前言
工作需要,对 scrapy 进行了解,并逐步开始使用。门槛不高,有些许 Python 编程经验就可。
1.入门第一步:
搭环境,先把 python 环境搞定,我用的是2.7(工作需要,但是建议用3.x 的,2020年以后 python 2.7 不再更新)。
我的电脑是 win10 ,只要是 windows 的电脑搭环境都费劲,linux 和 mac相对简单(江湖传言,真正的程序员都不用 windows ),花了不少时间,环境搭好了,不做详细描述,参见windows下安装scrapy。
2.开始项目:
开始项目前,建议先装一个集成开发环境 PyCharm 。
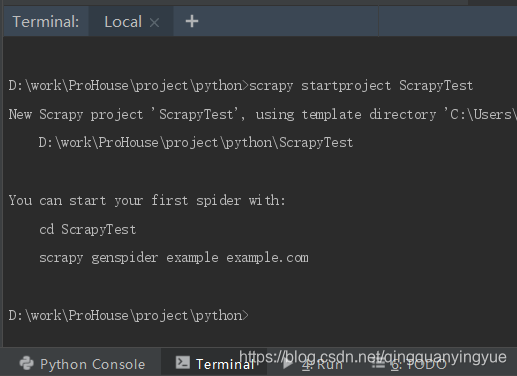
在 PyCharm 的命令行工具(Terminal)里面输入 scrapy startproject ScrapyTest 命令,如图,仔细阅读里面的文字说明(会少很多麻烦)
然后找到创建工程的目录,打开该工程,目录如下:
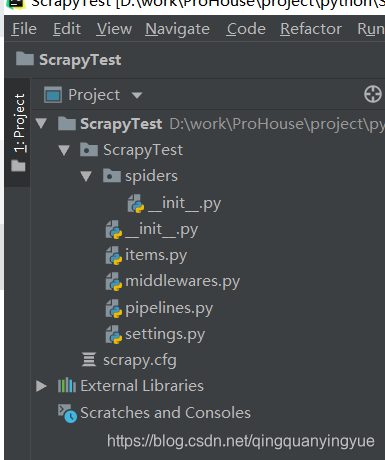
对于这个目录,只有 spiders 是存放爬虫文件的目录,其他文件或目录是协助存储,清洗等功能的,可以不用管,在这里不详细介绍。
3.新建爬虫
在 spiders 目录新建 python 文件,文件名可以随意,写入下面代码 ,代码关键点会有注释
#!/usr/bin/python
# -*- coding: utf-8 -*-
import scrapy
import urlparse #拼接 url 用的类函数
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8') #重新定义编码
class BaoJiWangSpider(scrapy.Spider):
name = 'bao_ji_wang' #爬虫名,是爬虫唯一入口
start_urls = []
def __init__(self, start_url=None): #初始化函数,用于传入启动参数,也可以把参数写死
super(BaoJiWangSpider, self).__init__()
self.start_urls = start_url.split('|')
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, method='get', callback=self.parse) # get方式请求url的信息,并调用parse函数处理
def parse(self, response):
selectors = response.xpath("//div[@class='xld nvbing5_nr']/dl[@class='cl nvbing5_lb_nrys']") #xpath语法解析信息
for selector in selectors:
href = selector.xpath("./dt//@href").get()
url = urlparse.urljoin(response.url, href) # 拼接超链接
pub_time = (selector.xpath("./dd/span/text()").get()).strip() # 获取发布时间
yield scrapy.Request(url=url, method='get',
meta={'pub_time': pub_time}, callback=self.parse_link) # 调用另一个函数处理详情页
@staticmethod
def parse_link(response):
url = response.url
title = response.xpath("//h1/text()").get() # 获取详情页标题
pub_time = response.meta['pub_time'] # 获取上一函数传来的发布时间值
media_name = (response.xpath("//p[@class='xg1']/text()[2]").get()).replace("\n", "").strip() #获取发布媒体
content = response.xpath("//td[@id='article_content']").get() # 获取详情页内容
collect_time = time.strftime('%Y-%m-%d %H:%M') # 格式化采集时间
print '*' * 80
print url
print pub_time
print title
print media_name
print collect_time
file_path = title[0:10] + ".html"
with open(file_path, 'w') as f: # windows 下编码可能问题,建议不要使用 print 打印内容,会报错,可以保存文件用浏览器打开查看内容
f.write(content)
4.运行爬虫
在 PyCharm 的命令行输入
scrapy crawl bao_ji_wang -a start_url=“http://www.cn0917.com/baojinews/”
( 用的是宝鸡网下面的一个新闻列表 ,不要纠结为啥用这个网站,http://www.cn0917.com/baojinews/)
可以得到保存的文件(里面有很多 h5 的标签,使用浏览器打开可以直接看到内容)
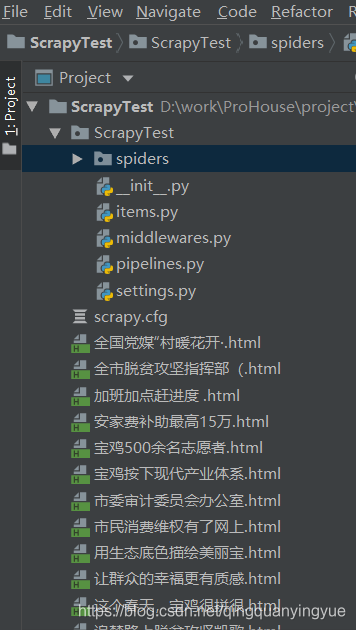
和打印的内容(部分)
********************************************************************************
http://www.cn0917.com/portal.php?mod=view&aid=21239
2019-3-15 14:00
市委审计委员会办公室挂牌成立
宝鸡日报·宝鸡网
2019-03-29 17:29
********************************************************************************
5.Tips
爬虫的文件里面有几个约定函数
start_requests: 初始化函数完成以后就开始执行此函数,名字一定不能有错误,可有可无。
parse: 在没有 start_requests 函数时会在初始化函数完成以后就执行,名字不能有错误,没有 start_requests 函数时一定不能缺少,有start_requests 函数时会变成一个普通函数。
