论文链接:
论文目的:
对于极度多标签文本分类进行解决,这里总的的标签量一般超过1000(可以更多)。
模型结构:
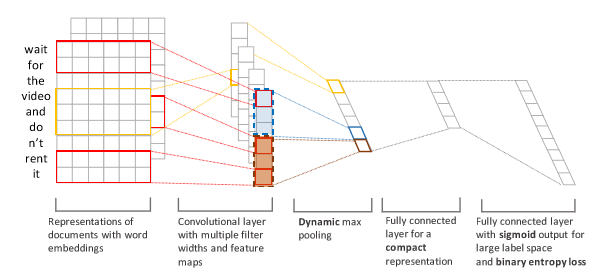
此模型基于CNN-Kim(即一般的TextCNN)有两点改进。
一方面是对于文本卷积层,将Kim的对整个文本序列的max-pooling层进行分块(dynamicpooling),即将原来的待pooling序列沿文本方向分成若干子块,对这些子块pooling之后,再将子块pooling的结果进行拼接来传入后续神经层,想法是这样处理后能提取更多的文本特征。
另一方面是在损失函数处使用binarycross-entropy 代替一般多标签分类常用的softmax cross-entropy。(用sigmoid 代替 softmax)

模型结构图:
测试数据:
数据来源:
https://www.kaggle.com/stackoverflow/stacksample
数据说明:
这份数据是stock overflow的一份QA数据,这里仅用到其中的文本部分,即Question
Answer TitleTags。将其抽象成文本多分类问题,即
自变量集合Question Answer Title
因变量集合 Tags
选择这部分数据从模型角度的原因是其Tags集合标签总数多于10000个,符合极度多标签分类的定义,另一方面这是一个QA数据集,除了文本分类问题外还可以做一些QA及记忆网络的尝试。(从关于模型的描述可以看出,模型并非十分复杂,但经过一些数据处理过程可以让我们在QA或其它场景应用处理过的数据集)
数据处理:
数据源包含文件 Questions.csv Answers.csv Tags.csv
数据为英文数据,会涉及到一些简单的数据处理。
数据清洗:
import pandas as pd
from dl_text import dl
import re
import gc
from collections import defaultdict
from functools import reduce
def cleanhtml(raw_html):
if not raw_html:
return ""
cleanr = re.compile('<.*?>')
cleantext = re.sub(cleanr, '', raw_html)
return cleantext
def lower_tokenize(text):
return dl.tokenize(dl.clean(cleanhtml(text).lower()))
这里包含了去掉html标签及使用dl库将英文的一些常用简写映射进行分离的操作(如I’ve 到I have等)。
用于训练的embedding既可以使用glove也可以用word2vec,调用
https://github.com/GradySimon/tensorflow-glove
可以如下获得glove-embedding(不支持partial predict的更新估计方式且较为占内存,优化一般)
def train_glove_embedding(pre = True):
if pre:
def row_process(df, min_seq_len = 100, max_r = 5e10):
have_count = 0
for r, row in df.iterrows():
if r % 10000 == 0:
print("r %d final" % (r,))
if have_count > max_r:
return
tokens = lower_tokenize(row["Body"])
if len(tokens) > min_seq_len:
have_count += 1
yield tokens
q_df = pd.read_csv("Questions.csv", encoding="latin1")[["Body"]]
a_df = pd.read_csv("Answers.csv", encoding="latin1")[["Body"]]
q_g = row_process(q_df, min_seq_len=100)
del q_df
a_g = row_process(a_df, min_seq_len=100)
del a_df
with open("corpus.txt", "w") as f:
for tokens in q_g:
if tokens:
f.write(" ".join(tokens) + "\n")
del q_g
for tokens in a_g:
if tokens:
f.write(" ".join(tokens) + "\n")
del a_g
gc.collect()
return
corpus = []
with open("corpus.txt") as f:
while True:
line = f.readline()
if not line:
break
corpus.append(line.split(" "))
if len(corpus) >= 1e5:
break
print("length {}".format(len(corpus)))
from glove_embed import tf_glove
model = tf_glove.GloVeModel(embedding_size=300, context_size=10, min_occurrences=1,
learning_rate=0.05, batch_size=512)
model.fit_to_corpus(corpus)
model.train(num_epochs=100)
with open("glove_embed.txt", "w") as f:
for i ,word in enumerate(model.words):
if i % 10000 == 0:
print("file serlize {} end".format(i))
f.write("{}\t{}\n".format(word, " ".join(model.embedding_for(word).astype(str).tolist())))
或者如下使用word2vec
def train_w2v_embedding():
from gensim.models import Word2Vec
w2v_path = "w2v.model"
w2v_model = None
embed_size = 300
num_epoch = 10
for epoch in range(num_epoch):
with open("corpus.txt") as f:
corpus = []
while True:
line = f.readline()
if not line:
break
if len(corpus) < 5e4:
corpus.append(line.split(" "))
else:
if w2v_model is None:
w2v_model = Word2Vec(corpus, size=embed_size ,min_count=1, workers=4, iter = 10)
else:
w2v_model = Word2Vec.load(w2v_path)
w2v_model.train(corpus, total_examples = len(corpus), epochs = 10)
w2v_model.save(w2v_path)
corpus = []
print("one train iter end")
print("epoch {} end".format(epoch))
wv = w2v_model.wv
with open("w2v_embed.txt", "w") as f:
for word in wv.vocab.keys():
f.write("{}\t{}\n".format(word, " ".join(wv[word].astype(str).tolist())))
下面实现Questions.csv Answers.csv Tags.csv 的数据合并
def classifier_process(first_time = False):
q_columns = ["Id", "Body", "Title"]
a_columns = ["ParentId", "Body"]
tag_columns = ["Id", "Tag"]
# use half datasets (6e5) two times
if first_time:
q_df = pd.read_csv("Questions.csv", nrows=6e5, encoding="latin1")[q_columns]
else:
q_df = pd.read_csv("Questions.csv", encoding="latin1")[q_columns]
q_df = q_df.iloc[int(6e5):]
q_c = q_df.columns.tolist()
q_c[q_c.index("Body")] = "q_Body"
q_df.columns = q_c
a_df = pd.read_csv("Answers.csv", nrows=1e100, encoding="latin1")[a_columns]
a_c = a_df.columns.tolist()
a_c[a_c.index("Body")] = "a_Body"
a_c[a_c.index("ParentId")] = "Id"
a_df.columns = a_c
X_df = pd.merge(q_df, a_df, how = "inner", on = "Id")
del a_df
del q_df
gc.collect()
print("X_df merge")
X_df_constuct = defaultdict(list)
unique_column = X_df.columns.tolist()
unique_column.remove("a_Body")
X_df_groupby_id = list(X_df.groupby("Id"))
for group_df_idx in range(len(X_df_groupby_id)):
group_df = X_df_groupby_id[group_df_idx][-1]
for col in unique_column:
X_df_constuct[col].append(group_df[col].tolist()[0])
X_df_constuct["a_Body"].append(reduce(lambda x,y: x + y, group_df["a_Body"]))
X_df = pd.DataFrame.from_dict(X_df_constuct)
del X_df_constuct
gc.collect()
print("X_df unique")
tag_df = pd.read_csv("Tags.csv", nrows=1e100, encoding="latin1")[tag_columns]
y_df_construct = defaultdict(list)
for r_index, row in tag_df.iterrows():
y_df_construct[row["Id"]].append(row["Tag"])
tag_df_construct = defaultdict(list)
for k, v in y_df_construct.items():
tag_df_construct["Id"].append(k)
tag_df_construct["Tags"].append(v)
del tag_df
gc.collect()
print("tag_df unique")
y_df = pd.DataFrame.from_dict(tag_df_construct)
X_y_df = pd.merge(X_df, y_df, how = "inner", on = "Id")
del X_df
del y_df
gc.collect()
print("feature prepare start")
with open("X_y_file_6e5_1.txt", "w") as f:
for r_index, row in X_y_df.iterrows():
body_text = row["q_Body"] if row["q_Body"] else ""
q_body_tokenize = lower_tokenize(body_text)
body_text = row["a_Body"] if row["a_Body"] else ""
a_body_tokenize = lower_tokenize(body_text)
title_text = row["Title"] if row["Title"] else ""
title_tokenize = lower_tokenize(title_text)
f.write("{}\t{}\t{}\t{}\n".format(" ".join(q_body_tokenize),
" ".join(a_body_tokenize) , " ".join(title_tokenize), " ".join(filter(lambda x: x if type(x) is str else None,row["Tags"]))))
if r_index % 10000 == 0:
print("feature_prepare {} end".format(r_index))
在这里我们设定对于1000个最常见的Tag的多分类,下面根据这个分类目标进行样本过
滤,删去较少出现的Tag对应样本
# use this script to identify used tags num
def eval_tag_count():
all_list = []
from collections import Counter
with open("X_y_file_6e5_0.txt") as f:
while True:
line = f.readline()
if not line:
break
all_list.extend(line.split("\t")[-1].replace("\n", "").split(" "))
with open("X_y_file_6e5_1.txt") as f:
while True:
line = f.readline()
if not line:
break
all_list.extend(line.split("\t")[-1].replace("\n", "").split(" "))
cnt = Counter(all_list)
print("min_count :{}".format(min(map(lambda x: x[1] ,cnt.most_common(10)))))
most_common_keys = list(map(lambda x: x[0] ,cnt.most_common(10)))
with open("X_y_file_12e5_10.txt", "w") as o:
o_num = 0
with open("X_y_file_6e5_0.txt") as f:
while True:
line = f.readline()
if not line:
break
tags = list(filter(lambda x: x if x in most_common_keys else None,line.split("\t")[-1].replace("\n", "").split(" ")))
if tags:
o_num += 1
if o_num % 10000 == 0:
print("o_num: {}".format(o_num))
fs, s, t, _ = line[:-1].split("\t")
o.write("{}\t{}\t{}\t{}\n".format(fs, s, t, " ".join(tags)))
with open("X_y_file_6e5_1.txt") as f:
while True:
line = f.readline()
if not line:
break
tags = list(filter(lambda x: x if x in most_common_keys else None,line.split("\t")[-1].replace("\n", "").split(" ")))
if tags:
o_num += 1
if o_num % 10000 == 0:
print("o_num: {}".format(o_num))
fs, s, t, _ = line[:-1].split("\t")
o.write("{}\t{}\t{}\t{}\n".format(fs, s, t, " ".join(tags)))
最后对文本进行编码,为送入网络做准备:
def classifier_prepare():
from gensim.models import Word2Vec
w2v_path = "w2v.model"
w2v_model = Word2Vec.load(w2v_path)
wv = w2v_model.wv
words = list(wv.vocab.keys())
# set padding and unknown <unk> idx len(words), <pad> idx len(words) + 1
word2idx = dict([(w, i) for i, w in enumerate(words)] + [("<unk>", len(words)) ,("<pad>", len(words) + 1)])
tags_set = set([])
with open("X_y_file_12e5_10.txt") as f:
while True:
line = f.readline()
if not line:
break
tags_set = tags_set.union(set(line.split("\t")[-1][:-1].split(" ")))
tag2idx = dict((t, i) for i, t in enumerate(tags_set))
def map_to_idx(input_str):
return " ".join(map(lambda x: str(word2idx.get(x, word2idx["<unk>"])), input_str.split(" ")))
def map_to_tdx(input_str):
return " ".join(map(lambda x: str(tag2idx[x]), input_str.split(" ")))
# test_ratio = 0.2
with open("classifier_10_test.txt", "w") as test_o:
with open("classifier_10_train.txt", "w") as train_o:
with open("X_y_file_12e5_10.txt") as f:
line_num = 0
while True:
line = f.readline()
if not line:
break
fs, s, t, ff = line[:-1].split("\t")
if line_num % 10 >= 8:
test_o.write("{}\t{}\t{}\t{}\n".format(*(list(map(map_to_idx, [fs, s, t])) + [map_to_tdx(ff)])))
else:
train_o.write("{}\t{}\t{}\t{}\n".format(*(list(map(map_to_idx, [fs, s, t])) + [map_to_tdx(ff)])))
line_num += 1
if line_num % 10000 == 0:
print("line_num :{}".format(line_num))
import numpy as np
print("total embed num :{}".format(len(word2idx)))
embed_array = np.zeros(shape=[len(word2idx), 300])
embed_over_num = 0
for w, i in word2idx.items():
if w in words:
embed_array[i] = wv[w]
else:
embed_array[i] = np.random.random(size=300)
embed_over_num += 1
if embed_over_num % 1000 == 0:
print("embed {} end".format(embed_over_num))
print("embed_array end")
import pickle
with open("embed_and_idx_10.pkl", "wb") as f:
pickle.dump(
{
"embed_array": embed_array,
"word2idx": word2idx,
"tag2idx": tag2idx
}, f
)
print("dump end")
数据导出(训练用导出数据函数)
import tensorflow as tf
import numpy as np
import pickle
with open("embed_and_idx.pkl", "rb") as f:
d = pickle.load(f)
word2idx = d["word2idx"]
tag2idx = d["tag2idx"]
embed_array = d["embed_array"]
padding_idx_s = str(word2idx["<pad>"])
def data_generator(gen_type = "train" ,batch_num = 64, padding_size = 1000, tag_num = 1000,
category_limit = False):
assert gen_type in ["train", "test"]
def generate_int_array(input_str):
input_list = input_str.split(" ")[:padding_size]
return np.array(input_list + [padding_idx_s] * (padding_size - len(input_list))).astype(np.int32)
def generate_tag_array(input_str):
input_list = list(map(int, input_str.split(" ")))
req = [0] * tag_num
for tag in input_list:
req[tag] = 1
return np.array(req).astype(np.float32)
start_idx = 0
q_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
a_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
t_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
tag_batch_array = np.zeros(shape=[batch_num, tag_num]).astype(np.float32)
times = 0
with open("classifier_{}.txt".format(gen_type)) as f:
while True:
line = f.readline()
if not line:
return
fs, s, t, ff = line[:-1].split("\t")
tag_array = generate_tag_array(ff)
if category_limit:
if np.sum(tag_array) > 1 or np.argmax(tag_array) not in [0, 1]:
continue
else:
sum_tag_array = np.sum(tag_array).astype(np.float32)
tag_array = tag_array / sum_tag_array
q_batch_array[start_idx] = generate_int_array(fs)
a_batch_array[start_idx] = generate_int_array(s)
t_batch_array[start_idx] = generate_int_array(t)
tag_batch_array[start_idx] = tag_array
start_idx += 1
if start_idx == batch_num:
times += 1
if times == 1e10:
return
yield (q_batch_array, a_batch_array, t_batch_array, tag_batch_array)
start_idx = 0
q_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
a_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
t_batch_array = np.zeros(shape=[batch_num, padding_size]).astype(np.int32)
tag_batch_array = np.zeros(shape=[batch_num, tag_num]).astype(np.float32)
模型构建:
模型的基本结构为对QuestionAnswer Title 三部分直接拼接后送入分类模型:
class XML_CNN(object):
def __init__(self, embedding_array, max_seq_len = 1000, num_filters = 3, output_channels = 3,
filter_sizes = [3, 4, 5] ,
dense_dnn_size = [100],
p = 10, class_num = 1000, w2v_dim = 100):
# param init
self.w2v_dim = w2v_dim
self.max_seq_len = max_seq_len
self.embedding_array = tf.Variable(embedding_array[:, :self.w2v_dim], name="embed_array")
self.filter_sizes = filter_sizes
self.num_filters = num_filters
self.output_channels = output_channels
assert len(dense_dnn_size) == 1
self.dnn_layer_dim = dense_dnn_size[0]
self.q_seq = tf.placeholder(dtype=tf.int32, shape=[None, self.max_seq_len], name="q_deq")
self.a_seq = tf.placeholder(dtype=tf.int32, shape=[None, self.max_seq_len], name="a_seq")
self.t_seq = tf.placeholder(dtype=tf.int32, shape=[None, self.max_seq_len], name="t_seq")
self.input_seq = tf.concat([self.q_seq, self.a_seq, self.t_seq], axis = -1, name="input_seq")
self.tag_seq = tf.placeholder(dtype=tf.float32, shape=[None, class_num], name="tag_seq")
self.p = p
self.class_num = class_num
self.keep_prob = tf.placeholder(dtype=tf.float32, name="keep_prob")
# construct
self.model_construct()
self.opt_construct()
def model_construct(self):
# input layer
with tf.variable_scope("embed"):
self.embed_seq = tf.nn.embedding_lookup(self.embedding_array, self.input_seq)
self.embedded_content_expanded = tf.cast(tf.expand_dims(self.embed_seq, -1, name="embedded_content_expanded"), tf.float32)
pooled_outputs = []
for i, filter_size in enumerate(self.filter_sizes):
temp_pooled_outputs = []
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, self.w2v_dim, 1, self.num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name='W')
b = tf.Variable(tf.constant(0.0, shape=[self.num_filters]), name='b')
conv = tf.nn.conv2d(
self.embedded_content_expanded,
W,
strides=[1, 1, 1, 1],
padding='VALID',
name='conv')
h = tf.nn.sigmoid(tf.nn.bias_add(conv, b), name='relu')
m = int(h.get_shape()[-3])
m_d_p = int(m / self.p)
m_bar = int(m_d_p * self.p)
h = tf.slice(h, [0, 0, 0, 0], [-1, m_bar ,-1, -1])
m = int(h.get_shape()[-3])
index_list = list(range(0, m, m_d_p))
if m not in index_list:
index_list.append(m)
for i in range(len(index_list) - 1):
start = index_list[i]
slice_val = tf.slice(h, [0, start, 0, 0], [-1, m_d_p ,-1, -1], name="slice_{}".format(i))
pooled = tf.nn.max_pool(
slice_val,
ksize=[1, m_d_p - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name='pool_{}'.format(i))
temp_pooled_outputs.append(pooled)
# Combine all the pooled features
content_pool = tf.concat(temp_pooled_outputs, 3)
num_filters_total = int(content_pool.get_shape()[-1]) * int(content_pool.get_shape()[-3])
content_pool_flat = tf.reshape(content_pool, [-1, num_filters_total])
pooled_outputs.append(content_pool_flat)
self.content_pool_flat = tf.concat(pooled_outputs, -1)
with tf.name_scope("low_rank"):
W = tf.get_variable(
"low_W",
shape=[int(self.content_pool_flat.get_shape()[-1]), self.dnn_layer_dim],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[self.dnn_layer_dim]), name="low_b")
self.dnn_layer_out = tf.nn.xw_plus_b(self.content_pool_flat, W, b)
with tf.name_scope("dropout"):
self.dropout_layer_out = tf.nn.dropout(self.dnn_layer_out, keep_prob=self.keep_prob, name="drop_keep_prob_layer")
with tf.name_scope("final_layer"):
W = tf.get_variable(
"final_W",
shape=[int(self.dropout_layer_out.get_shape()[-1]), self.class_num],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[self.class_num]), name="final_b")
self.final_layer = tf.nn.xw_plus_b(self.dropout_layer_out, W, b)
self.softmax_pred = tf.nn.softmax(self.final_layer)
self.predictions = tf.argmax(self.final_layer, 1, name="predictions")
def opt_construct(self, use_bec = False):
logits = self.final_layer
labels = self.tag_seq
if use_bec:
self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels), name="loss")
else:
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels), name="loss")
self.opt = tf.train.AdamOptimizer(learning_rate=0.001)
self.train_op = self.opt.minimize(self.loss)
self.predictions = tf.argmax(self.softmax_pred, 1, name="predictions")
# Accuracy
with tf.name_scope("accuracy"):
self.tag_eval = tf.cast(self.tag_seq > 0, tf.float32)
self.tag_row_sum = tf.reduce_sum(self.tag_eval, axis=1)
self.pred_onehot = tf.one_hot(self.predictions, depth=self.class_num)
greedy_correct_predictions = tf.reduce_prod(tf.cast(tf.subtract(self.tag_eval, self.pred_onehot) >= 0, tf.float32), axis=1)
self.greedy_accuracy = tf.reduce_mean(tf.cast(greedy_correct_predictions, "float"), name="accuracy")
correct_predictions = tf.equal(self.predictions, tf.argmax(self.tag_seq, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
@staticmethod
def train():
xml_cnn_ext = XML_CNN(embed_array)
tg = data_generator(gen_type="train")
ttg = data_generator(gen_type="test", batch_num=300)
num_epoch = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for now_epoch in range(num_epoch):
step = 0
while True:
try:
q_batch_array, a_batch_array, t_batch_array, tag_batch_array = tg.__next__()
except:
tg = data_generator(gen_type="train")
ttg = data_generator(gen_type="test", batch_num=300)
print("epoch {} end".format(now_epoch))
break
_, loss, accuracy, greedy_accuracy = sess.run([xml_cnn_ext.train_op ,xml_cnn_ext.loss, xml_cnn_ext.accuracy, xml_cnn_ext.greedy_accuracy
],
feed_dict={
xml_cnn_ext.q_seq: np.zeros(q_batch_array.shape).astype(np.float32),
xml_cnn_ext.a_seq: np.zeros(q_batch_array.shape).astype(np.float32),
xml_cnn_ext.t_seq: t_batch_array,
xml_cnn_ext.tag_seq: tag_batch_array,
xml_cnn_ext.keep_prob: 0.7
})
if step % 10 == 0:
print("step: {}, train loss: {} acc: {} gred_acc: {}".format(step ,loss, accuracy, greedy_accuracy))
if step % 100 == 0:
try:
q_batch_array, a_batch_array, t_batch_array, tag_batch_array = ttg.__next__()
except:
ttg = data_generator(gen_type="test", batch_num=1000)
q_batch_array, a_batch_array, t_batch_array, tag_batch_array = ttg.__next__()
loss, accuracy, greedy_accuracy = sess.run([xml_cnn_ext.loss, xml_cnn_ext.accuracy, xml_cnn_ext.greedy_accuracy],
feed_dict={
xml_cnn_ext.q_seq: np.zeros(q_batch_array.shape).astype(np.float32),
xml_cnn_ext.a_seq: np.zeros(q_batch_array.shape).astype(np.float32),
xml_cnn_ext.t_seq: t_batch_array,
xml_cnn_ext.tag_seq: tag_batch_array,
xml_cnn_ext.keep_prob: 1.0
})
print("test loss: {} acc: {} gred_acc: {}".format(loss, accuracy, greedy_accuracy))
step += 1
由于是多标签分类(一个样本可能有多个Tag),在accuracy层使用self.greedy_accuracy表征至少击中一个标签类别的情况,而self.accuracy则更多的是一种“随机”的准确率。
在p=1且use_bec=False时就对应一般的Kim-CNN。在该数据集上使用softmax的情况要好于sigmoid。在这种极度多标签情形(Tags 数量设定1000),使用dynamic pooling如p=10与p=1精确度及收敛结果类似(精度在0.6左右稳定),当减少Tags数量,如设定只有10分类时,p=1明显好于p=10。