就在这几天微软发布了一款参数量多达170亿的史上最大的自然语言生成模型 Turing-NLG,在多种语言模型基准上均实现了SOTA。

值得关注的是Turing-NLG在文本摘要上的表现,由于它已经非常善于理解文本了,因此不需要太多的配对数据就可以实现比已有模型更好的效果。

从Facebook的BART、Google的PEGASUS到今天Microsoft的Truing-NLG,越来越大的预训练数据集和越来越大的Transformer模型容量,以及新的预训练方法对于预训练模型在各项自然语言处理任务上效果的提升十分明显,同时也更加证明了有钱真好呀~
source: Turing-NLG: A 17-billion-parameter language model by Microsoft
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization

PEGASUS(Pre-training with Extracted Gap-sentences for
Abstractive Summarization)是Google Brain和帝国理工提出的一种新的自动文本摘要模型。PEGASUS同样基于Transformer进行模型构建,并针对于文本摘要任务本身的特定提出了新的自监督式的预训练目标GSG(Gap Sentences Generation),最后通过实验证明了在12个文本摘要数据集上均实现了当时的SOTA,而且作者指出在低资源的情形下同样可以取得不错的效果。
文本摘要作为NLP中一项很基础同时很重要的任务吸引了大量研究人员的目光,这几年借助深度神经网络的东风,不同的研究者和机构纷纷提出了不同的解决思路和建模技巧。尽管相关的文章有很多,但是真正的可以推进这项任务的并没有多少,更多的是相似任务模型的迁移使用或是一些小的建模技巧。
有关文本摘要的相关文章可浏览之前的诸多博文
不管是BERT、BART或是PEGASUS来解决文本摘要这项任务,模型最重要的就是对于文本的理解能力。因此,BERT使用了MLM(Masked Language Model)和PNS(Predict Next Sentence)的训练目标来进行预训练;BART采用类似于去噪自编码器的方式进行建模
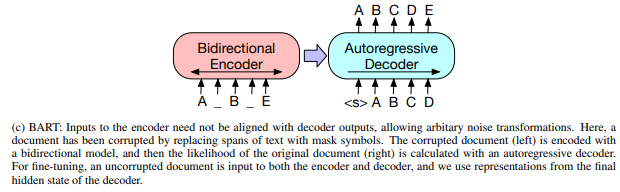
在文中所提及的CNN/DailyMail和XSum两个数据集上得到了比以往模型更好的效果。
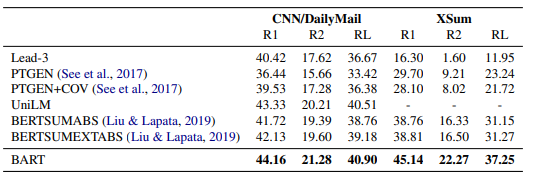
而本文提出了GSG这个新颖且更加针对于文本摘要的预训练目标进一步的提升了预训练模型在这项任务上的有效性和优异性。
本文的贡献主要为以下四个方面:
- 提出了一种新的针对于生成时文本摘要的自监督预训练目标
- 在12个文本摘要数据集上进行实验证明了预训练目标的有效性
- 通过实验证明了模型在低资源情形下同样可以有不错的效果
精读全文可以看出,本文最核心的内容便是预训练目标GSG,它通过一种新的学习方式可以更好的增强对于文本的学习能力。GSG是一种Sequence-to-Sequence的自监督目标,它的核心思想如下所示:

GSG将MASK信息的层级提高句子,为了更好的让模型理解文本,首先选择文档中重要的句子使用[MASK1]进行替换,然后在其余的句子中按照和BERT一样的MASK策略进行处理。80%的情况下使用[KASK2]进行替换,10%使用随机的token进行替换,10%的情况下不做改变。而重要性句子的选择作者试验了以下三种方式:
-
Random:均匀的随机选择m个句子
-
Lead:选择前m个句子
-
Principal:由于本身不存在针对于句子重要性的标签,因此这里使用ROUGE-F1分数做为代理表示,分数越高的句子表示重要性越高。
对应的算法伪代码表示:

文中作者也给出了一个示例来直观的理解三种选择方式的不同。

实验部分作者做了很多的工作,基本上所有可用的大型数据集都用到了,同时做为对比的基准模型也包含了最近发表的各种预训练模型。
- 两种PEGASUS模型对于之前的SOTA模型的结果:

- PEGASUSLARGE与XSum、CNN/DailyMail和Gigaword上其他预训练模型的比较
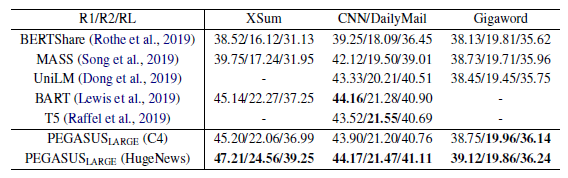
- 低资源情形下,,模型在有限的标注样本时fine-tune的结果

这篇文章进一步的证实了走堆数据量和模型容量对于提升模型的效果具有很大的作用,但是更适用于特定领域的预训练目标对于整体模型效果的提升同样重要。因此,当我们在设计不同的模型时,除了选择合适的模型架构之外,更为重要的是考虑如何使用不同的方式来提升模型的文本理解能力。
