目录
回归可以用于预测多少的问题,比如预测房屋被售出价格,或者棒球队可能获得的胜场数,又或者患者住院的天数。事实上,我们也对分类问题感兴趣,不是问“多少”,而是问“哪一个”:
-
某个电子邮件是否属于垃圾邮件文件夹?
-
某个用户可能注册或不注册订阅服务?
-
某个图像描绘的是驴、狗、猫、还是鸡?
-
某人接下来最有可能看哪部电影?
通常,机器学习实践者用分类这个词来描述两个有微妙差别的问题:
- 我们只对样本的“硬性”类别感兴趣,即属于哪个类别;
- 我们希望得到“软性”类别,即得到属于每个类别的概率。
这两者的界限往往很模糊。其中的一个原因是:即使我们只关心硬类别,我们仍然需要使用软类别的模型。
一、从回归到多类分类
1. 回归估计一个连续值
线性回归用一套 处理一组连续的m个样本
(的n维特征),用于拟合曲线(面)函数,预估后续函数值;
- 自然区间
内的单连续数值输出:
![]()
- 通常使用均方损失函数训练,预测值与真实值的区别作为损失:
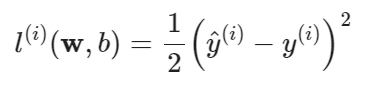
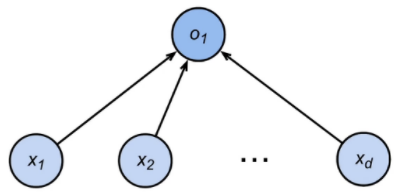
2. 分类预测一个离散类别
softmax回归用多套 处理每个离散样本
的n个特征,以此计算该样本属于每一类的概率,预测样本类别。

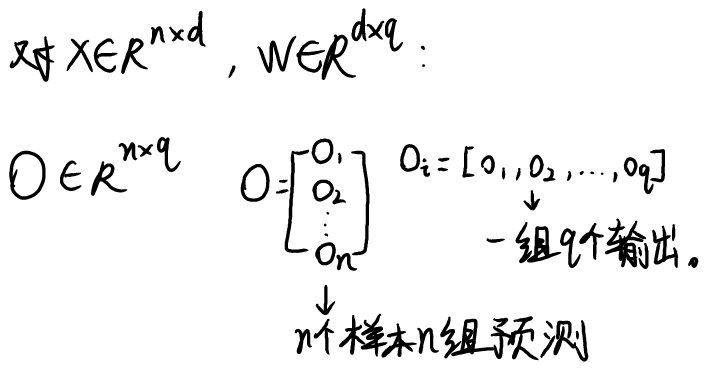
- 通常多个输出,每个类别对应一个输出:
我们需要和输出一样多的仿射函数(affine function), 每个输出对应于它自己的仿射函数。

- 输出
是预测为第
类的置信度(结果的可靠度,置信度越高,是该类的可能性越大):
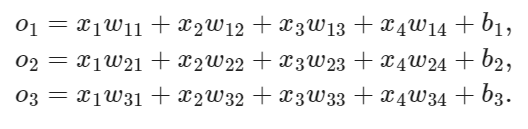
二、独热编码OneHot
对样本的类别进行一位有效编码,将标量 拉伸为向量
(n对应类别总数)——本意是用n个二分类来解决n分类问题。
- 样本属于第
位就为 1 ,其余 n-1 位全为 0 :

如一个有三种类别的样本:{狗,猫,鸡},标签y将是一个三维向量, 其中(1,0,0)对应于“猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗”。
三、校验比例——激活函数softmax

softmax函数(归一化函数)将未规范化的预测结果 变换为非负并且总和为1的概率值,同时要求模型保持可导:
- 首先对每个未规范化的预测求幂,这样可以确保输出非负;
- 再对每个求幂后的结果除以它们的总和,确保最终输出的总和为1。

- softmax函数并不会改变未规范化的预测
之间的顺序,所以可以用下式来选择最有可能的类别(argmax获取最大值下标
- 将
和
的区别作为损失,为了让损失最小,在训练时我们需要通过优化参数让
尽可能大,
为 1 ,
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型(linear model)。

补充:softmax函数求导![]() https://zhuanlan.zhihu.com/p/37740860其中 i 为softmax的第 i 个输出,j 为softmax的第 j 个输入;当 i = j 时表明输入和输出相匹配。
https://zhuanlan.zhihu.com/p/37740860其中 i 为softmax的第 i 个输出,j 为softmax的第 j 个输入;当 i = j 时表明输入和输出相匹配。
四、损失函数——交叉熵
- 交叉熵常用来衡量两个概率的区别:

- 将它作为损失函数:

- 其梯度是真实概率和预测概率的区别:
![]()
推导过程如下:
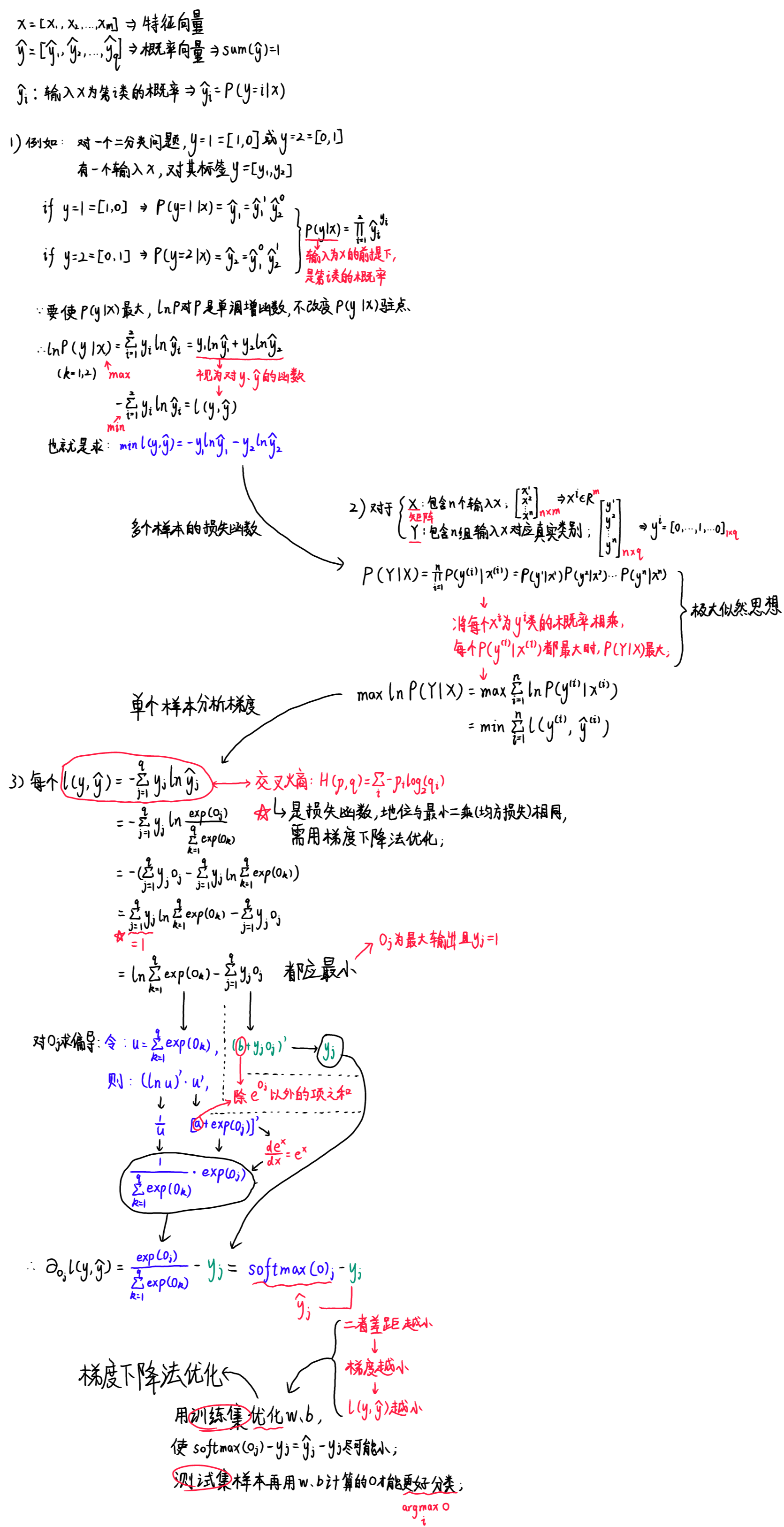
五、总结
Softmax回归是一个多分类的逻辑回归(解决二分类)模型:
- 使用Softmax作为激活函数得到每个类(归一化后)的预测置信度;
- 使用交叉熵作为损失函数来衡量预测和标号(每一位上)的区别。
使用交叉熵而非最小二乘法作为损失函数的优势:
