分类问题
我们希望我们可以通过某一些的事物特征来判断这一类事物的类别,但这些类别往往不是"非黑即白",可能有多种类别,这些类别之间的关系是离散的,这时我们需要一种模型来区分这一类特征的类别。当然也存在多种相似的类别,它们对于相关属性的反映相似,但是终究是有差距的,所以最终我们往往取的是对其拟合程度最好的一种类别来对其特征进行标记。
预测模型
模型的输入是相关训练集的各个属性,在这里也是以一种线性叠加的方式来进行构建,即:
x1ω1+x2ω2+.......+xnωn+b=o
ω为相关的权重系数,x为具体的属性值,b为一个相应的偏移量,但是这里与线性回归的不同在于这个
o不在是一个简单的预测值,其实际的意义产生了变化,其名称代表了一个类别,其值的大小代表了这些属性对于这一类别的匹配程度,值越大,匹配程度越高(含负值,负值的绝对值越大匹配程度越低,这个在后面的评价函数中体现)。
因此对应的我们要实现知道这种分类模型有多少个类别,对每一个类别都建立一个这样的关系,于是有完整的预测模型:
x1ω11+x2ω12+.......+xnω1n+b1=o1
x1ω21+x2ω22+.......+xnω2n+b2=o2
x1ω31+x2ω32+.......+xnω3n+b3=o3
..........
x1ωd1+x2ωd2+.......+xnωdn+bd=od
将x进行扩展有
X=[x1,x2,...xn,1],同样的对于
ω有
wi=[wi1,wi2,wi3,...win,bi]
⎣⎢⎢⎡w11w21....wd1w12w22....wd2................w1dw2n....wdnb1b2....bd⎦⎥⎥⎤
⎣⎢⎢⎡x1x2....1⎦⎥⎥⎤=⎣⎢⎢⎡ o1o2....od⎦⎥⎥⎤
大致如下图,有一个输入层一个输出层,输出层也是一个全连接层,每个输出结果都依赖所有的输入数据。
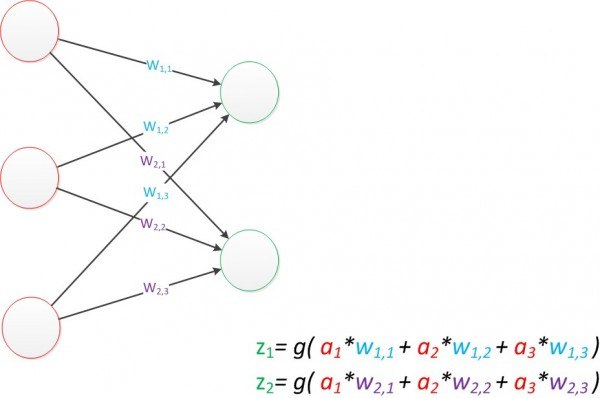
通过这个模型,我们通过输出层中数值大小来判断具体的类别归属。比如
o1,o2,o3为1,2,3最大的为
o3,所以最终的类别为
o3对应的类别。
softmax函数
显然在上面的输出中我们对于结果的表示体现不真切,很难具体的描述各个类别的匹配程度,并且
oi也可能取到负值,很难对其进行相关的意义描述,所以我们需要对其进行归一化,将其产生的结果映射到0~1之间,来更真切的表示其属性对某一类型匹配的置信度。相关函数如下:
将获得的
o1,o2,....od转变为指数形式为
eoi,这样不论
oi的取值如何都将对应到正值,之后再进行一个归一化,即
yi^=∑i=1deoieoi,表示关于某类别预测的置信度。显然对于
∑i=1dyi^=1,最终的标记类别为
max(yi^)。
因此softmax函数只是将对应的输出结果进行一个整合,将其输出数据的意义体现为一个概率分布,并不影响实际的输出类别。
评价模型
实际获得的输出为一个概率分布表示各个类别的置信度,而对于某个测试实例,实际的标签值中只有一个标签为1,其他的标签的值均为0。我们需要使我们的输出数据更加贴近与实际的标签值。
交叉熵损失函数
由于我们实际取的是最大置信度的那个标签,所以我们不需要预测的概率与实际完全相同,所以有交叉熵这样一个评估方法:
H(yi,yi^)=−∑i=1dyilogyi^
其中
yi为实际的标签值,非1即0,而
yi^为我们得到的输出参数,即各个标签的概率分布,显然对于
yi中为0的值来说
yilogyi^=0,所以在一个样本一个标签的情况下,我们仅仅考虑标签值
yi=1时对于的
yilogyi^即可,由于
logyi^中
yi^<0,所以前面有一个负号为
−logyi^。
对于m个样本训练集来说实际的损失函数为:
ℓ(θ)=n1∑i=1mH(yi,yi^)=−n1∑i=1mlogyi^
变换一下有:
e−nℓ(θ)=∏i=1myi^
要使
ℓ(θ)最小即相应的
∏i=1myi^取最大。
分类的准确率:实际运行时我们将模型得到的分类结果与实际进行比对,求出预测正确的数量占整个预测数据集的比值。
