签的嵌入yt-1在上一个时间步生成的,ct是通过注意机制获得的上下文向量。读者可以参考Bahdanau等人(2015)了解更多细节。最后,集合解码器D从输出概率分布中对标签yt进行采样,计算如下:
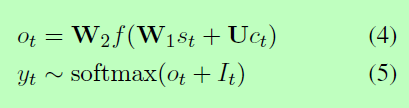
其中W1、W2、U为可训练参数,f为非线性激活函数,其It是为防止D产生重复标签的掩码向量,

2.3 Model Training
(1)MLC as a RL Problem
为了减轻模型对标签顺序的依赖,这里我们将MLC任务建模为一个RL问题。我们的集合解码器D可以看作是一个代理,它在t时刻的状态是当前生成的标签(y1,…, yt-1)。由参数D定义的随机策略决定动作,即对下一个标签的预测。一旦生成完整的标签序列y, 代理D将得到奖励r。训练目标是最小化负的期望奖励,具体如下:
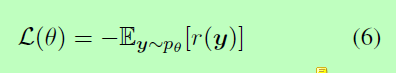
在我们的模型中,我们使用了自批判策略梯度算法(Rennie et al., 2017)。对于minibatch中的每个训练样本,Eq.(6)的梯度近似为:
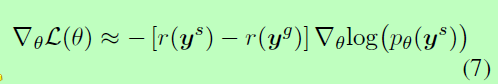
其中ys为概率分布p采样的标签序列,yg为贪婪搜索算法生成的标签序列。Eq.(7)中的r(yg)为基线,其目的是降低梯度估计的方差,增强模型训练和测试的一致性,缓解exposure bias(Ranzato et al., 2016)。
(2)Reward Design
理想的奖励应该是对生成的标签质量的良好度量。此外,为了使模型不受标签顺序的严格限制,还应满足输出标签集的swappingconstant。为此,我们将生成的标签y与ground-truth标签y*进行比较,设计出F1的积分作为奖励r。
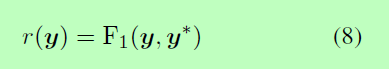
我们也尝试了其他的奖励设计,比如汉明精度。结果表明,基于F1分数的奖励是最佳的综合表现。
三、Experiments
3.1 Datasets
我们在RCV1-V2语料库上进行实验(Lewis et al., 2004),该语料库包含大量手动分类的新闻专线故事。标签的总数是103个。Yang等(2018)也采用了同样的数据分解方法。
3.2 Settings
我们根据微f1分数调整验证集上的超参数。词汇量为50,000,批处理大小为64。我们将嵌入大小设置为512。编码器和集解码器都是2层的LSTM,隐藏大小为512,但前者设置为双向。我们用MLE(极大似然估计)方法对模型进行了20个epoch的预训练。优化器是Adam(Kingma和Ba, 2015)与10-3训练的学习速率和10-5RL(强化学习)学习率。此外,我们使用dropout (Srivastava et al., 2014)来避免过度拟合,并剪切梯度(Pascanu et al., 2013)到最大范数8。
3.3 Baselines
我们将我们的方法与以下竞争性基线进行比较:
- BR-LR:相当于为每个标签独立训练一个二元分类器(逻辑回归)。
- PCC-LR:将MLC任务转换为二进制分类(逻辑回归)问题链。
- FastXML:学习训练实例的层次结构,并在层次结构的每个节点上优化目标。
- XML-CNN:使用动态最大池机制和隐藏的瓶颈层来更好地表示文档。
- CNN-RNN:提出了一种CNN和RNN的集成方法来捕获全局和局部文本语义。
- Seq2Seq:采用Seq2Seq模型进行多标签分类
3.4 Evaluation Metrics
评价指标包括:计算误分率的子集0-1损失,表示误预测标签占总标签的比例的汉明损失,以及表示每个类的F1分的加权平均值的micro-F1。微精度和微召回也供参考。
四、Results and Discussion
本文对模型和实验结果进行了深入分析。为简单起见,我们使用BR来表示基线BR- LR。
4.1 Experimental Results
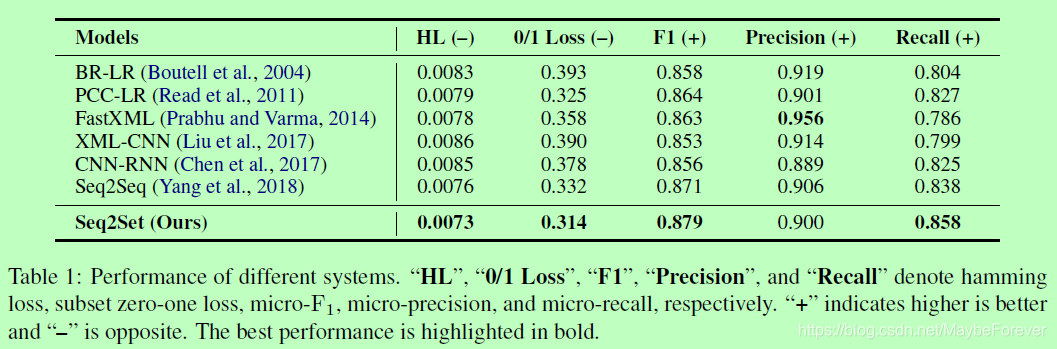
我们的方法和所有基线的比较如表1所示,表明所提出的Seq2Set模型在所有评价指标上都比所有基线有较大的优势。与完全忽略标签相关性的BR相比,我们的Seq2Set模型减少了12.05%的汉明损失。结果表明,对高阶标签相关关系进行建模可以大大改善结果。与对标签订单有严格要求的Seq2Seq相比,我们的Seq2Set模型在RCV1-V2数据集上减少了3.95%的汉明损失。这表明我们的方法可以通过减少模型对标签订单的依赖来实现实质性的改进。
4.2 Reducing Sensitivity to Label Order

为了验证我们的方法可以降低标签顺序的敏感性,我们随机打乱标签序列的顺序。表2展示了不同模型在标签变换的RCV1-V2数据集上的性能。结果表明,对于打乱的标签顺序,BR没有受到影响,但是Seq2Seq的性能却急剧下降。因为Seq2Seq的解码器本质上是一个条件语言模型。它严重依赖于一个合理的标签顺序来建模标签之间的内在关联,而在这种情况下,标签呈现无序状态。然而,我们的模型在子集0 - 1损失上的性能仅下降了1.2%5,而Seq2Seq下降了9.3%。这说明我们的Seq2Set模型具有更强的鲁棒性,可以抵抗标签顺序的干扰。我们的模型是通过强化学习来训练的,奖励反馈与标签顺序无关,降低了对标签顺序的敏感性。
4.3 Improving Model Universality
RCV1-V2数据集中的标签呈现长尾分布。然而,在实际场景中,还有其他常见的标签分布,如均匀分布(Lin et al., 2018a)。因此,这里我们分析了Seq2Set模型的通用性,这意味着它可以在不同的标签分发情况下实现稳定的性能改进。详细地,我们依次删除RCV1-V2数据集中最频繁的k标签,并对其余标签执行评估。k越大,标签分布越均匀。图1显示了不同系统的性能变化。
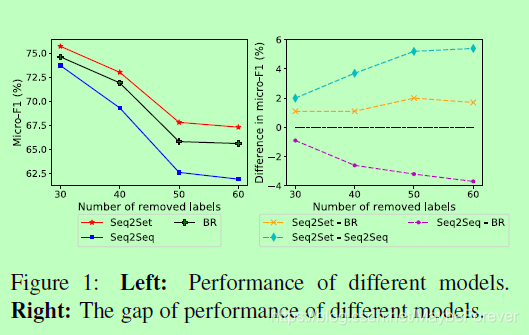
首先,随着移除高频标签的数量增加,所有方法的性能都会下降。这是合理的,因为预测低频标签相对困难。但是,与其他方法相比,Seq2Seq模型的性能大大降低。我们怀疑这是因为统一分布的标签很难定义一个合理的订单,而Seq2Seq对标签的订单有严格的要求。这种冲突可能会损害性能。然而,如图1所示,随着更多的标签被删除,Seq2Set相对于Seq2Seq的优势继续增强。这说明我们的Seq2Set模型具有良好的通用性,适用于不同的标签分发。我们的方法不仅具有Seq2Seq捕获标签相关性的能力,而且通过强化学习,减轻了Seq2Seq对标签顺序的严格要求。这样就避免了在均匀分布上预先定义合理的标签顺序的困难,从而具有很好的通用性。
4.4 Error Analysis
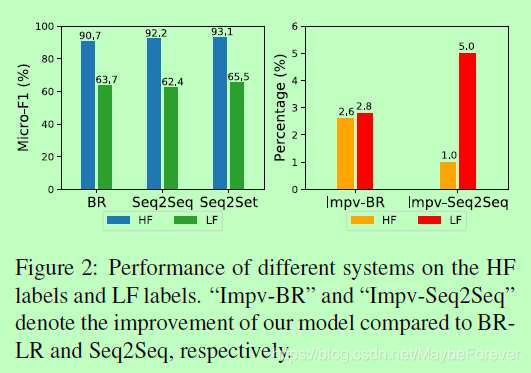
我们发现所有的方法在预测低频(LF)标签和高频(HF)标签时的表现都很差。这是合理的,因为分配给LF标签的样本是稀疏的,使得模型很难学习有效的模式来进行预测。图2为不同方法对HF标签和LF标签的检测结果。但是,与其他系统相比,我们提出的Seq2Set模型在LF标签和HF标签上都有更好的性能。此外,我们的方法在LF标签上取得的相对改进要大于HF标签。事实上,LF标签的分布较为均匀。如4.3节所分析的,在均匀分布中,标签订单问题更为严重。我们的Seq2Set模型可以通过强化学习来减少对标签顺序的依赖,从而使LF标签的性能有较大的提高。
五、Related Work
多标签分类(MLC)旨在为数据集中的每个样本分配多个标签。早期对MLC任务的研究主要集中在机器学习算法上,主要包括问题转换方法和算法适应方法。问题转换方法,如BR (Boutell et al., 2004)、LP (Tsoumakas和Katakis, 2006)和CC (Read et al., 2011),旨在将MLC任务映射成多个单标记学习任务。算法适应方法力求扩展特定的学习算法,直接处理多标签数据。相应的代表作有ML-DT (Clare and King, 2001)、Rank-SVM (Elisseeff and Weston, 2001)、ML-KNN (Zhang and Zhou, 2007)等。此外,其他一些方法,包括集成方法(Tsoumakas et al., 2011)和联合训练(Li et al., 2015),也可以用于MLC任务。然而,它们只能用于捕获一阶或二阶标签相关性(Chen et al., 2017),或者在考虑高阶标签相关性时是计算上难以处理的。
近年来,一些神经网络模型也被成功地用于MLC任务。例如,Zhang和Zhou(2006)提出的BP-MLL采用全连通网络和两两排序损失进行分类。Nam等(2013)进一步用交叉熵损失函数代替两两排序损失。Kurata等人(2016)提出了一种利用神经元对标签相关性进行建模的初始化方法。Chen等人(2017)提出了CNN和RNN的集成方法来捕获全局和局部语义信息。Liu等人(2017)使用动态最大池机制和隐藏的瓶颈层来更好地表示文档。Peng等人(2018)利用图卷积运算来捕获非连续和长距离语义。这两个里程碑是Nam et al.(2017)和Yang et al.(2018),两者都利用Seq2Seq模型来捕获标签相关性。更进一步,Lin等(2018b)提出了一种基于语义单元的扩展卷积模型,Zhao等(2018)提出了一种基于标签图的神经网络,该神经网络采用软训练机制来捕获标签相关性。最近,Qin等人(2019)提出了新的基于集合概率的训练目标,有效地对集合的数学特征进行建模。
六、Conclusion
在本研究中,我们提出一种简单而有效的基于强化学习的序对集模型,其目的在于减少对标签顺序序对集模型的严格要求。该模型不仅捕获了标签之间的高阶相关性,而且减少了对输出标签顺序的依赖。实验结果表明,我们的Seq2Set模型能够大幅度地超越竞争基线。进一步的分析表明,我们的方法可以有效地降低标签订单的敏感性。
