Softmax回归
与线性回归的不同在于Softmax回归的输出单元从一个变成了多个,同时引入Softmax运算使得输出更加适合离散值的预测和训练;
Softmax回归模型
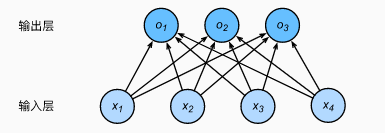
与线性回归相同,都是将输入特征与权重做线性叠加,,其输出层也是一个全连接层。与线性回归的最大不同在于:Softmax回归的输出值个数等于标签中的类别数;
Softmax运算
为得到离散的预测输出,将输出值oi当做预测类别i的置信度,并将值最大的输出所对应的类别作为预测输出,即argmaxioi;
但是,直接使用输出层的输出存在以下两个问题:
- 输出层的输出值范围不确定,难以直观上判断这些值的意义;
- 由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量;
解决办法:使用Softmax运算符,可以将输出值变换为值为正且和为1的概率分布,因此Softmax运算不会改变预测类别的输出;
模型预测及评价
使用准确率(accuracy)来评价模型表现,accuracy = 正确预测数量 / 总预测数量之比;
小结
- Softmax回归适用于分类问题,使用Softmax运算输出类别的概率分布;
- Softmax回归是一个单层神经网络,输出个数等于分类问题中的类别个数;
- 交叉熵用于衡量两个概率分布的差异;
图像分类数据集(Fashion-MNIST)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/10 15:11
# @Author : cunyu
# @Site : cunyu1943.github.io
# @File : fashionMinst.py
# @Software: PyCharm
import d2lzh as d2l
from mxnet.gluon import data as gdata
import sys
import time
"""
获取数据集
"""
mnist_train = gdata.vision.FashionMNIST(train=True) # 训练集
mnist_test = gdata.vision.FashionMNIST(train=False) # 测试集
print(len(mnist_train), len(mnist_test))
feature, label = mnist_train[0]
print(feature.shape, feature.dtype)
print(label, type(label), label.dtype)
# 将数值标签转成相应的文本标签的函数
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
# 从一行中画出多张图像和对应标签的函数
def show_fashion_mnist(images, labels):
d2l.use_svg_display()
# _表示忽略(不使用)的变量
_, figs = d2l.plt.subplots(1, len(images), figsize=(12,12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.reshape((28,28)).asnumpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
X, y = mnist_train[0:9]
show_fashion_mnist(X, get_fashion_mnist_labels(y))
"""
读取小批量
"""
batch_size = 256
transformer = gdata.vision.transforms.ToTensor()
if sys.platform.startswith('win'):
num_workers = 0 # 表示不用额外进程来加速读取数据
else:
num_workers = 4
train_iter = gdata.DataLoader(mnist_train.transform_first(transformer), batch_size, shuffle=True, num_workers=num_workers)
test_iter = gdata.DataLoader(mnist_test.transform_first(transformer), batch_size, shuffle=False, num_workers=num_workers)
# 读取训练数据所需时间
start = time.time()
for X, y in train_iter:
continue
print('%.2f sec' % (time.time() - start))
Softmax回归的实现
- 从零开始实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/10 16:12
# @Author : cunyu
# @Site : cunyu1943.github.io
# @File : softmax0.py
# @Software: PyCharm
import d2lzh as d2l
from mxnet import autograd, nd
# 获取与读取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
num_inputs = 784
num_outputs = 10
w = nd.random.normal(scale=0.01, shape=(num_inputs, num_outputs))
b = nd.zeros(num_outputs)
w.attach_grad()
b.attach_grad()
# 实现Softmax运算
X = nd.array([[1,2,3], [4,5,6]])
# axis = 0,代表同一列
# axis = 1,代表同一行
# keepdims,True则保留行、列两个维度,否则不保留
print(X.sum(axis=0, keepdims=True), X.sum(axis=1, keepdims=True))
def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(axis=1, keepdims=True)
return X_exp / partition # 应用广播机制
X = nd.random.normal(shape=(2,5))
X_prob = softmax(X)
print(X_prob, X_prob.sum(axis=1))
# 定义模型
def net(X):
return softmax(nd.dot(X.reshape((-1, num_inputs)), w) + b)
# 定义损失函数
y_hat = nd.array([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = nd.array([0, 2], dtype='int32')
print(nd.pick(y_hat, y))
# 交叉熵损失函数
def cross_entropy(y_hat, y):
return - nd.pick(y_hat, y).log()
# 计算分类准确率
def accuracy(y_hat, y):
return (y_hat.argmax(axis=1) == y.astype('float32')).mean().asscalar()
print(accuracy(y_hat, y))
# 评价模型net在数据集data_iter上的准确率
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
y = y.astype("float32")
acc_sum += (net(X).argmax(axis=1) == y).sum().asscalar()
n += y.size
return acc_sum / n
print(evaluate_accuracy(test_iter, net))
# 训练模型
num_epochs, lr = 5, 0.1
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, trainer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
with autograd.record():
y_hat = net(X)
l = loss(y_hat, y).sum()
l.backward()
if trainer is None:
d2l.sgd(params, lr, batch_size)
else:
trainer.step(batch_size)
y = y.astype('float32')
train_l_sum += l.asscalar()
train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar()
n += y.size
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size,
[w, b], lr)
# 预测
for X, y in test_iter:
break
true_labels = d2l.get_fashion_mnist_labels(y.asnumpy())
pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1).asnumpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
d2l.show_fashion_mnist(X[0:9], titles[0:9])
- 简洁实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/12 13:37
# @Author : cunyu
# @Site : cunyu1943.github.io
# @File : softmaxSimple.py
# @Software: PyCharm
import d2lzh as d2l
from mxnet import gluon, init
from mxnet.gluon import loss as gloss, nn
# 获取和读取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 定义和初始化模型
net = nn.Sequential()
net.add(nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
# softmax和交叉熵损失函数
loss = gloss.SoftmaxCrossEntropyLoss()
# 定义优化算法
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate' : 0.1})
# 训练模型
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, trainer)
