摘要
受人类如何总结长文档的启发,我们提出了一种准确而快速的摘要模型,该模型首先选择重要的句子,然后抽象地重写它们(即压缩和复述)以生成简洁的总体摘要。我们使用一种新的句子级策略梯度方法,以一种分层的方式桥接这两个神经网络之间的不可微计算,同时保持语言的流畅性。从经验上讲,我们在CNN/Daily Mail数据集的所有指标(包括人工评估)上都达到了最新的最新水平,并且抽象度得分明显更高。此外,通过首先在句子级别然后在单词级别进行操作,我们可以对神经生成模型进行并行解码,与先前的长段落编码器-解码器模型相比,神经生成模型的推理速度大大提高(10-20倍),训练收敛速度也快4倍。我们还展示了我们的模型在仅测试的DUC2002数据集上的推广,在该数据集上,我们获得的分数比最新模型高。
1.介绍
文档摘要的任务有两个主要范例:抽取式和生成式。前一种方法直接选择并输出原始文档中的重要句子(或短语)。 后者的生成方法涉及重写摘要,并且由于神经序列到序列模型近期获得了重大进展。通过从头开始执行生成,生成式模型可能更简洁,但是对于长文档,它们可能会导致编码速度慢和不准确,而注意力模型则需要查看所有编码后的单词才能对每个生成的摘要单词进行解码。生成模型还存在冗余(重复)的问题,尤其是在生成多语句摘要时。
为了解决这两个问题并结合两种方法的优势,我们提出了一种混合的抽取-生成式架构,并结合了基于策略的强化学习(RL)以将两个网络桥接在一起。与人类总结长文档的方式类似,我们的模型首先使用抽取器agent选择重要的句子或突出显示的内容,然后使用生成器网络重写(即压缩和释义)每一个被抽取的句子。为了解决抽取器的不可微分的问题,并在没有标签的情况下对可用的文档摘要对进行训练,我们接下来使用具有句子级别度量奖赏的策略梯度来连接这两个神经网络并学习句子重要性。我们还通过防止策略梯度影响生成器的词级训练来避免常见语言流利性问题,这得到了我们的人类评估研究的支持。我们的句子级强化学习考虑了单词句子层次结构,它可以更好地对语言结构进行建模,并使并行化成为可能。我们的提取器结合了强化学习和指针网络,这是受Bello et al. (2017) 尝试解决旅行商问题而启发的。我们的生成器是一个简单的编码器-对齐器-解码器模型(具有复制机制),并对通过自动匹配方法获得的伪文档-摘要句子对进行训练。
因此,我们的方法结合了生成方法的优势,即简洁地重写句子并从完整的词汇表中生成新的单词,但它采用了中间抽取行为来提高整体模型的质量,速度和稳定性。我们的模型不是采用顺序编码和关注长输入文档中的每个单词,而是采用人为启发的从粗到精的方法,该方法首先提取所有重要的句子,然后并行解码(重写)这些句子。 这也避免了冗余的问题,因为该模型已经选择了非冗余的句子来生成摘要(但是添加可选的reranker组件确实会通过删除较少的重复句子而获得更多收益)。
从经验上讲,我们的方法在CNN/Daily Mail数据集的ROUGE和METEOR上所有指标都到到了最新技术,与以前的使用长编码器,复制和覆盖机制的模型相比,在统计上有显着改进。仅测试DUC-2002的改进还表明,与强大的生成式系统相比,我们的模型具有更好的通用性。此外,我们使用生成模型在所有ROUGE得分上都超过了流行的Lead-3基准。而且,与See et al. (2017) 的强壮的扁平结构模型相比,我们的句子级生成重写模块还产生了新的N-gram,这些N-gram在输入文档中没有看到。从经验上证明,我们的由RL引导的抽取器已经学会了句子的显着性,而不是简单地复制较长的句子而受益。我们还表明,我们的模型保持了与基于RNN的常规模型相同的流利程度,因为奖赏不会影响我们生成器的词级训练。最后,我们模型的训练速度是以前的最新技术的4倍,推理速度提高了20倍以上。可选的reranker在保持7倍加速的同时提供了进一步的改进。
总的来说,我们的贡献有三个方面:首先,我们为文本摘要任务提出了一种新的句子级RL技术,可以有效地利用单词-句子-句子的层次结构,而无需要求在文档和真实摘要之间标注匹配的句子对。接下来,我们的模型可以通过抽取加生成的方式在常用的摘要数据集(以及仅用于测试的数据集)的多个版本上达到最新技术,且不会损失语言的流利性(这通过人类的评估和打分进行了证明)。最终,我们的并行解码比以前的最优神经摘要生成系统提高了10到20倍的速度,并且具有更高的准确性。
2.模型
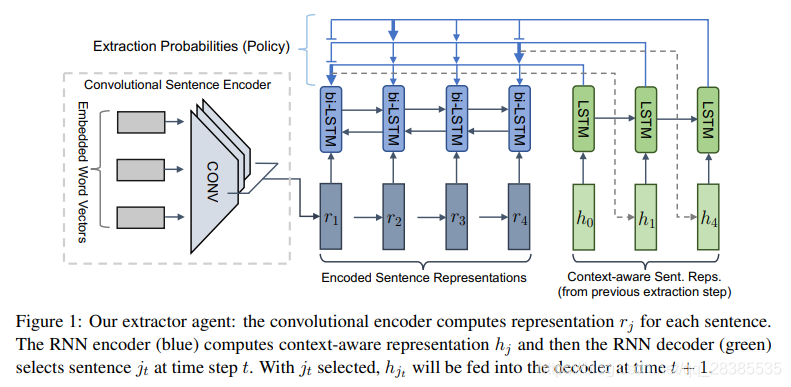
在这项工作中,我们考虑将给定的长文本文档汇总成若干重要句子,然后将其组合以形成多句子摘要。形式上,给定训练的【文档-摘要】对 { x i , y i } i = 1 N \{x_i,y_i\}^N_{i=1} {
xi,yi}i=1N,我们的目标是估计函数 h : X → Y , X = { x i } i = 1 N , Y = { y i } i = 1 N h:X→Y,X=\{x_i\}^N_{i=1},Y=\{y_i\}^N_{i=1} h:X→Y,X={
xi}i=1N,Y={
yi}i=1N使得 h ( x i ) = y i , 1 ≤ i ≤ N h(x_i)=y_i,1≤i≤N h(xi)=yi,1≤i≤N。此外,我们假设存在一个生成函数 g g g定义为: ∀ s ∈ S i , ∃ d ∈ D i ∀s∈S_i,∃d∈D_i ∀s∈Si,∃d∈Di使得 g ( d ) = s , 1 ≤ i ≤ N g(d)= s,1≤i≤ N g(d)=s,1≤i≤N,其中 S i S_i Si是 x i x_i xi中的摘要句集和, D i D_i Di是 y i y_i yi中的文档句集和。即,在任何给定的文档和摘要对中,每个摘要句子都可以从某个文档句子中产生。为简单起见,在本文的其余部分中省略了下标 i i i。在此假设下,我们可以进一步定义另一个潜在函数 f : X → D n f:X→D^n f:X→Dn,其满足 f ( x ) = { d j } j = 1 n f(x)=\{d_j\}^n_{j=1} f(x)={
dj}j=1n且 y = h ( x ) = [ g ( d 1 ) , g ( d 2 ) , . . . , g ( d n ) ] y=h(x)=[g(d_1),g(d_2),...,g(d_n)] y=h(x)=[g(d1),g(d2),...,g(dn)],其中 [ , ] [,] [,]表示句子串联。该潜在函数 f f f可以看作是抽取器,它在给定文档中选择重要的句子以供生成函数 g g g重写。我们的总体模型由这两个子模块组成,分别是 e x t r a c t o r a g e n t extractor~agent extractor agent和 a b s t r a c t o r n e t w o r k abstractor~network abstractor network,分别近似于上述 f f f和 g g g。
2.1 Extractor Agent
抽取器agent旨在对 f f f建模,可以将其视为从文档中抽取重要句子。我们利用分层神经模型来学习文档的句子表示,并利用“选择网络”根据其表示提取句子。
2.1.1 分层句子表示
我们使用时域卷积模型来计算 r j r_j rj,即文档中每个单独句子的表示形式(详细信息在附录中)。为了进一步结合文档的全局上下文并捕获句子之间的长期语义依赖关系,将双向LSTM-RNN应用于卷积的输出。这使得能够学习一个强大的表示形式,该表示形式考虑到文档中第 j j j个句子的 h j h_j hj,并考虑了同一文档中所有先前和将来的句子的上下文。
2.1.2 句子选择
接下来,要基于以上句子表示选择提取的句子,我们添加另一个LSTM-RNN来训练Pointer Network,以循环抽取句子。我们通过以下方式计算抽取概率:
u j t = { v p T t a n h ( W p 1 h j + W p 2 e t ) i f j t ≠ j k ∀ k < t − ∞ o t h e r w i s e (1) u^t_j=\begin{cases} v^T_ptanh(W_{p1}h_j+W_{p2}e_t)&& if~j_t\neq j_k \quad \forall k\lt t\\ -\infty && otherwise \end{cases}\tag{1} ujt={
vpTtanh(Wp1hj+Wp2et)−∞if jt=jk∀k<totherwise(1)
P ( j t ∣ j 1 , . . . , j t − 1 ) = s o f t m a x ( u t ) (2) P(j_t|j_1,...,j_{t-1})=softmax(u^t)\tag{2} P(jt∣j1,...,jt−1)=softmax(ut)(2)
其中 e t e_t et是glimpse操作的输出:
a j t = v g T t a n h ( W g 1 h j + W g 2 z t ) (3) a^t_j=v^T_gtanh(W_{g1}h_j+W_{g2}z_t)\tag{3} ajt=vgTtanh(Wg1hj+Wg2zt)(3)
α t = s o f t m a x ( a t ) (4) \alpha^t=softmax(a^t)\tag{4} αt=softmax(at)(4)
e t = ∑ j α j t W g 1 h j (5) e_t=\sum_j \alpha^t_jW_{g1}h_j\tag{5} et=j∑αjtWg1hj(5)
在等式3中, z t z_t zt是添加的LSTM-RNN(在图1中以绿色显示)的输出,该输出被称为解码器。所有 W W W和 v v v都是可训练的参数。在每个时刻 t t t,解码器执行2次注意力机制:首先使用 h j h_j hj以获得上下文向量 e t e_t et,然后再次使用 h j h_j hj以获得提取概率。该模型实质上是在每个提取步骤对文档的所有句子进行分类。整个提取器的示意图如图1所示。
2.2 Abstractor Network
生成器网络用于近似函数 g g g,它将提取的文档句子压缩和释义为简洁的摘要句子。我们使用标准的编码器-对齐器-解码器。 我们添加了复制机制以帮助直接复制一些词汇(OOV)单词。有关更多详细信息,请参阅补充资料。
3.学习
假设我们的抽取器执行不可微分的硬提取,我们将应用标准策略梯度方法来桥接反向传播并形成端到端的可训练(随机)计算图。但是,仅从随机初始化的网络开始以端到端的方式训练整个模型是不可行的。当随机初始化时,抽取器通常会选择不相关的句子,因此生成器将很难学习抽象地重写。另一方面,如果没有训练有素的生成器,抽取器将获得不准确的奖赏,这将导致对策略梯度和次优策略的错误估计。因此,我们建议使用最大似然(ML)目标分别优化每个子模块:训练抽取器选择重要句子(拟合 f f f),并训练生成器生成摘要(拟合 g g g)。最后,将RL应用于端到端训练整个模型(拟合 h h h)。
3.1 子模块的最大似然训练
(1)Extractor Training
在2.1.2节,我们将句子选择定义为分类任务。但是,大多数摘要数据集都是端到端的文档摘要对,而没有每个句子的提取标签。因此,我们提出了一种简单的相似性方法,为抽取器提供一个“代理”目标标签。与Nallapati et al. (2017) 的抽取模型相似,对于每个真实摘要句子,我们通过以下方式找到最相似的文档句子 d j t d_{j_t} djt:
j t = a r g m a x i ( R O U G E − L r e c a l l ( d i , s t ) ) (6) j_t=argmax_i(ROUGE-L_{recall}(d_i,s_t))\tag{6} jt=argmaxi(ROUGE−Lrecall(di,st))(6)
给定这些代理训练标签,然后训练抽取器以最小化交叉熵损失。
(2)Abstractor Training
对于生成器训练,我们通过获取每个真实摘要句子并将其与抽取的文档句子配对(基于等式6)来创建训练对。将网络训练为常规的序列到序列模型,以在每个生成步骤最小化解码器语言模型的交叉熵损失 L ( θ a b s ) = − 1 M ∑ m = 1 M l o g P θ a b s ( w m ∣ w 1 : m − 1 ) L(θ_{abs})=-\frac{1}{M}\sum^M_{m=1}logP_{θ_{abs}}(w_m|w_{1:m-1}) L(θabs)=−M1∑m=1MlogPθabs(wm∣w1:m−1),其中 θ a b s θ_{abs} θabs是一组可训练参数。
3.2 强化指导抽取
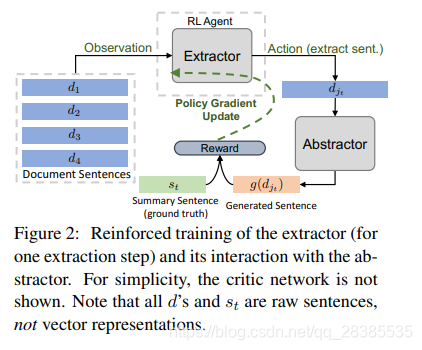
在这里,我们解释了如何应用策略梯度技术来优化整个模型。为了让抽取器作为RL agent,我们可以制定一个马尔可夫决策过程(MDP):在每个提取步骤 t t t,agent观察到当前的状态 c t = ( D , d j t − 1 ) ct=(D,d_{j_{t-1}}) ct=(D,djt−1),根据基于等式2计算动作策略 j t 〜 π θ a , ω ( c t , j ) = P ( j ) j_t〜π_{θ_a,ω}(c_t,j)=P(j) jt〜πθa,ω(ct,j)=P(j)抽取文档句子并获得奖赏:
r ( t + 1 ) = R O U G E − L F 1 ( g ( d j t ) , s t ) (7) r(t+1)=ROUGE-L_{F_1}(g(d_{j_t}),s_t)\tag{7} r(t+1)=ROUGE−LF1(g(djt),st)(7)
上述奖赏时在生成器生成抽取的句子 d j t d_{j_t} djt之后获得的。我们用 θ = { θ a , ω } θ=\{θ_a,ω\} θ={
θa,ω}分别表示抽取器解码器和分层编码器的可训练参数。然后,我们可以使用基于策略梯度的RL方法训练抽取器。我们在图2中说明了此过程。
vanilla策略梯度算法REINFORCE具有较高的方差。为了减轻这个问题,我们添加了一个带有可训练参数 θ c θ_c θc的critic网络,以预测状态价值函数 V π θ a , ω ( c ) V^{π_{θ_a,ω}}(c) Vπθa,ω(c)。critic的预测值 b θ c , ω ( c ) b_{θ_c,ω}(c) bθc,ω(c)称为“‘baseline”,然后用于估计优势函数: A π θ ( c , j ) = Q π θ a , ω ( c , j ) − V π θ a , ω ( c ) A^{π_θ}(c,j)=Q^{π{θ_a,ω}}(c,j)-V^{π_{θ_a,ω}}(c) Aπθ(c,j)=Qπθa,ω(c,j)−Vπθa,ω(c),因为总回报 R t R_t Rt是动作价值函数 Q ( c t , j t ) Q(c_t,j_t) Q(ct,jt)的估计。不是像REINFORCE中那样最大化 Q ( c t , j t ) Q(c_t,j_t) Q(ct,jt),我们通过以下策略梯度最大化 A π θ ( c , j ) A^{π_θ}(c,j) Aπθ(c,j):
∇ θ a , ω J ( θ a , ω ) = E [ ∇ θ a , ω l o g π θ ( c , j ) A π θ ( c , j ) ] (8) ∇_{θ_a,ω}J(θ_a,ω)=\mathbb E[∇_{θ_a,ω}log~π_θ(c,j)A^{π_θ}(c,j)]\tag{8} ∇θa,ωJ(θa,ω)=E[∇θa,ωlog πθ(c,j)Aπθ(c,j)](8)
并且critic通过最小化均方误差损失来训练: L c ( θ c , ω ) = ( b θ c , ω ( c t ) − R t ) 2 L_c(θ_c,ω)=(b_{θ_c,ω}(c_t)-R_t)^2 Lc(θc,ω)=(bθc,ω(ct)−Rt)2。这被称为Advantage Actor-Critic (A2C),是A3C的同步变体。有关A2C的更多详细信息,请参阅补充文件。
直观上,我们的RL训练工作如下:如果抽取器选择了一个好的句子,则在生成器重写它之后,ROUGE匹配会很高,因此鼓励采取这种动作。如果选择了错误的句子,尽管抽象器仍会生成它的压缩版本,则摘要将与基本事实不匹配,并且较低的ROUGE得分会阻止此操作。我们的带有句子级agent的RL是神经摘要中的一种新颖尝试。我们将RL用作重要性引导,而无需更改生成器的语言模型,而先前的工作将RL应用于单词级,这可能会导致牺牲语言流畅度来衡量指标。
学习要抽取的句子的数量:在典型的RL设置(例如游戏)中,episode通常会被环境终止。另一方面,在文本摘要中,agent预先不知道给定的文章需要生成多少个摘要句子(因为所需的长度随不同的下游应用程序而变化)。我们进行了重要而又简单,且直观的调整来解决此问题:在策略动作空间中添加一个“‘stop’”动作。在RL训练阶段,我们添加了另一组可训练参数 v E O E v_{EOE} vEOE(EOE代表“提取结束”),其维度与句子表示相同。指针网络解码器将 v E O E v_{EOE} vEOE视为候选抽取之一,因此自然导致随机策略中的停止操作。我们将agent执行EOE的奖赏设置为 R O U G E − 1 F 1 ( [ { g ( d j t ) } t ] , [ { s t } t ] ) ROUGE-1_{F_1}([\{g(d_{j_t})\}_t],[\{s_t\}_t]) ROUGE−1F1([{
g(djt)}t],[{
st}t])。而对于任何多余的,不需要的提取步骤,agent将获得零奖赏。因此,鼓励该模型在仍然存在真实摘要句子时进行抽取(以积累中间奖赏),并通过优化全局ROUGE并避免额外提取来学习停止。总体而言,此修改允许动态决策基于输入文档的句子,无需调整固定数量的步骤,并且可以对任何特定的数据集/应用程序进行数据驱动的调整。
3.3 Repetition-Avoiding Reranking
现有长文档生成式摘要系统存在生成重复和冗余单词和短语的问题。为了减轻这个问题,See et al. (2017) 提出了覆盖机制,Paulus et al. (2018) 在测试的波束搜索过程中引入了三元语法避免重复。没有上述机制的情况下,我们的模型已经表现良好,因为摘要语句是从互斥的文档语句生成的,这自然避免了冗余。但是,通过一种简单的重新排序策略,通过删除一些“跨句”重复,我们确实在一定程度上进一步提高了摘要质量:在句子级别,我们应用了相同的集束搜索三元语法规避策略。我们保留通过波束搜索生成的所有k个候选句子,其中k是集束的大小。接下来,我们重新排列n个生成的摘要语句波束的所有 k n k^n kn个组合。摘要按重复N-gram的数量排序,越小越好。我们还应用了Li et al. (2016) 中描述的多样化解码算法(几乎没有计算开销),以便根据上述方法来生成有用的多样化排名列表。我们将在6.2节展示冗余在多大程度上影响了摘要任务。
4.相关工作
早期的文本摘要工作主要集中在基于抽取和压缩的方法上。最近的大型语料库吸引了用于生成式摘要的神经方法。最近在神经生成模型上取得的一些成功包括分层注意力,覆盖率机制,基于RL的度量优化,基于图的注意力和复制机制。
我们的模型使用“提取-然后-压缩”方法共享一些高级特征。在此范式中,较早的尝试使用了隐马尔可夫模型和基于规则的系统,基于解析树的统计模型以及基于整数线性规划的方法。最近的方法研究了话语结构,图分割和解析树。对于神经模型,Cheng and Lapata (2016) 使用了第二个神经网络从第一个抽取器的输出中选择单词。我们的生成器不仅可以“压缩”句子,还可以产生新的单词。此外,我们的RL将抽取器和抽象器连接起来,以进行端到端的训练。
强化学习已被用来优化语言生成的不可微分指标并减轻曝光偏差。Henß et al. (2015) 使用基于Q-learning的RL进行抽取式摘要。Paulus et al. (2018) 使用RL策略梯度方法进行生成式摘要,并利用序列级度量奖赏与课程学习或加权ML + RL混合损失来获得稳定性和语言流利性。我们使用句子级奖赏来优化抽取器,同时保持经过ML训练的生成器固定。
在机器翻译中已经研究了使用一个固定的网络训练另一个神经网络以更好地解码和实时翻译。他们使用固定的预训练翻译器并应用策略梯度技术来训练另一个特定于任务的网络。在问答(QA)中,Choi et al. (2017) 提取一个句子,然后使用RL桥接从句子的向量表示中生成答案。另一项最近的工作尝试了一种新的从粗到精的摘要方法,并发现了所需的焦点属性,可以缩放到较大的输入(尽管未改进指标)。 最近(同时),Narayan et al. (2018) 使用RL对基于纯抽取的摘要中的句子进行排名,C¸ elikyilmaz et al. (2018) 研究了多个通信编码器agents以增强具有复制机制的生成式摘要器。
最后,最近有一些不太相关的工作:Zhou et al. (2017) 提出了选择性门来提高生成摘要中的注意力。Tan et al. (2018) 在QA上使用了提取-合成方法,其中提取模型预测了段落的重要跨度,然后另一个合成模型生成了最终答案。Swayamdipta et al. (2017) 尝试在提取QA上级联非循环的小型网络,从而产生了可扩展,可并行化的模型。Fan et al. (2017) 添加了控制参数,以生成适当长度,样式和实体首选项的摘要。但是,这些方法都没有使用RL来桥接神经模型的不可微分性。