参照代码理解,比较直观:
# These are the weights between the input layer and the hidden layer.
self.weights_0_1 = np.zeros((self.input_nodes,self.hidden_nodes))
# These are the weights between the hidden layer and the output layer.
self.weights_1_2 = np.random.normal(0.0, self.output_nodes**-0.5,
(self.hidden_nodes, self.output_nodes))
# The input layer, a two-dimensional matrix with shape 1 x input_nodes
self.layer_0 = np.zeros((1,input_nodes))
一共三层:weights_0_1[input_nodes,hidden_nodes],weights_1_2[hidden_nodes,output_nodes]
#### Implement the forward pass here ####
### Forward pass ###
# Input Layer
self.update_input_layer(review)
# Hidden layer
layer_1 = self.layer_0.dot(self.weights_0_1)
# Output layer
layer_2 = self.sigmoid(layer_1.dot(self.weights_1_2))
输入和权重点乘:weights中每一列对应的是一个节点和前一层所有节点的权重
[1,input_nodes] · [input_nodes,hidden_nodes] = [1,hidden_nodes]
#### Implement the backward pass here ####
### Backward pass ###
# Output error
layer_2_error = layer_2 - self.get_target_for_label(label) # Output layer error is the difference between desired target and actual output.
layer_2_delta = layer_2_error * self.sigmoid_output_2_derivative(layer_2)
# Backpropagated error
layer_1_error = layer_2_delta.dot(self.weights_1_2.T) # errors propagated to the hidden layer
layer_1_delta = layer_1_error # hidden layer gradients - no nonlinearity so it's the same as the error
反向计算误差:
先有输出层误差,关注如何从i层误差到i-1层误差:
经过激活函数,无法相当于经过一个放大器:layer_2_error * self.sigmoid_output_2_derivative(layer_2)
i-1误差,考虑一个节点,误差来自于i层所有节点误差加权求和,
比如weights_1_2[hidden_nodes,output_nodes],求第1个节点误差,对应的权重weights_1_2[1,output_nodes],即第一行,所有计算方式为:layer_1_error = layer_2_delta.dot(self.weights_1_2.T)
# Update the weights
self.weights_1_2 -= layer_1.T.dot(layer_2_delta) * self.learning_rate # update hidden-to-output weights with gradient descent step
self.weights_0_1 -= self.layer_0.T.dot(layer_1_delta) * self.learning_rate # update input-to-hidden weights with gradient descent step
得到了每一层的误差delta之后,下面就考虑如何更新权重?
从现有数据怎么得到
/
?

为第k层的值,未添加激活函数的k层节点值
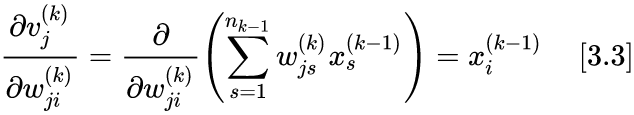
前半部分通过反向传播一个一个计算,已经计算出来了。
[hidden_nodes,1] · [1,output_nodes] = [hidden_nodes,output_nodes]
layer_2_delta = layer_2_error * self.sigmoid_output_2_derivative(layer_2)
self.weights_1_2 -= layer_1.T.dot(layer_2_delta) * self.learning_rate
采取向量的方式理解也比较直观

这个公式网上好多地方写错了.