X-BERT: eXtreme Multi-label Text Classification with BERT

文本分类(text classifition)可以简单的分为二分类问题和多分类问题,现在的文本分类相挂钩的任务往往解决的都是前者,而当类别数较少时,多分类问题仍然可使用one-vs-all的方法将多分类问题转换为二分类问题处理。而本文所关注的是极端多分类(extreme multi-label text classifition)任务,即语料库中的每个样本所对应最好的标签需从大规模的标签集中进行寻找,标签集的容量可能成千上万,类似于CV中ImageNet的千分类问题。如果同样将其简单的使用one-vs-all的方法转换为二分类问题处理,那么数据集的规模和计算量将急速增长而变得哪里处理。因此,本文提出了一种结合BERT的三阶段模型来解决极端多分类任务,并在基准数据集上进行实验做到了SOTA。
对于文本分类模型而言,假设预料库为 ,样本为 ,语料库样本的标签集为 ,那么模型可表示为 。在极端多分类问题中,为了模型的有效性和减少计算量,XBERT采用了三阶段的处理方式,如下图所示:
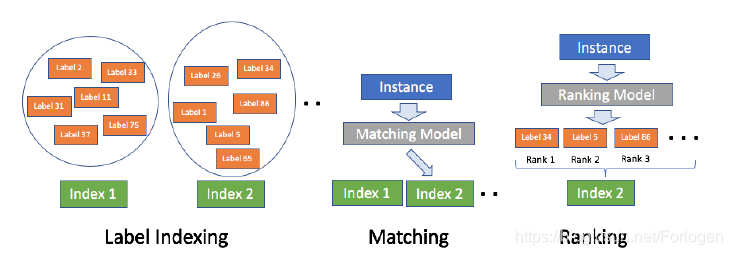
Sementic Label Indexing
借鉴信息检索(information retrieval)中文档排序(document ranking)的思想,首先为标签建立索引。不同于IR中索引类型为ID的方式,XBERT采用标签的语义表示向量做为它的索引。由于此时的标签是文本类型,因此XBERT采用ELMO对标签中的token进行编码,最后将每个token的向量做一次平均池化(mean pooling)操作,将得到的结果做为语义标签。
同时考虑到当描述文本较短时,文本中的词可能无法提供足够的信息或者可能带来噪声,XBERT又使用TF-IDF来做一次加权,并将其称为Positive Instance Feature Aggregation,简称PIFA。
另外为了减少后续的计算量,此阶段还使用了K-means将标签按照语义相似程度进行聚类,将每个簇做为后续匹配模型的基本处理单元。
作者这里指出,不同于IR的索引建立过程,只要后续的匹配模型和排序模型能力足够前,即使索引并不十分准确也不打紧。
Deep Neural Matching
匹配模型采用了Bi-LSTM + self-attention 的架构方式来获取文本的表示向量,然后使用一个浅层的神经网络来做最后的匹配工作。为了减少匹配工作的计算量,只要簇中有一个标签和文本的相关性足够高就认为该簇和文本相关。由于在聚类过程中簇的数目 是自行设定的,因此模型训练和推断所需的时间较大幅减少。
Ensemble Ranking
前一阶段得到的是和文本相关的簇,由于簇中包含多个可能相关的标签,而最终的任务是找到和文本最相关的标签,因此还需要对相关的簇中的标签进行进一步的排序。XBERT同样的是采用了BERT原文中提出的针对于文本分类的机制,为了进一步提升排序模型的效果,XBERT采用了集成的方法,通过不同的设置得到不同的排序模型,最后综合考虑所有模型的结果来为簇中的标签进行打分。
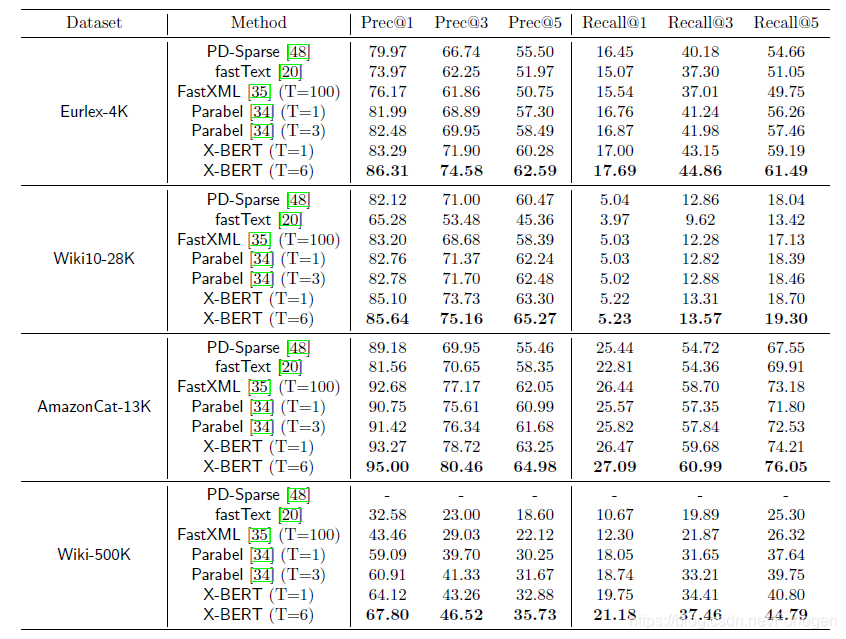
experiment
实验部分可见原文