模型介绍
Encoder-Decoder RNN with Attention and Large Vocabulary Trick
Encoder:双向GRU
Decoder: 单向GRU+attention+softmax层在目标词表中生成单词
Trick:每一个epoch 得到decoder的词汇表仅限于该批次的源文档中的单词,目标词典中最常用的单词也会被添加,直到词汇表达到一个固定的大小。这样做减小了softmax 层的大小,加快 了收敛速度。 这种方法很适合summary 中用,因为summary 大部分词来源于源文档。
Capturing Keywords using Feature-rich Encoder
文本摘要关键的挑战之一是确定文档中故事围绕的关键概念和关键实体,为每种标记类型的词汇表创建了基于查找的embeddiing,类似于word embedding 。对于源文档中的每个单词,我们只需从它的所有相关标记中查找它的嵌入,并将它们连接到一个长向量中,如图所示。在target side,我们继续只使用基于单词的嵌入作为表示。

我们分别对POS、nner标记和离散tf和idf值使用一个嵌入向量,它们与基于字的嵌入一起作为编码器的输入。
Modeling Rare/Unseen Words using Switching Generator-Pointer
- 处理这些oov(out of vocabulary )的直观方法就是简单地指向他们在源文档的位置— generator-pointer
- (https://img-blog.csdnimg.cn/20190311101645612.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwMjEwNDcy,size_16,color_FFFFFF,t_70)在decoder 端 设置了一个软开关,当开关显示‘G’时,使用由Softmax层组成的传统生成器生成一个单词,当它显示‘P’时,指针网络被激活以从其中一个字复制单词。
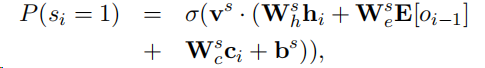 [
[
{kind=link}
这个生成概率的计算方法和之前 get-to-the-point 论文中的生成概率的计算方法是一样的。都使用了sigmoid函数作为软判断。
使用文档中单词位置的attention分布作为pointer 取样的分布。
目标函数为: 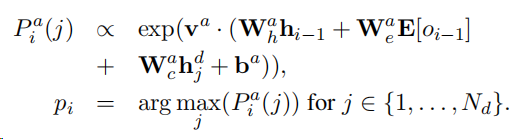
在训练时,无论何时在目标词汇中不存在摘要单词,我们都提供具有显式指针信息的模型。当总结中的OOV词出现在多个文档位置时,我们break the tie,以利于它的第一次出现。
损失函数 在训练时,我们优化了下面所示的对数条件似然函数,并增加了正则化惩罚项.
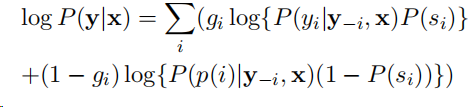
其中gi是指示函数:gi=0是指position i 的位置是ooV。
在测试时,该模型根据估计的开关概率P(Si),在每一时间步骤自动决定是生成还是点、指向源文档。我们只使用后验概率的argmax值。 在每一时间步骤中,生成或指向产生最佳输出的。
由于隐藏状态取决于单词的整个上下文,因此模型能够准确地指向未见的单词,尽管它们没有出现在目标词汇表中。
Capturing Hierarchical Document Structure with Hierarchical Attention
在源文档很长的数据集中,除了识别文档中的关键字外,还必须确定可从中提取摘要的关键句子。该论文中使用了两个双向的RNN在源文档处,一个是word 级别的,一个是sentence级别的。注意机制在两个层面同时运作。单词级attention被相应的句子级attention进一步重新加权,并被重新归一化。
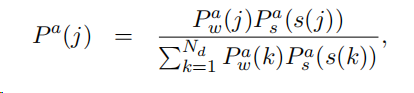
然后,使用re-scaled的注意来计算作为输入到解码器的隐藏状态的attention加权上下文向量。我们还将额外的positional embedding 连接到句子级RNN的隐藏状态,以模拟文档中句子的位置重要性。
因此,该体系结构对关键句子以及这些句子中的关键字进行了联合建模。图3显示了该模型的图形表示。
