文章地址:https://www.aclweb.org/anthology/D15-1099.pdf
文章标题:Multi-label Text Categorization with Joint Learning Predictions-as-Features Method(基于联合学习预测-特征法的多标签文本分类)EMNLP2015
文章代码:https://github.com/algorithmdog/Joint_Learning_Predictions_as_Features_for_Multi_Label_Classification
Abstract
多标签文本分类是文本分类的一种类型,其中每个文档被分配到一个或多个类别。近年来,人们开发了一系列的方法,对每个标签训练一个分类器,将分类器组织成部分有序结构,并将前一个分类器产生的预测作为后一个分类器的特征。这些预测-特征样式的方法对高阶标签依赖关系建模并获得高性能。然而,预测-特性方法有一个缺点。在为一个标签训练分类器时,作为预测-特性方法可以对前一个标签和当前标签之间的依赖关系建模,但是不能对当前标签和后一个标签之间的依赖关系建模。为了解决这一问题,我们提出了一种新的联合学习算法,该算法允许反馈从后面标签的分类器传播到当前标签的分类器。我们使用真实的文本数据集进行了实验,这些实验证明了我们的算法训练的作为特征的预测模型优于原始模型。
一、Introduction
多标签文本分类是文本分类的一种类型,其中每个文档同时被分配到一个或多个类别。多标签设置在现实世界中很常见也很有用。例如,在新闻分类任务中,报纸上关于全球变暖的文章可以同时分为环境和科学两类。再举个例子,在将音乐歌词归类为情感的任务中,一首歌曲的歌词可以同时传递快乐和兴奋。
最近,人们开发了一系列的“预测-特征”风格的方法,这些方法为每个标签训练一个分类器,以部分有序的结构组织分类器,并将前一个分类器产生的预测作为后一个分类器的特征。这些谓词即功能风格的方法对高阶标签依赖关系进行建模(Zhang and Zhang, 2010),并获得高性能。分类器链(CC) (Read et al., 2011)和利用标签依赖关系(Lead)的多标签学习(Zhang and Zhang, 2010)是两种著名的预测即特征方法。CC沿着一个链组织分类器,并领导在贝叶斯网络中组织分类器。此外,还有其他关于扩展断言即特征方法的著作(Zaragoza et al., 2011;2013年;Sucar等,2014)。在本文中,我们将重点讨论预测-特征样式方法。
之前的预测-特征方法的工作重点是学习部分有序结构。他们忽略了一个缺点。在为一个标签训练分类器时,作为特性的谓词方法可以对前一个标签和当前标签之间的依赖关系建模,但是它们不能对当前标签和后一个标签之间的依赖关系建模。以三个标签为例。我们在图1所示的部分有序结构中组织分类器。当训练第二个标签的分类器时,特征(图中粗体的线条)由原始特征和第一个标签的预测组成。关于第三个标签的信息不能合并这意味着我们只对第一个标签和第二个标签之间的依赖关系建模,而第二个标签和第三个标签之间的依赖关系是缺失的。

图一:当训练第二个标签的分类器时,特征(粗体线)只包含原始特征和对第一个标签的预测。此时,不可能对第二个标签和第三个标签之间的依赖关系建模。
为了解决这一问题,我们提出了一种新的联合学习算法,该算法允许从后一个标签的分类器向当前标签的分类器传播反馈,这样就可以合并后一个标签的信息。这意味着所提出的方法不仅可以将以前的标签和当前的标签之间的依赖关系建模为通常的断言即特性方法,而且还可以对当前标签和后一个标签之间的依赖关系建模。不丢失依赖项。因此,提出的方法将提高性能。实验结果表明,该算法训练的模型优于原模型。
二、Joint Learning Algorithm
2.1 Preliminaries
设X为文档特征空间,Y = {0,1}m用m个标签表示标签空间。文档实例x与标签向量y = (y1, y2,…,ym),其中yi = 1表示文档有第i个标签,否则为0。多标记学习的目标是学习一个函数h。一般来说,h由m个函数组成,其中一个函数代表一个标签,即, h(x) = [h1(x), h2(x),…hm(x)]。
在预测-特征的方法中,分类器以部分有序的结构进行组织,并将前一个分类器生成的预测作为特征。我们可以将预测-特征方法中的分类器描述如下:
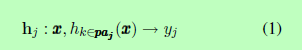
其中paj表示部分有序结构中第j个分类器的父级集合。
2.2 Architecture and Loss
在这一节中,我们介绍了我们的联合学习算法的结构和损失函数。作为一个激励的例子,我们使用逻辑回归作为预测-特征方法的基分类器。分类函数为sigmoid函数,如式(2)所示:
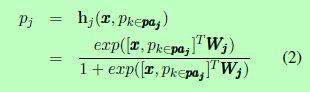
该算法通过最小化全局损失函数来联合学习局部有序结构中的分类器。我们使用所有分类器的负对数似然损失之和作为全局损失函数。
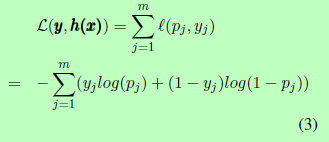
联合算法使该全局损失函数最小化,如式(4)所示:
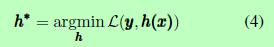
最小化这个全局损失函数与最小化每个基分类器的损失函数是不相等的,因为最小化全局损失函数会导致后面分类器的反馈。在以谓词为特征的方法中,第k个分类器的权值不仅是第k个分类器的因子,而且是后一个分类器的因子。因此,在最小化全局损失函数时,第k个分类器的权值不仅根据第k个分类器的损失进行更新,还根据后一个分类器的损失进行更新。换句话说,反馈从后一个分类器传播到第k个分类器。
我们提出的联合学习算法训练的“预测-特征”模型可以模拟前标签和当前标签之间的依赖关系,因为它们采用前分类器的预测来扩展后分类器的特征,就像通常的“预测即特征”方法所做的那样。此外,由于联合学习算法所包含的反馈,它们还可以对当前标签和后一个标签之间的依赖关系进行建模。
这里,我们使用逻辑回归作为激励的例子。如果我们想使用其他的分类模型,我们使用其他的分类函数和其他的损失函数。例如,如果我们想使用L2 SVM作为基本分类器,我们可以使用线性分类函数和L2铰链损耗函数。
我们使用了通过结构(BTS)的反向传播(Goller and Kuchler, 1996)来最小化全局损失函数。在BTS中,父节点与子节点在正向传递阶段进行计算;子节点接收梯度作为其所有父节点的导数的和。
三、Experiments
3.1 Datasets
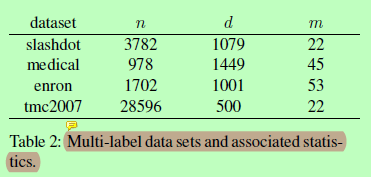
表二:多标签数据集和相关的统计信息。
3.2 Evaluation Metrics
(1)Hamming loss
(2)multi-label 0/1 loss
(3)macro-averaged F score
3.3 Method Setup

表一:每种方法在不同评价指标下的性能(均数±标准时间)
3.4 Performance

表三:根据不同的评价指标(5%显著性水平下的成对t检验),联合学习算法相对于原始预测-特征方法的win/tie/loss结果。
3.5 Time

表四:每种方法的平均训练时间(秒)
四、Conclusion
多标签文本分类是一种常用的文本分类方法。近年来,人们开发了一系列预测作为特征的方法,对高阶标签依赖关系进行建模,从而获得高性能。作为功能的谓词方法有一个缺点,即它们不能对当前标签和后一个标签之间的依赖关系建模。为了解决这一问题,我们提出了一种新的联合学习算法,允许反馈从后一个分类器传播到当前分类器。实验结果表明,该算法训练的模型优于原模型。
