论文地址:https://www.aclweb.org/anthology/D18-1485.pdf
文章代码:https://github.com/lancopku/SU4MLC
文章标题:Semantic-Unit-Based Dilated Convolution for Multi-Label Text Classificatio(基于语义单元的多标签文本分类的扩展卷积)
摘要
提出了一种基于序列学习的多标签文本分类新模型。该模型通过多层扩展卷积产生更高层次的语义单位表示,并产生相应的混合注意机制,在词级和语义单位级提取信息。我们设计的扩展卷积有效地降低了维数,并支持接受域的指数扩展而不丢失局部信息,而注意力过度注意机制能够从源环境中捕获更多的摘要相关信息。实验结果表明,与RCV1-V2和Renc-CECps数据集上的基线模型相比,该模型具有明显的优势,分析表明,该模型与确定性层次模型相比具有竞争力,对低频标签的分类具有更强的鲁棒性。
一、Introduction
多标签文本分类是指为给定的文本分配多个标签,这些标签可以应用于许多重要的实际应用程序。一个典型的例子是,网站上的新闻往往需要标签,以提高搜索和推荐的质量,这样用户就可以在较少干扰无关信息的情况下,高效地找到自己喜欢的信息。作为自然语言处理的一项重要任务,许多方法得到了应用,并逐渐取得了令人满意的效果。例如,基于机器学习的一系列方法在行业中得到了广泛的应用,如二元关联(Boutell et al., 2004)。
然而,这些方法不能模拟标签之间的内部相关性。为了捕获这种相关性,包括MLDT (Clare and King, 2001)、Rank-SVM (Elisseeff and Weston, 2002)、LP (Tsoumakas and Katakis, 2006)、ML-KNN (Zhang and Zhou, 2007)、CC (Read et al., 2011)在内的后续工作试图捕获这种关系,尽管这种关系显示出了改进,但仅仅捕获了低阶相关性。这一领域的一个里程碑是序列到序列学习在多标签文本分类中的应用(Nam et al., 2017)。序列-序列学习是关于从一种类型的序列到另一种类型的序列的转换,其最常见的架构是基于注意力的序列-序列(Seq2Seq)模型。基于注意力的Seq2Seq (Sutskever et al.,2014)模型最初设计用于神经机器翻译(NMT) (Bahdanau et al.,2014;Luong et al., 2015)。Seq2Seq能够对给定的源文本进行编码,并对新序列的表示进行解码以近似于目标文本,利用注意机制,解码器能够有效地提取重要的源信息,从而提高解码的质量。多标签文本分类可以看作是对给定源文本的目标标签序列的预测,可以用Seq2Seq对其进行建模。此外,它还能够使用深度递归神经网络(RNN)对源文本之间以及标签序列之间的高阶相关性进行建模。
然而,我们研究了基于注意的多标签文本分类的Seq2Seq模型(Nam et al., 2017),发现注意机制在该任务中并不像在其他NLP任务中一样发挥重要作用,如NMT和摘要归纳。在第3节中,我们展示了消融研究的结果,表明注意机制并不能提高Seq2Seq模型的性能。我们假设与神经机器翻译相比,神经多标签文本分类的要求是不同的。传统的注意机制从源上下文提取词级信息,对分类任务贡献不大。在文本分类中,人类通常是基于对源文本中显著意义的理解,而不是简单地根据词的层次信息来给文本贴上标签。
例如,关于文本”年轻男孩打篮球非常兴奋,显然他们享受竞争的乐趣”,它可以发现有两个突出的想法,“年轻的游戏”和“篮球比赛的快乐”,我们称之为“语义单位”的文本。语义单位,主要决定了文本可以分为目标类别“青年”和“体育”,而不是词汇层面的信息。
语义单位构成整个文本的语义。为了给文本分配合适的标签,该模型应该捕获源文本的核心语义单元,即与单词级信息相比级别更高的信息,然后根据其对语义单元的理解分配文本标签。然而,传统的注意机制侧重于从语义单元中提取信息,存在信息冗余和细节不相关的问题。
为了捕捉语义单位在源文本,我们分析文本,发现语义单位通常用短语或句子,结合其他文本单元的帮助。受用于摘要的全局编码的影响(Lin et al ., 2018),我们利用卷积神经网络(CNN)的力量来获取本地单词并且生成比单词更高级别的信息表示,如短语或句子。此外,为了解决长期依赖的问题,我们设计了一个文本的多层扩展卷积,以捕获局部相关和长期依赖,没有覆盖范围的损失,因为我们不应用任何形式的池化或跨步卷积。基于我们设计的模块和原始递归神经网络生成的注释,我们实现了混合注意力机制,目的是在不同的层次捕获信息,而且,它可以根据对语义单位的关注从源上下文中提取词级信息。
我们的贡献如下:
- 分析了传统的注意机制在多标签文本分类中的不足,提出了一种新的多层扩展卷积模型来捕获源文本中的语义单元。
- 实验结果表明,该模型在RCV1-v2和Ren-CECps数据集上的性能优于基准模型,与句子或短语确定性设置的层次模型相比具有较强的竞争力。
- 我们的分析表明,与传统的Seq2Seq模型相比,从源上下文提取有效信息的模型能够更好地预测低频标签,并且受标签序列先验分布的影响较小。
二、Attention-based Seq2Seq for Multi-label Text Classificatio(基于注意的Seq2Seq用于多标签文本分类)
如下图所示,只要标签数据中存在某些相关模式,多标签文本分类就有可能被视为序列预测的任务。由于标签之间的相关性,可以通过为标签序列分配某些标签排列并最大化子集精度来提高模型在此任务中的性能,这意味着标签排列和相应的基于注意力的Seq2Seq方法能够学习标签分类和标签相关性。通过最大化子集精度,该模型可以借助标签相关性信息提高分类性能。关于标签排列,一个简单的方法是根据频率的降序对标签数据重新排序,这显示了令人满意的效果(Chen等人,2017年)
多标签文本分类可以看作是一个Seq2Seq学习任务,具体如下:给定一个源文本x={x1,…,xn}与目标标签序列y={y1,…,ym},Seq2Seq模型去估计概率值P(y|x),P由Seq2Seq模型计算,该模型通常基于递归神经网络(RNN)。
编码器是双向长短时记忆(LSTM) (Hochreiter and Schmidhuber,1996),从两个方向对源文本x进行编码,并生成源注释hi,其中每个时间步长来自两个方向的注释被连接起来。具体来说,二者的计算如下:
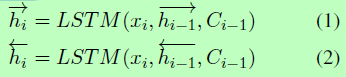
我们实现了一个单向LSTM解码器来连续生成标签。在每一步t时,解码器通过对目标标签集合Pvocab的分布进行采样,直至对表示句子结束的令牌进行采样,生成一个标签 yt,其中:
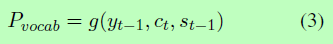
g(.)表示非线性函数,包括LSTM解码器、注意力机制以及用于预测的softmax函数。注意力机制产生ct,如下所示:
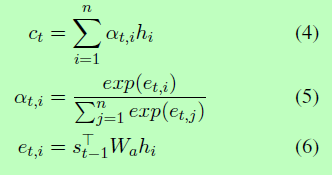
三、Problem
当我们分析多标签文本分类中注意机制的作用时,我们发现它对模型性能的改善作用很小。为了验证注意机制的效果,我们在多标签文本分类数据集RCV1-v2上进行了消融测试,比较没有注意机制的Seq2Seq模型和基于注意的SeqSeq模型的性能。
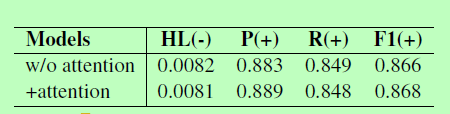
表一:Seq2Seq模型在RCV1-v2测试集上的表现,其中HL、P、R、F1分别为汉明损失、微精度、微召回和微F1。+ 表明越高越好,- 表示越低越好。
如表 1 所示,具有注意机制和无注意机制的 Seq2Seq 模型根据其micro-F1 分数在 RCV1-v2 上表现出类似的性能,这是多标签文本分类的重要评估指标。这可以证明,传统的注意机制在改进Seq2Seq模型的性能方面没有起到重要作用。我们假设传统的注意机制不符合多标签文本分类的要求。这种分类任务的一个常识是,分类应基于源文本的突出思想。语义单位,而不是字级信息,主要确定文本可以分为目标类别"青年"和"体育"。对于各种文本中的每一个,总是有语义单位来构造整个文本的语义含义。对于多标签文本分类的自动系统,系统应该能够提取源文本中的语义单元,从而在分类中提高性能。因此,我们提出解决这个问题的模型。
四、Proposed Method
接下来,我们将介绍我们提出的模块,以改进用于多标签文本分类的传统Seq2Seq模型。一般来说,它包含两个部分:多级扩展卷积(MDC)和混合注意机制。
4.1、Multi-level Dilated Convolution

图一:多级扩展卷积架构。核尺寸k = 2且扩展率为[1,2,3]的MDC的一个示例。为了避免网格化效应,扩展率只有一个公因数。
在原始编码器(在我们的模型中是LSTM)生成的表示法的基础上,我们应用多层卷积神经网络通过捕获单词之间的局部相关性和长期依赖性来生成语义单元的表示法。具体来说,我们的CNN是一个三层的一维CNN。沿着CNN在自然语言方向的先前工作进展(Kalchbrenner et al ., 2014),我们使用一维卷积与通道的数量等于隐藏层单元的数量,这样的信息在每个维度表示向量将不会断开连接,进行卷积。此外,由于我们要在源文本中捕获语义单位,而不是更高级的单词表示,因此不需要为卷积使用填充。
CNN的一个特殊设计是实现扩展卷积。近年来,扩展在计算机视觉的语义分割中得到广泛应用(Yu and Koltun, 2015;Wang et al., 2018),并被引入到NLP (Kalchbrenner et al., 2016)和语音处理(van den Oord et al., 2016)领域。扩展卷积是指在卷积中插入“孔”,以消除常用的降采样方法如maxpooling、strided convolution所带来的信息丢失等负面影响。此外,它可以在不增加参数的情况下,以指数的方式扩展接受域。因此,扩展的卷积有可能捕获长期依赖。此外,避免网格效应引起的扩展的目的(例如,扩张段的卷积内核可能导致丢失重要的本地相关和打破词表示)之间的连续性,我们实现一个多层次的扩展卷积与各级不同的扩展率,其中扩张率在我们的模型中是超参数。
我们使用不同扩展率的多级扩展卷积,而不是使用相同的扩展率或与公因式相同的扩展率,因为公因式会导致网格化效应。Wang等人(2018)研究了N层与核尺寸K的一维卷积,其扩展速率为[r1,…,rN],两个非零值之间的最大距离是max()。在我们的实验中,我们设置扩展率[1,2,3] ,K=3,M2 = 2。该实现可以避免网格化效应,并允许顶层在不损失覆盖范围的情况下在较长的距离之间访问信息。此外,可能会有无关信息的语义单位在很长一段距离,我们基于性能的验证精心设计了扩展率[1、2、3],而不是等[2、5、9],所以顶层不会处理信息中太长的距离,减少无关的信息的影响。因此,我们的模型可以从扩展率较小的短语级信息和扩展率较大的句子级信息生成语义单元表示。
4.2、Hybrid Attention

图二:混合注意结构。右下角的蓝色圆圈表示LSTM编码器生成的源注释,左下角的黄色圆圈表示MDC生成的语义单元表示,顶部的蓝色圆圈表示LSTM解码器输出。在每个解码时间步骤中,LSTM的输出首先处理语义单元表示,然后与高级信息合并的新表示形式将处理源注释。
由于我们有来自RNN编码器的注释和来自MDC的语义单元表示,所以我们设计了两种注意机制来评估不同层次信息的效果。一种是共同注意机制,它关注语义单位表示,而不是传统意义上的源词注释;另一种是我们设计的混合注意机制,融合了两个层次的信息。
混合注意的想法是由记忆网络(Sukhbaatar et al., 2015)和多步注意(Gehring et al., 2017)激发的。它可以看作是多“跳”的注意机制,第一跳负责高级语义单位信息,第二跳负责基于解码的低级语义单位信息,第一跳负责语义单位信息。详情如下。
对于解码器在每个时间步的输出,它不仅像通常那样处理来自RNN编码器的源注释,还处理来自MDC的语义单元表示。在我们的模型中,解码器输出首先关注来自MDC的语义单元表示,以找出最相关的语义单元,并根据这些语义单元生成新的表示。接下来,带有解码过程的信息以及对语义单元的关注的新表示形式将关注LSTM编码器的源注释,以便通过语义单元的指导从源文本中提取字级信息,缓解不相关和冗余问题。
具体来说,对于来自LSTM编码器的源注释h={h1,…,hn}与语义单元表示形式g={g1,…,gm},解码器输出st首先关注语义单元表示g,生成一个新的表示s‘t,然后新的表示s’t关注源注释h,根据上述相同的注意机制生成另一个表示~st。在最后一步,模型生成ot用于yt的预测,其中:

为了比较,我们还提出了另一种类型的注意,称为“附加注意”,其实验结果在消融试验中。在该机制中,而不是关注这两种类型的表示如上所述,一步一步LSTM译码器的输出st参加语义单元表示g和源代码注释h分别生成s’t和~st,最后为最终输出添加元素。
五、Experiment Setup
接下来,我们将介绍数据集和我们的实验设置,以及我们所比较的基线模型。
5.1、Datasets and Preprocessing
Reuters Corpus Volume I (RCV1-v2):数据集(Lewis等人,2004年)由路透社有限公司为研究目的手动分类的80多万条新闻通讯社故事组成,其中每个故事都分配了多个主题。主题总数为 103。具体来说,训练集包含大约 802414 个样本,而开发集和测试集分别包含 1000 个样本。我们筛选数据集中长度超过 500 字的样本,从而删除训练、开发和测试集中大约 0.5% 的样本。词汇量设置为 50k 字。数字和词汇外词被特殊标记"*"和"UNK"所掩盖。对于标签排列,我们按 Kim (2014) 之后按频率应用降序。
Ren-CECps:数据集为中文博客中的一个句子语料库,标注了8个情绪标签:愤怒、焦虑、期待、憎恨、喜悦、爱、悲伤、惊讶,3个极性标签:正、负、中性。数据集包含35096个句子用于多标签文本分类。我们对与RCV1-v2类似的数据进行预处理,即过滤500多个单词的样本,将词汇量设置为50k,并对标签排列按频率降序排列。
5.2、Experiment Settings
我们在一个NVIDIA 1080Ti GPU上用PyTorch实现了我们的实验。在实验中,批量大小设置为64,嵌入大小和隐藏层单元数为512。 优化函数采用Adam (Kingma Ba, 2014 )。基于开发集的性能,初始化学习速率为0.0003,经过每个阶段的训练后,学习速率减半。梯度裁剪的范围是[- 10,10]。
在前人研究的基础上(Zhang and Zhou, 2007;Chen et al., 2017),我们选择hamming loss和micro-F1 score来评价我们的模型的性能。Hamming loss是指错误预测的分数(Schapire and Singer, 1999), micro-F1分数是指加权平均F1分数。为参考,还报告了微精度和微回忆分数。具体到汉明损失(Hamming Loss, HL)微f1分数的计算如下:

5.3、Baseline Models
- BR
- CC
- LP
- CNN
- CNN-RNN:利用CNN和RNN捕获全局和局部文本语义和模型标签相关性。
- S2S 和 S2S+Attn:我们实现的基于rnn的序列-序列模型分别没有注意机制和有注意机制。
六、Results and Discussion

在接下来的章节中,我们将报告我们在RCV1-v2和rencecps上的实验结果。此外,我们进行了消融测试,并与具有句子或短语确定性设置的层次模型模型进行了比较,以说明我们的具有可学习语义单元的模型比基线模型具有明显的优势。此外,我们证明了更高层次的表示法对于预测数据集中低频的标签是有用的,因此它可以确保模型没有严格学习标签序列的先验分布。
6.1、Results
我们在表2中展示了模型实现的结果以及RCV1-v2上的基线。从传统的基线结果可以发现,与基于机器学习甚至深度学习的方法相比,传统的多标签文本分类方法仍然具有竞争力,而不是基于seq2seq的模型。对于Seq2Seq模型,与上面的基线相比,S2S和S2S+Attn都在数据集上实现了改进。但是,如前所述,注意机制在多标签文本分类的Seq2Seq模型中并没有发挥重要作用。与此相反,我们提出的基于标签分类的机制可以同时考虑语义单位和词单位的信息。与S2S+Attn相比,我们提出的模型在评估汉明损失和微f1评分方面表现最好,减少了9.8%的汉明损失,提高了1.3%的微f1评分。
同时也介绍了我们的实验结果。与RCV1-v2模型的表现相似,除了Seq2Seq模型外,传统的基线在微f1评分评价上的表现不如Seq2Seq模型。此外,S2S和S2S+Attn在该数据集上的micro-F1性能仍然相似,我们提出的模型在提高了0.009 micro-F1分数的情况下,取得了最好的性能。一个有趣的发现是,Seq2Seq模型在评估汉明损失时并不比传统的基线具有优势。我们观察到rencecps中的标签比RCV1-v2中的少(11和103)。由于我们的标签数据是按照标签频率的降序重新排序的,所以Seq2Seq模型更倾向于了解频率分布,类似于长尾分布。但是,对于只有少量样本的低频标签,它们的数量是相似的,其分布比整个标签数据的分布更加均匀。与传统的基线相比,当模型接近长尾分布时,Seq2Seq模型很难对其进行正确的分类。由于汉明损失反映的是平均不正确预测,因此,与micro-F1分数相比,将汉明损失分类为低频标签的错误将导致汉明损失的急剧增加。
6.2、Ablation Test(消融实验)

为了评估我们提出的模块的效果,我们对我们的模型进行了消融试验。我们删除了某些模块来控制变量,这样它们的效果可以比较公平。具体来说,除了第3节中提到的常规注意机制的评估外,我们还评估了混合注意及其模块的效果。我们展示5个模型的性能与不同关注实现比较,模型没有注意,一个只关注从LSTM源代码注释,一个只关注语义单元表示从争取民主变革运动,注意源的注释和语义单元表示(添加剂)和混合的注意,分别。因此,我们提出的每个模块的效果,包括MDC和混合注意力,都可以单独评估,而不受其他模块的影响。
表4的结果表明,与其他类型的注意机制模型相比,我们的模型仍然表现最好。除了上述常规注意机制的影响不显著外,我们还可以发现,MDC生成的高层表示对多标签文本分类的Seq2Seq模型的性能有很大的贡献,提高了约0.9个micro-F1分数。另外,简单的加性注意机制相当于将MDC的表示与常规机制的表示进行元素添加,其性能与单一的MDC相似,也说明了该任务中常规注意机制的贡献较小。我们提出的混合注意是两种机制相对复杂的结合,可以提高MDC的性能。这表明,尽管传统的关注也能进行信息机制不显著影响SeqSeq模型的性能,混合的关注中提取信息也能进行基于生成的高层语义信息可以提供一些相关的重要细节信息最贡献语义单位。
6.3、Comparison with the Hierarchical Models(与层次模型进行比较)
另一种可以提取高级表示的方法是一种启发式方法,它首先手工注释句子或短语,然后对高级表示应用层次模型。具体来说,该方法不仅将RNN编码器应用于单词表示,还应用于句子表示。在重新实现,我们把表示从LSTM编码器的时间步每个句子句子表示,年底我们之上实现另一个LSTM最初的编码器接收句子表示作为输入,这样整个编码器可以分级。我们在数据集RCV1-v2上实现了实验。由于RCV1-v2数据集中没有句子标记,我们为源文本设置了句子边界,并应用层次模型来生成句子表示。
与我们提出的MDC相比,用于高级表示的层次模型是相对确定的,因为句子或短语是手动预定义的。但是,我们提出的MDC通过扩展卷积学习高级表示,它不受人工标注边界的限制。通过评估,我们希望看到我们的多层扩展卷积模型以及混合注意是否可以达到与分层模型相似或更好的性能。此外,我们注意到分层模型的参数数量比我们的模型多,分别为47.24M和45.13M。因此,很明显,我们的模型在比较中不具备参数数的优势。

我们给出了表5的评价结果,其中可以发现,我们的模型参数较少,仍然优于句子或短语确定性设置的层次模型。此外,为了减轻确定性句子边界的影响,我们将不同层次模型的性能与不同边界进行了比较,分别设置了每5个、10个、15个和20个单词的边界。表5的结果表明,层次模型的性能相似,均高于基线的性能。这表明,高级表示有助于Seq2Seq模型在多标签文本分类任务上的性能。此外,由于这些性能并不比我们提出的模型更好,它可以反映出可学习的高级表示比确定性语句级表示的贡献更大,因为它可以更灵活地表示不同层次的信息,而不是固定的短语或句子层次。
6.4、Error Analysis(误差分析)
我们实验的另一个发现是,该模型在低频标签分类上的性能低于高频标签分类。这个问题也反映在我们对renc - cecps的实验结果报告中。性能的下降是合理的,因为模型对数据量很敏感,特别是对于像rencecps这样的小数据集。我们还假设这个错误来自于Seq2Seq模型的本质。由于我们的标签数据的频率类似于长尾分布,并且数据是按照标签频率的降序排列的,所以Seq2Seq模型更倾向于对该分布进行建模。由于低频标签的频率分布比较均匀,因此很难对其进行建模。
相比之下,由于我们的模型能够为标签分类捕获更深层次的语义信息,因此我们认为,借助来自多个层次的信息,我们的模型对低频标签的分类具有更强的鲁棒性。随后,我们删除了10、20、30、40、50和60个最常见的标签,并评估了我们的模型和基线Seq2Seq模型在这些标签分类上的性能。图3显示了模型对不同频率标签数据的结果。很明显,虽然两种模型的性能都随着标签频率的降低而下降,但我们的模型在标签频率的各个水平上都比基线表现得更好。此外,随着标签频率的降低,两种模型的性能差距不断增大,说明我们的模型在低频标签的分类上优于基线。
七、Related Work
目前多标签分类任务的模型可分为三类:问题转换方法、算法适应方法和神经网络模型。
问题转换方法将多标签分类任务分解为多个单标签学习任务。BR算法(Boutell et al.,2004)为每个标签构建一个单独的分类器,导致标签相关性被忽略。为了对标签相关性进行建模,label Powerset (Tsoumakas和Katakis,2006)为训练集中验证的每个标签组合创建一个二元分类器,而classifier Chains (Read et al.,2011)通过特征空间将链中的所有分类器连接起来。
算法适应方法对多标签分类任务采用特定的学习算法,不需要进行问题转换。Clare and King(2001)构建了基于多标签熵的决策树进行分类。Elisseeff和Weston(2002)采用支持向量机类学习系统来处理多标签问题。Zhang和Zhou(2007)利用k近邻算法和极大后验原理确定每个样本的标签集。F¨urnkranz等人(2008)利用成对比较对标签进行排序。Li等人(2015)使用联合学习预测作为特征。
近年来,多标签文本分类的研究转向了神经网络的应用,在自然语言处理方面取得了很大的成功。Zhang和Zhou(2006)实现了具有成对排序损失函数的全连通神经网络。Nam et al.(2013)为了更好地训练,将排名损失函数改为交叉损失函数。Kurata等人(2016)提出了一种新的神经网络初始化方法,将一些神经元作为专用神经元来进行模型标签关联。Chen等人(2017)将CNN和RNN结合起来,捕捉全局和局部语义信息,并对高阶标签相关性进行建模。(Nam et al., 2017)提出按顺序生成标签,Yang等(2018);Li等(2018)都采用了Seq2Seq,一个采用了新的解码器,另一个采用了软损失函数。
八、Conclusion
本研究提出了基于多级扩展卷积和混合注意机制的模型,该模型可以提取语义单位级信息和字级信息。实验结果表明,我们提出的模型可以显著优于基线模型。此外,分析表明,我们的模型与确定性分层模型具有竞争力,对低频标签进行分类比基线更有力。