欢迎关注WX公众号:【程序员管小亮】
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
深度学习入门笔记(十四):Softmax
1、Softmax 回归
- 如果是二分分类的话,只有两种可能的标记——0或1,如果是猫咪识别例子,答案就是:这是一只猫或者不是一只猫;
- 如果有多种可能的类型的话呢?有一种 logistic 回归的一般形式,叫做 Softmax 回归,能在试图识别某一分类时做出预测,或者说是多种分类中的一个,不只是识别两个分类,一起看一下。
假设不单单需要识别猫,而是想识别猫,狗和小鸡,其中把猫称为类1,狗为类2,小鸡是类3,如果不属于以上任何一类,就分到“其它”或者说“以上均不符合”这一类,把它称为类0。

这里显示的图片及其对应的分类就是一个例子,这幅图片上是一只小鸡,所以是类3,猫是类1,狗是类2,如果猜测是一只考拉,那就是类0,下一个小鸡,类3,以此类推。假设用符号大写的
来表示输入会被分的类别总个数,那么在这个例子中,共有4种可能的类别,包括猫、狗、小鸡,还有“其它”或“以上均不符合”这一类。当有这4个分类时,指示类别的数字就是从0到
,换句话说就是0、1、2、3。
如果在这个例子中想要建立一个神经网络,那么其输出层需要有4个,或者说
个输出单元,如图:
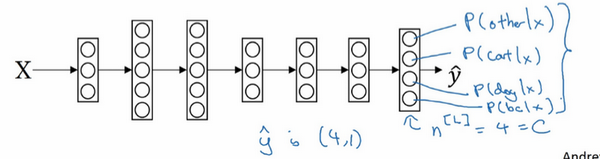
我们想要输出层单元通过数字的方式,告诉我们这4种类型中判别为每个类别的概率有多大,所以这里的:
- 第一个节点输出的应该是或者说希望它输出“其它”类的概率;
- 第二个节点输出的应该是或者说希望它输出猫的概率;
- 第三个节点输出的应该是或者说希望它输出狗的概率;
- 第四个节点输出的应该是或者说希望它输出小鸡的概率;
因此这里的输出 将是一个 维向量,它必须输出四个数字,代表四种概率,并且输出中的四个数字加起来应该等于1才对。如果想让网络做到这一点,那么需要用到的标准模型是 Softmax 层,以及输出层来生成输出。
在神经网络的最后一层, 是最后一层的 变量,计算方法是:
算出了 之后就需要应用 Softmax 激活函数了,这个激活函数对于 Softmax 层而言是有些不同,它的作用是这样的:
- 首先,计算一个临时变量 ,这适用于每个元素,而这里的 ,在我们的例子中, 是4×1的,四维向量 ,这是对所有元素求幂;
- 然后计算输出的 ,基本上就是向量 ,但是要做归一化,使和为1,计算公式 。
你可能不是很懂这个意思,别担心,来看一个例子,详细解释一下上面的公式。
假设算出了 , ,我们要做的就是用上面的方法来计算 ,所以 ,当然如果按一下计算器的话,就会得到以下值 。对向量 归一化就能得到向量 ,方法是把 的元素都加起来,得到176.3,计算公式是 ,即可得:
- 第一个节点,输出 ,这意味着,这张图片是类0的概率就是84.2%。
- 第二个节点,输出 ,这意味着,这张图片是类1的概率就是4.2%。
- 第三个节点,输出 ,这意味着,这张图片是类2的概率就是0.2%。
- 最后一个节点,输出 ,也就是这张图片是类3的概率就是11.4%,也就是小鸡组,对吧?
这就是它属于类0,类1,类2,类3的可能性。
神经网络的输出 ,也就是 ,是一个4×1维向量,就是算出来的这四个数字( ),所以这种算法通过向量 计算出总和为1的四个概率。
Softmax 分类器还可以代表其它的什么东西么?
举几个例子,假设有两个输入
,
,它们直接输入到 Softmax 层,有三四个或者更多的输出节点,输出
。如果是一个没有隐藏层的神经网络,就是计算
,而输出的
,或者说
,
,就是
的 Softmax 激活函数。
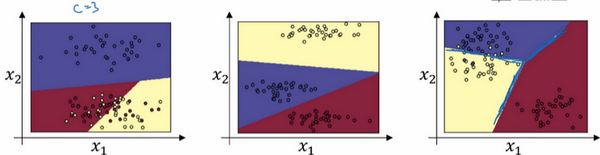
这个例子中(左边图),原始输入只有
和
,一个
个输出分类的 Softmax 层能够代表这种类型的决策边界,请注意这是几条线性决策边界,但这使得它能够将数据分到3个类别中。在这张图表中,我们所做的是选择这张图中显示的训练集,用数据的3种输出标签来训练 Softmax 分类器,图中的颜色显示了 Softmax 分类器的输出阈值,输入的着色是基于三种输出中概率最高的那种。因此可以看到这是 logistic 回归的一般形式,有类似线性的决策边界,但有超过两个分类,分类不只有0和1,而是可以是0,1或2。中间图是另一个 Softmax 分类器可以代表的决策边界的例子,用有三个分类的数据集来训练,还有右边图也是。
但是直觉告诉我们,任何两个分类之间的决策边界都是线性的,这就是为什么可以看到,比如黄色和红色分类之间的决策边界是线性边界,紫色和红色之间的也是线性边界,紫色和黄色之间的也是线性决策边界,但它能用这些不同的线性函数来把空间分成三类。
我们来看一下更多分类的例子:
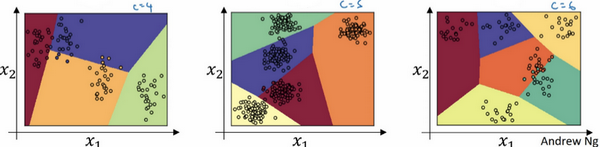
这个例子中(左边图)
,因此这个绿色分类和 Softmax 仍旧可以代表多种分类之间的这些类型的线性决策边界。另一个例子(中间图)是
类,最后一个例子(右边图)是
,这显示了 Softmax 分类器在没有隐藏层的情况下能够做到的事情,当然更深的神经网络会有
,然后是一些隐藏单元,以及更多隐藏单元等等,因此可以学习更复杂的非线性决策边界,来区分多种不同分类。
2、训练一个 Softmax 分类器
如何学习训练一个使用了 Softmax 层的模型?
回忆之前举的的例子,输出层计算出的
如下,
,输出层的激活函数
是 Softmax 激活函数,那么输出就会是这样的:
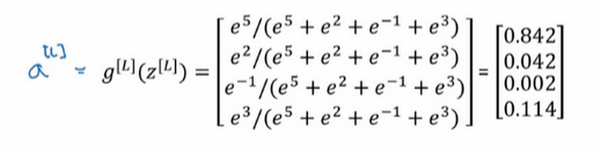
简单来说就是归一化,使总和为1,注意到向量
中,最大的元素是5,而最大的概率也就是第一种概率,为啥会这样?

这要从头讲起,Softmax 这个名称的来源是与所谓 hardmax 对比,hardmax 会把向量
变成这个向量
,hardmax 函数会观察
的元素,然后在
中最大元素的位置放上1,其它位置放上0。
与之相反,Softmax 所做的从 到这些概率的映射更为温和,不知道这是不是一个好名字,但至少这就是 softmax 这一名称背后所包含的想法,与 hardmax 正好相反。
有一点没有细讲,但之前已经提到过的,就是 Softmax 回归或 Softmax 激活函数将 logistic 激活函数推广到 类,而不仅仅是两类,如果 ,那么 Softmax 变回了 logistic 回归。
接下来看怎样训练带有 Softmax 输出层的神经网络,具体而言,先定义训练神经网络使会用到的损失函数。举个例子,看看训练集中某个样本的目标输出,真实标签是 ,这表示这是一张猫的图片,因为它属于类1,现在假设神经网络输出的是 , 是一个包括总和为1的概率的向量, ,总和为1,这就是 , 。所以你可以明显看到对这个样本来说神经网络的表现不佳,这实际上是一只猫,但是猫的概率却只有20%。
那么用什么损失函数来训练这个神经网络?
在 Softmax 分类中,一般用到的损失函数是 ,现在用上面的样本来验证一下,方便更好地理解整个过程。注意在这个样本中 ,因为这些都是0,只有 ,所以如果看这个求和,所有含有值为0的 的项都等于0,最后只剩下 ,因为当按照下标 全部加起来,所有的项都为0,除了 时,又因为 ,所以它就等于 。即:
这就意味着,如果学习算法试图将损失函数变小,就是使 变小,要想做到这一点,就需要使 尽可能大, 函数虽然是递增的,但是 函数是递减的,这就讲得通了。又因为在这个例子中 是猫的图片,就需要猫这项输出的概率尽可能地大( 中第二个元素)。
概括一下,损失函数所做的就是找到训练集中的真实类别,然后试图使该类别相应的概率尽可能地高,如果你熟悉统计学中最大似然估计,这其实就是最大似然估计的一种形式。但如果你不知道那是什么意思,也不用担心,用刚讲过的算法思维也足够理解了。
上面所讲的,是单个训练样本的损失,那么整个训练集的损失 又如何呢?也就是设定参数的代价之类的,还有各种形式偏差的代价,还是和之前讲过的一样,你大致也能猜到,就是整个训练集损失的总和,把训练算法对所有训练样本的预测都加起来:
因此用梯度下降法,使损失最小化。
最后还有一个实现细节,注意!因为 , 是一个4×1向量,如果向量化,矩阵大写 就是 ,举个例子,如果上面的样本是第一个训练样本,那么矩阵 ,那么这个矩阵 最终就是一个 维矩阵。
类似的, ,其实就是 ( ),那么 , 本身也是一个 维矩阵。
最后还是来看一下,在有 Softmax 输出层时,如何实现梯度下降法,这个输出层会计算
,它是
维的,在上面的例子中是4×1,然后用 Softmax 激活函数来得到
或者说
,然后又能由此计算出损失。具体操作还是和之前见过的反向传播一样,不懂或者忘记的同学可以去查阅一下前面的笔记。
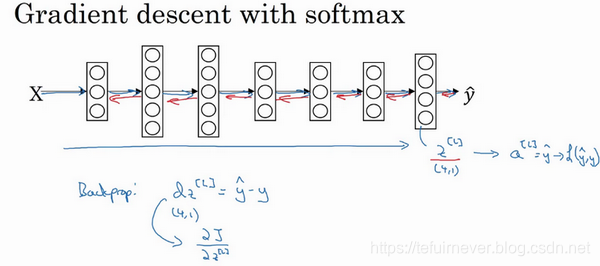
关于具体如何实现这个函数,下次课会开始使用一种深度学习编程框架,对于这些编程框架,通常只需要专注于把前向传播做对即可,编程框架它自己会弄明白怎样反向传播,这也是为什么很多人被称为调包侠的原因,因为编程框架会帮你搞定导数计算。
给一个 Python 实现 softmax 的小例子,理解理解公式:
# softmax函数,将线性回归值转化为概率的激活函数。
# 输入s要是行向量
def softmax(s):
return np.exp(s) / np.sum(np.exp(s), axis=1)
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程
