本文是论文 Deep Feature Interpolation for Image Content Changes (基于深度特征插值的图像内容更改) 的翻译,因为作者本人水平有限 ,部分翻译不准确的地方还请大家不吝赐教,我一定马上改正!
摘要
我们提出了深度特征插值( deep feature interpolation DFI),这是一种用于自动高分辨率图像转换的新的数据驱动基准。 顾名思义,DFI仅依赖于来自预训练卷积的深度卷积特征的简单线性插值。 我们证明,尽管DFI简单易行,但它仍然可以执行高级语义转换,例如“变老”,“戴眼镜”,“增加微笑”等等,令人惊讶的是,有时甚至可以匹配或超越当前最先进的水平。 这是特别出乎意料的,因为DFI不需要专门的网络体系结构甚至不需要任何深度网络就可以完成这些任务。 因此,DFI可以用作评估更复杂算法的新基准,并为深度学习问世后,哪些图像转换任务仍然具有挑战性?提供了实际的答案。
介绍
产生令人信服的图像变化是计算机视觉和图形学领域一个活跃而富挑战性的研究领域。 直到最近,算法通常都是为单个转换任务和特定于任务的专家知识手工设计的。 示例包括人脸[41、17],材料[2、1],颜色[50]或室外图像[23]中的季节的变换。 然而,深度卷积自动编码器的最新创新[33]产生了一系列更加通用的方法。 代替为特定任务设计每种算法,可以训练条件(或对抗)生成器[21、13],以通过监督学习[48、43、52]产生一组可能的图像变换。 尽管这些方法可以执行各种看似令人印象深刻的任务,但在本文中,我们证明了可以通过深度特征空间中的线性插值法解决其中的大量问题,并且可能不需要专门的深度体系结构。

图片一: 用DFI给图片添加年龄信息
线性插值如何有效? 在像素空间中,自然图像位于(近似)非线性流形[44]上。 非线性流形是局部欧几里得的,但整体上是弯曲的且是非欧几里得的。 众所周知,在像素空间中,图像之间的线性插值会引入重影伪影(一种背离基础流型的迹象)并且图像类别之间的线性分类器的效果很差。
另一方面,众所周知,深度卷积神经网络(convnet)在分类任务(例如视觉对象分类)[38,14,15]上表现出色,同时依赖于网络末端的简单线性层进行分类。 这些线性分类器的性能很好,因为网络将图像映射到新的表示形式,在这些表示形式中,图像类别可以线性分离。 实际上,先前的工作表明,在足够多样的对象识别类上进行训练的神经网络(例如在ImageNet [22]上进行训练的VGG [38])可以学习到令人惊讶的通用特征空间,并且可以用于为其他图像类训练线性分类器 。 Bengio等。 [3]假设卷积将自然图像的流形线性化为一个(全局)深度特征的欧几里得子空间。
受此假设启发,我们认为,在这样的深度特征空间中,某些图像编辑任务可能不再像以前认为的那样具有挑战性。我们提出了一个简单的框架,该框架支撑一个概念,即:在正确的特征空间中,可以通过在具有特定属性的图像和没有该属性的图像之间,使用线性插值的简单方式来进行图像编辑。例如,考虑给定两组图像,将面部毛发添加到男性面部图像中的任务:一组有面部毛发,一组没有面部毛发。如果可以训练卷积算法来区分有面部毛发和没有面部毛发的男性面孔,我们知道这些类别必须是线性可分离的。因此,沿着单个线性向量的运动应足以将图像从与“无面部毛发”相对应的深度特征,移动到与“面部毛发”相对应的深层特征。确实,我们将证明,即使这个向量的一个简单选择满足:我们对每组图像的卷积层特征求平均并求差。
我们将此方法称为深度特征插值(DFI)。 图1显示了在390×504图像上使用DFI进行面部变换的示例。
当然,DFI有局限性:我们的方法在所有图像对齐后效果最好,因此适合在有特征点要对齐的情况下(例如面部图像中的眼睛和嘴巴)。 还要求具有和不具有期望属性的样本图像与目标图像相似(例如,在图2的情况下,其他图像应包含白人男性)。
但是,这些关于数据的假设与那些通常用于训练生成模型的假设是可比的,并且当存在此类数据的情况时,DFI的效果令人惊讶。 我们证明了它在通常用于评估生成方法的几个转换任务上的功效。 与以前的工作相比,它更简单,并且通常更快,更通用:它不需要重新训练卷积网络,不专门从事任何特定任务,并且能够处理分辨率更高的图像。 尽管它很简单,但我们表明在许多图像编辑任务中,它的性能要优于那些涉及程度和专业性更高的最新方法。
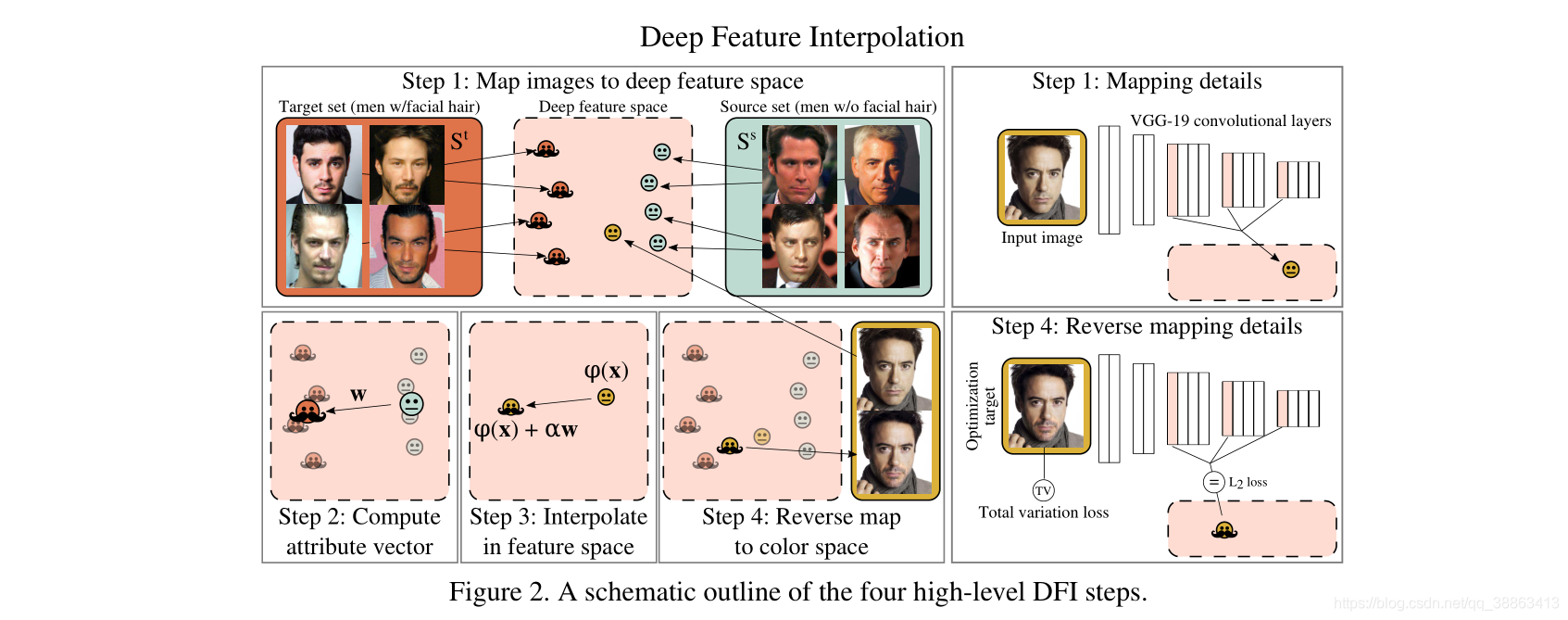
图片二: DFI 的四个高级步骤原理大纲图
相关工作
与我们最相似的生成方法可能是[24]和[32],它们类似地使用深度特征空间生成数据驱动的属性转换。我们将这些方法用作我们的主要比较点。但是,它们依赖经过专门训练的生成式自动编码器,与我们学习图像转换的方法从根本上不同。里德等人的著作。 [33,34]提出了挑战性任务(身份和观点改变)的内容改变模型,但没有证明真实的结果。同期工作[4]通过操纵潜在空间变量来编辑图像内容。但是,此方法受基础生成模型的输出分辨率限制。我们方法的优点是它可以与经过预训练的网络配合使用,并且能够在分辨率更高的图像上运行。通常,生成网络的许多其他用途与我们的问题设置[13,5,51,37,30,6,8]不同,因为它们主要处理生成新颖的图像而不是更改现有图像。
Gardner等。 [9]通过最小化最大平均差异统计数据的见证功能来编辑图像。 按其方法计算变换后的图像特征所需的内存呈线性增长,而DFI消除了此瓶颈。
Mahendran和Vedaldi [28]通过反转深度卷积特征表示来恢复视觉图像。 Gatys等。 文献[11]展示了如何通过优化重建过程中的特征目标将著名艺术家的艺术风格转换为自然图像。 与其重建图像或转移样式,我们不但要编辑现有图像的内容,同时还要保留照片的真实感以及与编辑操作无关的所有内容。
许多作品在学习的生成潜空间上使用矢量运算来证明变换效果[7,32,12,46]。 相反,我们建议在经过区别训练的特征空间上进行矢量运算可以达到类似的效果。
从概念上讲,我们的工作类似于[41、10、42、19、17],该工作使用视频或照片集将一个人的脸部个性和性格转移给另一个人(木偶的一种形式[39、45、20 ])。 这个困难的问题需要复杂的流水线才能获得高质量的结果。 例如,Suwajanakorn等。 [41]结合了几种视觉方法:基准点检测[47],3D人脸重建[40]和光流[18]。 我们的方法不太复杂,并且可以应用于其他领域(例如,鞋的产品图片)。
尽管我们并不声称涵盖了上述技术的所有情况,但我们的方法出奇地强大和有效。 我们认为,调查和进一步了解其有效性的原因将有助于通过深度学习更好地设计图像编辑。
深度特征插值
在我们的设置中,我们提供了一个测试图像x,我们希望该图像相对于给定的属性以可信的方式进行更改。 例如,图片可能是没有胡须的男人,我们想通过在保留男人身份的同时添加面部毛发来修改图片。
我们进一步假设访问具有期望属性的目标图像集合 (例如,有胡子的男人)和没有这个属性的源图像集合 (例如,没有胡子的男人)。 此外,我们还提供了在足够丰富的对象分类任务上进行过训练的预训练卷积网络,例如,在ImageNet [35]上进行了训练的开放式VGG网络[38]。 我们可以使用该卷积网络获得图像的新表示形式,将其表示为 。 向量 由应用于图像x时卷积网络的级联激活组成。 我们将其称为x的深层特征表示。
深度特征插值 可以概括为四个高级步骤(如图2所示):
-
我们通过预先训练的卷积 (例如,在ILSVRC2012上训练的VGG-19)将目标集 和源集 中的图像映射到深度特征表示中。
-
我们计算每组图像 和 的平均特征值,并将它们的差定义为属性向量
-
我们将测试图像x映射到深度特征空间中的一个点 上,然后沿着属性向量 进行移动,从而得到 。
-
我们可以通过求解像素空间w.r.t.z中的反向映射来重建变换后的输出图像z
尽管此过程看似简单,但我们在4.2节中表明它可能出奇地有效。 在下文中,我们将描述一些重要的细节,以使该程序在实践中可行。
选择
和
DFI假定属性向量w隔离了目标变换,即,它指向具有所需属性更改的图像x的深层特征表示。如果有这样的图像z(例如,与小罗伯特·唐尼先生相同的图像,留着胡须),我们可以计算
来精确隔离属性变化引起的差异。在没有确切的目标图像的情况下,我们通过目标和源集估计 w。因此,重要的是,这两个集合应尽可能与我们的测试图像x相似,并且在两个数据集之间没有系统的属性偏差。例如,如果
中的所有目标图像都是老年人的图像,而
中的源图像是年轻个体的图像,则矢量w会无意间捕获与衰老有关的变化。而且,如果两组与测试图像相差太大(例如,不同的种族),则转换看起来将难以置信。为了确保足够的相似性,我们将
和
限制为x的K个最近邻居。令
表示
与
的K个最近邻居;我们定义:
可以根据可用信息量以两种方式选择这些邻居。 当属性标签可用时,我们通过计算匹配属性的数量(例如,匹配性别,种族,年龄,头发颜色)来找到最接近的图像。 当属性标签不可用时,或作为第二选择标准,我们通过深度特征空间中的余弦距离获取最近的邻居。
深度特征映射 映射到深特征空间 有很多选择。我们使用在ILSVRC2012上预训练的归一化VGG-19网络的卷积层,已被证明对艺术风格的转换是有效的[11]。深度特征空间必须适合于两个非常不同的任务:(1)线性插值(2)反向映射回像素空间。对于插值,有利的是选择深层,这些深层沿着深卷积的线性化过程进一步发展[3]。相反,对于反向映射,较早的层捕获图像的更多细节[28]。 VGG网络分为五个合并区域(深度不断增加)。作为有效的折衷方案,我们从最后三个区域中选取了第一层,即conv3_1,conv4_1和conv5_1层(在ReLU激活之后),进行了展平和连接。由于VGG的池化层减小了输入图像的尺寸,因此在应用φ之前,我们将小图像的图像分辨率提高到至少200×200。
图像转换 由于大多数卷积网络(包括VGG)中都使用了ReLU激活,因此 中的所有维都是非负的,向量是稀疏的。 当我们对K个图像进行平均(而不是[3]中的单个图像)时,我们期望 , 在大多数特征中具有非常小的分量。 由于两个数据集 和 在目标属性上仅不同,因此与与该属性无关的视觉方面相对应的特征将被平均为非常小的值,并在向量w中被近似减去。
反向映射 DFI的最后一步是将向量
反向映射回像素空间,以获得输出图像 z。 直观地,z是映射到深特征空间时对应于
的图像。 尽管不存在用于VGG映射的闭式逆函数,但我们可以通过采用[28]的方法获得彩色图像,并找到具有梯度下降的z:
其中
是Total Variation正则化器[28],它鼓励相邻像素之间的平滑过渡,
在这里, 表示图像z中位置(i,j)的像素。 在整个实验中,我们将 , 。 我们用标准的爬山算法L-BFGS [26]求解(4)。
4.实验结果
我们根据各种任务和数据集评估DFI。 为了获得完美的可重复性,我们的代码可从https://github.com/paulu/deepfeatinterp获得。
4.1更改面部属性
在几个面部属性修改任务上,我们将DFI与AEGAN [24](一种生成式对抗自动编码器)进行了比较。 类似于DFI,AEGAN还通过在特征空间中进行矢量运算来对面部进行更改。 我们使用``野外标签化’’( Labeled Faces in the Wild (LFW))数据集,其中包含13,143张具有73种不同属性的预测注释的面部图像(例如,太阳镜,性别,圆形面部,卷曲的头发,MUSTACHE等)。 我们将这些属性用作实验的属性。 我们选择了六个属性进行测试:老人,嘴巴微开,眼睛睁开,笑容,胡须和眼镜。(对立属性是年轻,闭嘴,缩眼,皱眉,没有胡须,没有眼镜。)之所以选择这些属性,是因为将一个人改变为具有上述每个属性都是合理的。 我们的测试集由38张图像组成,这些图像没有六个目标属性中的任何一个,没有戴上帽子,闭嘴的,没有胡须,也没有戴眼镜。 由于LFW的性别高度不平衡,因此我们仅使用性别较为普遍的男性图像作为目标图像,源图像和测试图像。
匹配[24]的方法,我们将面部图像对齐并裁剪外部像素,剩下100×100的面部图像,我们将其调整为200×200。 目标(源)集合是具有正(负)属性的LFW图像。 从每个集合中取K = 100个最近邻居(按匹配属性的数量)以形成 和 。
我们凭经验发现,通过均方特征激活来缩放w使自由参数在多个属性转换之间更加一致。 如果d是
的维数,并且
是逐元素应用的,则我们定义:
其中设置
。
比较结果如图3所示。向下看每一列,我们希望每幅图像都能表达目标属性。 纵观每一行,我们希望看到该人的身份得以保留。 尽管AEGAN通常会产生正确的属性,但它并不能像简单得多的DFI一样保留身份。

知觉研究。 视觉图像变化的判断本质上是主观的。 为了获得DFI和AEGAN之间的客观比较,我们与Amazon Mechanical Turk工人进行了盲目的知觉研究。 我们要求工作人员选择最能表达目标属性的图像,同时保留原始面孔的身份。 这是一项细微的任务,因此我们要求工作人员在参加研究之前完成了一个教程。 该任务是在AEGAN和DFI(以随机顺序显示)之间进行强制选择,以在38张测试图像上进行六个属性更改。 我们从136位独特的工人那里平均每张图像收集了29.6条判断,发现DFI 优于 AEGAN的比例为12:1。 最差的属性,DFI优于AEGAN的比例依旧高达 4.6:1,最优的属性是眼镜,比例是38:1(请参见表1)。

4.2高分辨率衰老和面孔毛发
与许多生成模型相比,DFI的主要优点之一是能够在高分辨率图像上运行。 然而,在高分辨率的面部上呈现结果存在若干挑战。
首先,我们需要一个高分辨率数据集,从中可以选择 和 。 我们从现有的计算机视觉数据集(CelebA,MegaFace和Helen)和Google图像搜索中收集了100,000张高分辨率面部图像的数据库[27,29,25]。 我们扩充现有数据集,仅选择清晰,无障碍的正面高分辨率人脸。 这不同于许多现有的数据集,这些数据集可能包含嘈杂的低分辨率图像。
接下来,我们需要学习面部数据集中存在的图像的属性,以正确选择源图像和目标图像。 因为我们收集的大多数图像都没有标签,所以我们使用使用来自LFW和CelebA的标签数据开发的人脸属性分类器。
最后,数据集图像与输入图像的对齐需要尽可能接近,因为在较高的分辨率下,对齐不佳所导致的伪影会更加明显。 代替将数据集对齐作为预处理步骤,我们使用DLIB [16]中的现成的人脸对齐工具在测试时将 和 中的图像与输入图像对齐。
我们演示了编辑百万像素面孔以完成衰老并在三个不同面孔上添加面部毛发的结果。 由于这些图像的大小,选择的结果如图5所示。有关这些任务的完整结果表,请参阅补充材料。
4.3无属性修补
修复是用合理的像素值填充图像的缺失区域。 可能有多个正确答案。 当缺少的区域很大时,很难修补(请参见图4的测试蒙版)。 由于无法预测属性(例如,两只眼睛都不见时的眼睛颜色),我们使用特征空间中的距离来选择最近的邻居。

修复看上去与更改面部属性是差别很大的任务,但实际上它是DFI的直接应用。 我们需要的只是源和目标对,它们仅在缺少的区域不同。 通过拍摄图像并掩盖测试图像中缺失的相同区域,可以为任何数据集生成此类对。 带遮罩的图像成为源集,而没有目标的图像成为源集。 然后,我们根据VGG-19 pool5特征空间中的余弦距离在蒙版数据集(不包括测试图像)中找到K = 100最近的邻居。 我们在两个数据集上进行了实验:所有LFW(13,143张图像,包括男性和女性图像)和UT Zappos50k的Shoes子集(29,771张图像)[49,31]。 对于每个数据集,我们找到一个效果很好的
(LFW为1.6,UT Zappos50k为2.8)。
我们在图4上的12个测试图像(更多补充图片)上显示了我们的结果,这些图像与disCVAE [48]所使用的图像相匹配(请参见其论文的图6)。 定性地,我们观察到DFI结果是合理的。 填充的面部区域与肤色,皱纹,性别和姿势相匹配。 填充的鞋区域匹配颜色和鞋样式。 但是,当输入中可见茎时,DFI无法生产眼镜,并且由于数据集未完全对齐,因此某些鞋子出现了重影。 当人脸丢失时(即每个图像的中央部分),DFI的效果很好,但我们发现,当缺少一半的图像时,DFI的效果比disCVAE差(图8)。 总体而言,DFI在这些修复任务上表现出令人惊讶的出色表现。 考虑到与disCVAE相比,其不需要属性来描述缺失区域,因此结果特别令人印象深刻。

4.4改变自由参数
图6说明了更改β(转换强度)和K(源/目标集的大小)的效果。 随着β的增加,与任务相关的视觉元素发生更明显的变化(图7)。 如果β低,则可能出现重影。 如果β太大,则变换后的图像可能会跳到特征空间中的某个点,从而导致重建不自然。 K控制源和目标集中的图像种类。 缺乏多样性会造成伪影,其中更改后的像素与附近未更改的像素不匹配(例如,参见下唇,图6的最后一行)。 但是,太多的变化会导致 和 包含不同的子类,并且集合均值可能描述不自然的内容(例如,在图6的第一行中,鼻子有两个提示,反映出存在左向和右向子类) 。 实际上,我们选择一个适合各种图像和任务的β和K,而不是根据具体情况选择。

5. 讨论
在上一节中,我们显示了深度特征插值在某些图像变换任务上的效果出奇。 这是非常有希望的,并且可能对自动图像转换领域的未来工作产生影响。 但是,DFI对数据也有明确的限制和要求。 我们首先阐明DFI的某些方面,然后重点关注一些一般性观察。
图像对齐 是DFI工作的必要条件。 我们使用手段上的差异来抵消与我们要更改的属性无关的卷积特征的贡献,尤其是当此属性位于特定位置(添加胡须,睁开眼睛,添加微笑等)时。 例如,添加胡须时,所有目标图像都包含胡须,因此在其接受域中具有胡须的卷积特征将不会平均为零。 虽然最大池化为我们提供了一定程度的平移不变性,但是如果在图像周围高度变化的位置出现胡须,这种推理就会失败,因为然后没有卷积特征的特定子集会对应于“胡须特征”。 图像对齐是一种限制,但不是脸部(一种重要的图像类别)的限制。 如第4.2节所示,现有的面部对齐工具足以用于DFI。
时间和空间的复杂性 DFI的显着优势是它非常轻量(lean,不知到该怎么翻译……我觉得是轻量的意思)。 最大的资源占用是用于VGG-19卷积层的GPU内存(不需要大型的全连接层)。 1280×960的图像需要4 GB的空间,需要5分钟才能重建。 200×200的图像需要20秒钟来处理。 时间和空间复杂度是线性的。 相比之下,许多生成模型仅显示64×64图像。 尽管DFI不需要训练专门的体系结构,但是可以公平地说,在测试期间,它比经过训练的模型要慢得多(通常需要几秒钟的时间)。随着将来的工作,可能有可能将实时样式转移[36]在实践中加快DFI的速度。
DFI的简便性 尽管有关于高分辨率样式转换的工作[11,28,36],据我们所知,DFI是第一个实现自动高分辨率内容转换的算法。 DFI的简单机制可能会激发更复杂的后续工作,以将当前的生成体系结构扩展到更高的分辨率,这可能会解锁许多新的应用程序和用例。
生成性网络与区分性网络 据我们所知,这项工作是AE与使用经过判别训练的网络中的特征的方法的首次跨体系结构比较。 令我们大吃一惊的是,判别模型在内容分配方面的潜力与AE模型一样好。 一个可能的解释是,如果在更复杂的数据集上进行训练,则AE体系结构可以组织更好的潜在空间。 与识别数据集的大小和丰富度相比,AE通常在变化不大的小型数据集上进行训练。 ImageNet的丰富程度似乎是一个重要因素:在早期实验中,我们发现VGG-19的卷积特征空间在面部属性更改任务上优于VGG-Face的卷积特征空间。
线性插值作为基线 预训练特征空间中的线性插值可以用作确定某项任务是否有趣的第一项检验:DFI可以轻松解决的问题不太可能需要复杂的生成网络机制。生成模型比线性插值功能要强大得多,但是用于展示生成方法的当前问题(尤其是面部属性编辑)太简单了。确实,我们确实发现了生成模型优于DFI的许多问题。在修复的情况下,我们发现当蒙版区域为图像的一半时,缺少DFI(图8)。 DFI也无法进行形状[53]或旋转[34]转换,因为这些任务需要对齐的数据。在生成模型胜过DFI的情况下找到更多这些困难的任务将有助于我们更好地评估生成模型。我们建议DFI作为线性插值基线,因为它非常容易计算,可以扩展到将来的高分辨率模型,不需要监督属性,并且可以应用于几乎所有对齐的类别更改问题。


结论
我们引入了DFI,它可以在预训练的特征空间内进行插值,以实现各种图像转换,例如老化,添加面部毛发和修复。 总体而言,鉴于该方法的简单性,DFI的效果令人惊讶。 它能够在各种任务上产生高质量的图像,在许多情况下,其质量比现有的最新方法更好。 这表明,鉴于可以轻松实施DFI,DFI应该作为对齐数据上某些类型的图像转换的极具竞争力的基准。 考虑到DFI的性能,我们希望这会刺激对性能优于此方法的图像变换方法的进一步研究。
参考文献


