摘要
主要是对深度学习算法的综述。
-
首先讨论图像模糊的常见原因
-
介绍基准数据库与评价指标
-
summarize different problem formulations.
-
详细比较卷积神经网络分类方法
-
介绍了不同场景下的deblurring应用
-
讨论未来研究的主要困难
introduction
非深度学习方法总是把它当做逆滤波问题,空间变或不变。早期算法总假设blur kernel已知,运用图像逆卷积算法,有无正则化;或者假定未知,同时修复二者。非深度学习算法不太行。
我们主要介绍深度学习方法
-
回顾图像去模糊的预备工作,包括问题定义,模糊原因,去模糊方法,质量评估指标,以及基准数据集
-
介绍去模糊的深度学习算法,提供对现有方法进行分类的分类标准
扫描二维码关注公众号,回复: 14326948 查看本文章
-
分析图像去模糊的挑战并研讨研究的opportunities
各章节具体内容如下:
-
section2 模糊原因,去模糊法类型,图像质量度量
-
section3,4 CNN为基础非盲和盲图片各自的去模糊方法
-
section5 应用于深度去模糊方法的损失函数
-
section6,7 公共数据集与评价指标
-
section8 三个去模糊方法涉及领域有面部,文本,立体图像 讨论未来
2 Preliminaries
2.1 问题提出
图像模糊由多种方式引起,例如相机抖动,场景中的运动或失焦造成的模糊
假定一个模糊图像是由潜在的未模糊图像模糊化形成的
去模糊方法依赖于模糊化函数是否已知分为非盲和盲方法
Motion Blur 运动模糊 通过测量相机曝光时间段内的光子来捕获图像。在bright illumination下,曝光时间足够短,图像可以被很好的捕捉。然而较长的曝光时间可能会导致运动模糊。众多的方法通过假设模糊在整个图像上是均匀的,直接将退化过程建模为卷积过程。
I b = K ∗ I s + θ μ I_b = K * I_s + \theta_\mu Ib=K∗Is+θμ
任何相对于相机运动的物体都会沿着相对运动的方向看起来模糊不清
最早的方法使用移位变量核对模糊进行建模,而最近的研究涉及非均匀性模糊的情况
Out-of-focus Blur 图像清晰度也受到运动场景和相机焦平面之间距离的影响
物体离相机或远或近,造成或清晰或不清晰。Point Spread Function(PSF)总是如下定义:
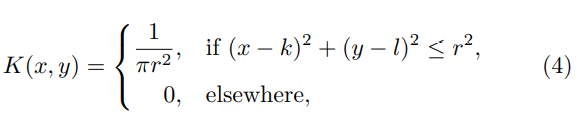
(k,l)是PSF的中心,r是blur的半径。Out-of-focus去模糊应用于saliency detection(显著性检测),defocus magnification(失焦放大)和image refocusing(图像重新聚焦)
主要方法有通过模糊检测或编码光影消除模糊的伪影
深度学习方法检测模糊区域和预测深度以指导去模糊过程。
Gaussian Blur 高斯卷积是图像处理中常用的一种简单模糊模型
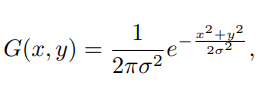
x,y分别是横轴和纵轴上离原点的距离,已经开发了几种经典方法来消除高斯模糊
Mixed Blur 就是多种主要模糊混合,或者其他原因,如由色差引起的通道依赖性模糊
2.2 Image Quality Assessment
图像质量评估可分为主观指标和客观指标。主观指标中的代表是平均指标,客观指标评估可分为全参考和无参考两类
Full-Reference Metrics完全参考指标通过比较修复后的图像和地面实况(GT)来评估图像质量,例如RSNR,SSIM,WSNR,MS-SSIM,IFC,NQM,UIQI,VIF和LPIPS。
其中RSNR和SSIM是图像修复任务中最常使用的指标
此外,LPIPS和E-LPIPS能准确预测人类对图像质量的判断
No-Reference Metrics非参考指标只使用去模糊的图像来衡量质量,例如BIQI,BLINDS2,BRISQUE,CORNIA,DIIVINE,NIQE和SSEQ。此外,通过比较对不同视觉任务(如物体检测和识别)准确性的影响,已经开发了一些指标来评估图像去模糊算法的性能
3 Non-Blind Deblurring
如果有了模糊核,被称为非盲目去模糊,即使有了模糊核,由于传感器的噪声和高频信息的损失,这个任务也具有挑战性
一些非深度方法采用自然图像先验,例如全局或局部先验,或在空间域或在频率域。为了克服不希望出现的环形伪影,空间去卷积和深度神经网络被结合起来。有方法处理饱和区域,去除由图像噪声引起的不需要的伪影。
深度学习方法有很多种,第一组使用去卷积然后再去噪,而第二组则直接使用深度网络:
Convolution表示用模糊核对清晰图像进行卷积合成训练数据
DCNN;高斯,磁盘;第一个将传统的基于优化的方案和神经网络结合起来的工作
IRCNN;高斯,移动;学习一套CNN去噪器,作为基于模型的优化方法的模块部分来处理逆向问题
FCNN;移动;适应性地学习图像先验,以保持图像细节和结构的稳健L1损失
FDN;移动;用基于FFT的去卷积方案学习基于CNN的先验
GLRA;高斯,磁盘,移动;使用模糊核的广义低等级近似值来初始化CNN参数
DUBLID;移动;将广义的TV规则化算法重塑为一个深度学习网络,用于盲图片去模糊
RGDN;移动;将深度神经网络纳入全参数化梯度下降方案中
DWDN;移动,高斯;通过整合经典的Wiener 去卷积框架,在特征空间中应用明确的去卷积公式
Deconvolution with Denoising
这些方法倾向于学习去噪模块,用于非盲目的图像去噪。学习去噪模块是学习先验的一种方法
[106]开发一个多层感知器MLP来解构图像:这种办法首先通过在傅里叶域的正则化反演来恢复清晰的图像,然后使用神经网络来去除去卷积过程中产生的伪影。
[141]使用深度CNN对含异常值的图像进行去模糊,该方法将奇异值分解应用于模糊内核,并在传统的基于优化的方案和CNN之间建立联系,但是对于不同的模糊核对模型进行重新训练。
由[141]中伪逆核的低秩特性,[102]提出一个通用的深度CNN,在一个统一的框架内处理任意模糊核,而不需要对每一个核进行重新训练。然而模糊核的低秩分解会导致性能下降。
[102,141]都是将一个去卷积CNN和一个去噪CNN连接起来,分别去除模糊和噪声。这样的去噪网络被设计用来去除额外的白噪声,而对模糊图像中的异常值或饱和图像像素处理得很差。
这些非盲去模糊网络需要针对固定的噪声水平进行训练,以达到良好的性能,这限制了它们在一般情况下的使用
[56]通过展开一个迭代方案,提出了一个傅里叶反卷积网络。其中每一个阶段包含一个基于FFT的逆卷积模块和一个基于CNN的去噪器,具有多种噪声水平的数据被综合起来进行训练,以达到更好的去模糊和去噪性能。
Learning priors for deconvolution
[7]学习了一个代表自然图像分布的平滑版本的均值偏移矢量场,使用梯度下降法来最小化非盲目去模糊的贝叶斯风险。
[46]使用贝叶斯估计器来同时估计噪声水平和消除模糊。他们也提出GradNet来加速去模糊进程。与学习一个固定的图像先验相比,GradNet可以与不同的先验整合,并改进现有的基于MAP的去模糊算法。
[154]训练一套鉴别性的去噪器,并将其整合到基于模型的优化框架中,以解决非盲目去噪问题。
从[7,46,154]中学习到的先验指标并不总是能够处理带有异常值的模糊图像。如果不对离群点进行处理,这些非盲目去模糊的方法往往会产生振铃伪影,即使在估计内核准确的情况下。
注意到,一些超级分辨率方法(比例因子为1)由于其类似的问题表述,可以被用于非盲目去模糊的任务,例如USRNet
4 Blind Deblurring
这小节我们讨论盲去模糊方法,即潜在清晰图像和模糊核是未知的。
[16,24,76,107,140]早期的盲目去模糊方法主要是去除均匀的模糊现象
然而现实世界的图像通常包含非均匀的模糊,在同一图像的不同区域由不同的模糊核产生
[35,137]通过对三维摄影机运动的模糊内核进行建模来解决非均匀模糊的问题,虽然这些方法可以模拟平面外的相机晃动,他们不能处理动态场景,这促使人们使用移动物体的模糊场[10,27,40]。运动不连续和闭塞使模糊核的精确估计成为挑战。
[26,84,129]提出一些基于深度学习的方法用于动态场景的去模糊化。
Table2 代表性的单幅图像去模糊方法
- 第一阶段使用CNN估计模糊内核和潜像;第二阶段对模糊图像和潜伏图像进行操作以进行核估计
- 训练一个CNN,用盲法去模糊和去噪
- 两个生成网络分别捕捉模糊的内核和潜在的清晰图像,对模糊的图像进行训练
- 通过CNN从局部斑块估计运动核;一个MRF模型预测运动模糊场
- 训练一个网络以产生去卷积滤波器的复傅里叶系数,并将其应用于输入路径
- 一个多尺度的CNN生成一个低分辨率的去模糊图像和一个原始分辨率的去模糊版本
- 该网络对编码器特征进行回归,以获得模糊不变的表示,并将其送入编码器以生成清晰的图像
- 一个两阶段的CNN从模糊的图像中提取清晰的边缘,用于内核估计
- 通过一个空间变异的RNN进行去模糊化,其权重通过CNN学习
- 通过标度-递归网络进行去模糊处理,这个网络在不同尺度上共享网络权重
- 一个基于条件的GAN网络生成了真实的去模糊图像
- 一个无监督的GAN使用未配对的图像作为训练数据,执行特定类别的去模糊化
- 一个DAE网络根据不同的斑块恢复清晰的图像
- 一个运动去模糊的CNN利用了相机的陀螺仪读数
- 一个选择性的参数共享方案被应用于SRN架构,ResBlocks被嵌套的跳过连接所取代
- 通过对输入的内容和模糊特征进行分解的无监督的特定领域去模糊方法
- 一个通过Douglas-Rachford迭代来学习图像先验和数据保真度条款的网络
- DeblurGAN的扩展,使用特征金字塔网络和广泛的骨干网络,以提高速度和准确性
- 区域自适应致密变形模块发现空间变化的移位
- BGAN和DBGAN分别学习模糊和去模糊
- DAE框架,它首先估计模糊的内核,以恢复清晰的图像
- 基于事件的运动去模糊网络,引入一个新的数据集DAVIS240C
为了分析这些方法,我们首先介绍网络输入的帧聚合方法;然后我们回顾现有去模糊网络中使用的基本层和块;最后我们讨论架构,以及当前方法的优势和局限性
4.1 Network inputs and frame aggregation
单一图像去模糊网络将单一模糊图像作为输入,并产生相应的去模糊结果
视频去模糊方法将多个帧作为输入,并在图像或特征域中汇总帧信息
[120]图像级别的聚合算法将多个帧作为输入,并估计中心帧的去模糊结果
[162,41]特征级别的聚合算法,首先从输入帧中提取特征,然后融合这些特征来预测去模糊的结果
4.2 Basic Layers and Blocks
此部分简要回顾用于图像去模糊化的最常见的网络层和块
Convolutional layer 许多方法训练二维CNN来直接恢复清晰的图像,而不需要内核估计步骤。此外一些方法使用额外的先验信息,如深度或语意标签来知道去模糊过程
此外,二维卷积而被用于处理视频。单一图像和视频之间的主要不同是3D卷积,它可以从空间和时间两个领域提取特征
Recurrent layer 对于单幅图像的去模糊,递归层可以从粗到细在多个尺度的图像中提取特征。两个代表的方法是SRN,PSS-SRN。SRN建立了一个从粗到细的架构,通过一个共享权重的深度自动编码器去除运动模糊,而RSS-SRN包括一个选择性的参数共享方案,这导致了比SRN有更好的性能。 递归层也可用于提取视频中相邻帧的时间信息。与单幅图像去模糊化的主要区别是,基于视频的方法中的递归层从相邻的图像中提取特征,而不是在不同的尺度上只转移一个输入图像的信息。这些方法可以被分成两类,第一类将上一步的特征图转移到当前的网络中,以获得更精细的去模糊框架。第二类通过直接输入上一步的去噪帧来生成清晰的帧。
Residual layer 为了避免训练过程中梯度的消失或爆炸,全部残差层被用来直接链接图像去模糊的底层和高层。在GAN[57]中,其中去模糊网络的输出被添加到输入图像中,以估计出清晰的图像。在这种情况下,该架构等同于学习模糊和清晰图像之间的全局残差。局部ResBlock使用局部残差层,类似于ResNet中的残差层,这些被广泛用于图像去噪网络。全局和局部这两种残差层被结合起来以达到更好的性能。
Dense layer 使用密集连接可以促进解决梯度消失问题,改善特征传播,并减少参数的数量。[96]提出了一个区域自适应模块组成的区域自适应密集网络,以学习模糊图像中的空间变动的位移。这些区域自适应模块被纳入一个密集连接的自动编码器架构中。
[152]和[26]应用密集层来构建他们的去模糊网络,其中DenseBlocks被用来代替CNN层或ResBlocks。
Attention layer 注意层可以帮助深度网络专注于最重要的图像区域进行去模糊。[114]提出了一种基于注意力的深度去模糊方法,包括三个独立的分支,分别从前景、背景和全局上消除模糊。专注于人所在位置。其他方法采用注意力提取更好的特征图,例如使用自我注意力来生成非局部增强的特征图。
4.3 Network Architectures
我们将最广泛使用的用于图像去模糊的网络架构分为五组。
Deep auto-encoders(DAE),generative adversarial networks(GAN),cascaded networks,multi-scale networks;reblurring networks
**Deep auto-encoders(DAE)**深度自动编码器首先提取图像特征,解码器根据这些特征重建图像。对单一图像去模糊,许多方法使用U-Net架构和残差学习技术。在某些情况下,额外的网络有助于利用额外的信息来指导U-Net.[112]提出一个面部解析/分割网络来预测人脸标签作为先验因素,后使用模糊的图像和预测的语义标签作为U-Net的输入。其他方法应用多个U-Nets以获得更好的性能。[129]分析了不同的U-Nets以及DAE,并提出了一个处理模糊图像的scale-recurrent网络去处理模糊图像。第一个U型网络获得粗略的去模糊图像,并将其输入另一个U-Net以获得最终结果。[113]结合了两种想法,使用一个去模糊网络获得粗略的去模糊图像,再投入人脸解析网络,以产生语义标签。最后粗略去模糊图像和标签都被送入一个U-Net,以获得最终的去噪图像。
Generative adversarial networks(GAN)[57,58,84,112]大多数基于GAN的去模糊模型有相同的策略。生成器产生清晰的图像使得鉴别器无法将其与真正的清晰图像分开来。[57]提出了DeblurGAN,一个用于运动去模糊的端到端条件GAN。DeblurGAN的生成器包含两层卷积块、九个残差块和两个转置的卷积块,用于将模糊的图像转换成相应的清晰版本。之后延伸出了DeblurGAN-v2[58],它采用了相对条件GAN和双尺度判别器,用局部和全局分支组成。生成器的核心模块是一个特征金字塔网络,它提高了效率和性能。[84]和[112]来生成更好的去模糊图像。
Cascaded networks 一个级联网络包含几个模块,它们依次串联起来,构建一个更深的结构。可以被分成两类。第一种是在每一个级联中使用不同的架构,第一阶段的输入是一个模糊的图像,去模糊的输出被送入第二阶段以预测模糊的内核。第二种在每个级联中重新训练相同的架构,以生成去模糊的图像,来自前面阶段的去模糊图像被送入同一类型的网络中生成更精细的去模糊结果。这种级联方案可用于几乎所有的去模糊网络中。虽然这种策略取得了更好的性能,但是CNN参数的数量却大大增加。为了减少这些,最近的方法在每个级联中共享参数。
Multi-scale networks 输入图像的不同比例描述了互补的信息。多尺度去模糊网络的策略是首先恢复低分辨率的去模糊图像,然后逐步产生高分辨率的清晰结果。[84]提出了一个多尺度去模糊网络,以消除单一图像的运动模糊,网络首先产生1/4和1/2的结果,后估算出原始比例的去模糊图像。这种方法很常用,改善不同尺度的去模糊化,例如使用嵌套的跳过连接或者增加不同规模的网络连接,例如递归层的应用。
Reblurring networks. 重模糊网络可以合成额外的模糊训练图像。[152]提出一个框架,其中包括一个模糊化GAN和一个去模糊GAN。这种方法可以学习将清晰的图像转移到模糊的版本,并从模糊的版本中恢复清晰的图像。[12]介绍了一个用于视频去模糊的reblur2deblur框架。三个连续的模糊图像被送入该框架以恢复清晰的图像,这些图像被进一步用于计算光流和估计模糊内核以重建模糊的输入。
Advantages and drawbacks of various models U-Net框架已被证明对图像去模糊化和低水平视觉问题有效。用于有效的图像去模糊化的代替主干框架包括Resblocks或Denseblocks的级联。在选择主干后,深度模型可以通过几种方式进行改进。多尺度网络以从粗到细的方式消除不同尺度的模糊,但计算成本增加。同样地,级联网络通过多个去模糊阶段恢复更高质量的去模糊图像,去除模糊的图像被转发到另一个网络以进一步提高质量。主要的区别在于,多尺度网络中的去模糊图像是中间结果,而级联架构中每个去模糊网络的输出可以单独视为最终的去模糊输出。多尺度架构和级联网络可以通过将多尺度网络作为级联网络的一个阶段来结合。
图像去模糊化的主要目标是实现更好的内容,可以通过全参考指标如PSNR和SSIM来衡量。然而这些指标并不总和人的视觉感知一致。因此,基于GAN的结构可以被应用于生成真实的图像。在GAN结构中,上述所有的架构都可以作为生成器去使用,而判别器的目的是使去模糊的图像更加逼真。对于inference来说,只有生成器是必要的。基于GAN的模型通常在失真指标方面表现较差,如PSNR或SSIM。
当训练样本的数量不足时,可以使用再模糊网络来生成更多的,包括学习生成模糊和学习去模糊。以上讨论的任何一个深度模型都可以用来合成更多的训练样本,创建原始清晰图像和学习-模糊模型输出的训练对。虽然这个网络可以合成无限多的训练样本,但它只模拟那些存在于训练样本中的模糊效应。
像素错位的问题对于多帧输入的图像去模糊是一个挑战。对应关系通常是通过使用光流或集合变换计算连续帧中的像素关联来构建的。例如,一对嘈杂和模糊的图像可以通过光流进行图像去模糊化和补丁对应。在应用深度网络时,可以通过提供多幅图像作为输入,并通过三维卷积处理,来共同处理对齐和去模糊的问题。
5 Loss Functions
训练深度去模糊网络有很多种损失函数
在早期的深度去模糊网络中,像素级的内容损失函数被广泛用于衡量重建误差。但是,像素损失不能准确衡量去模糊图像的质量。这启发了其他损失函数的发展,如特定任务损失和对抗性损失,以重建更现实的结果。
5.1 Pixel Loss
像素损失函数计算去模糊图像和ground truth之间的像素差异,主要就是平均绝对误差和平均平方误差。然而由于像素损失函数忽略了长距离的图像结构,用这种损失函数训练的模型往往会产生过度平滑的结果。
5.2 Perceptual Loss
感知损失比较了高层次特征空间的差异,如为分类而训练的深度网络的特征。有第l层的分类器网络的输出特征。C是第l层的通道数。感知损失函数比较了清晰网络和其去模糊版本之间的网络特征,而不是之间匹配每个像素的值,产生视觉上令人愉悦的结果。
5.3 Adversarial Loss
对于基于GAN的去模糊网络,生成器网络G和鉴别器网络D被联合训练,使得G生成的样本能够骗过D。该过程可以被建模为一个最小-最大优化问题
为了知道G生成照片般真实的清晰图像,使用对抗性损失函数。对抗性损失直接预测去模糊的图像是否与真实图像相似,得到照片般真实的清晰图像。
5.4 Relativistic Loss
相对损失和对抗损失有关。D是输入是真实图像的概率,C是通过判别器捕获的特征,cigema是激活函数。在训练阶段,只有第二部分更新生成器的参数,而第一部分只更新判别器。为了训练一个更好的生成器,有人提出了相对论损失,以计算生成的图像是否比合成的图像更真实。基于这个损失函数,[152]用相对损失取代了标准对抗性损失。其中E表示对一批图像的平均化操作。生成器由相对论损失函数更新。
5.5 Optical Flow Loss
由于光流能够代表两个相邻帧之间的运动信息,一些研究通过估计光流来消除运动模糊。[29]建立一个CNN,首先从模糊的图像中估计运动流,然后根据估计的流场恢复去模糊的图像。为了获得成对的训练样本,他们模拟运动流以产生模糊的图像。[12]介绍一个reblur2deblur框架,其中三个连续的模糊图像被输入到deblur子网。然后三个去模糊图像之间的光流被用来估计模糊内核并重建输入。
A dvantages and drawbacks of different loss functions
上述所有损失函数都有助于图像去模糊化的进展。然而他们的特点和目标不同。像素损失函数使得在像素层面逼近与清晰图像,但通常会导致过度平滑。感知损失更符合人类的感知,而结果仍然表现出于真实清晰图像的明显差距。对抗损失和光流损失函数分别旨在生成真实的去模糊图像和运动模糊模型,但是它们对RSNR和SSIM的效果不太行,或者只对运动模糊图像起作用。多个损失函数也可以作为一个加权和,使得有它们的不同属性。
6 Benchmark Datasets for Image Deblurring
介绍去模糊的公共数据集。高质量的数据集应该反映真实世界场景中所有不同类型的模糊现象。我们还介绍了特定领域的数据集。人脸和文本图像,适用于特定领域的去模糊方法。
6.1 图像去模糊数据集
Levin et al. dataset包含4张尺寸为255*255的清晰图像和8张均匀的模糊内核。通过将真实的模糊核与清晰的图像进行卷积,该数据集共包含32张合成模糊图像。
**Sun et at. dataset.**在Levin的基础上添加80张高分辨率自然图像并应用模糊核得到640张图片。这个数据集只包含均匀的模糊图像,不足以训练强大的CNN模型。
Kohler et at dataset为了模拟非均匀的模糊,使用Stewart平台记录6D相机的运动并捕捉到打印的图片。有4个潜伏的清晰图像和12个摄影机轨迹,并产生了48个非均匀模糊的图像。
Lai et al. dataset包括100张真实的和200张合成的模糊图像,这些图像用均匀的模糊核和6D相机轨迹生成的。这个数据集涵盖了多种情况,如户外,人脸,文本和低光照图像,因此可以评估各种环境中的去模糊方法。
GoPro dataset创建了一个大规模的数据集,通过帧的平均化来模拟真实世界的模糊。一个运动模糊一个运动模糊的图像可以通过在一个时间间隔内整合多个即时和清晰的图像来产生。GoPro数据集已被广泛用于训练和评估深度去模糊算法。有3214张图片,分别为2103张训练集和1111张测试集。
HIDE dataset主要集中在行人和街景方面。创建了一个运动模糊的数据集,其中包括相机抖动和物体运动。包括6397和2025张图片。
RealBlur数据集为了对真实模糊图像的深度去模糊方法进行基准测试,创建了包括两个子集的RealBlur数据集。第一个是RealBlur-J,它是与相机的JPEG输出形成的,第二个是RealBlur-R包含RAW图片。RAW图像是通过使用白平衡、去马赛克和去噪操作生成的,包含9476张。
Blur-DVS dataset为评价基于事件的去模糊方法的性能创建。训练集和测试集分别包含1782,396张图片。还包括740张真实的模糊图像。
6.3 Domain-Specific Datasets
Text deblurring datasets从互联网上收集文本文件。这些数据被压缩到120-150DPI的分辨率,并被分成大小分别为50k和2k的训练集和测试集。小的几何变换与双三次插值也被应用于图像。运动模糊和焦外模糊被用来从清晰的图像中生成模糊的图像。还提供了一点图像样式的文本去模糊化数据集。
脸部去模糊化数据集模糊的人脸图像数据集是由现有的人脸图像数据集构建的。他们合成了20000个运动模糊核,生成了1.3亿张模糊的图像用于训练,并使用另外的80个模糊核生成了16000张图片用于测试。
7 Performance Evaluation
我们讨论了代表性的深度去模糊方法的性能评估。
7.1 Single Image Deblurring
主要是对三个受欢迎的数据集,GoPro,Kohler,Shen
[123],[29],[150]是三个早期基于CNN和RNN的深度去模糊网络,表明深度学习的方法取得了有竞争力的结果。
[84],[129],[26] 使用coarse-to-fine方案设计了多尺度网络,与单尺度去模糊网络相比,取得了更好的性能,因为粗的去模糊网络为更高的分辨率提供一个更好的先验。
除了多尺度策略外,GANs还被用来产生更真实的去模糊图像在[57,58,152],但在GoPro数据集上,基于GAN的模型在PSNR和SSIM指标方面取得的结果较差。
[96]将一种注意力机制应用到去模糊网络,并在GoPro数据集上取得了最先进的性能。在Shen数据集[114]的结果证明了其有效性。
使用ResBlocks[84]和DenseBlocks[152,26]的网络也比之前直接堆叠卷积层的网络取得更好的性能。
对于非UHD运动去模糊,多补丁架构的优势是比多尺度和基于GAN的架构更能恢复图像。这个可以归因于这种架构可以关注每个小补丁的细节。对于其他架构,如多尺度网络,小尺度版本的图像提供的细节较少,因此这些方法不能显著提高性能。
两种multi-scale和GAN方法取得了更清晰的模糊结果。对两种multi-scale方法,Tao等人利用不同尺度直接的递归操作,取得了更清晰的去模糊结果。
我们还使用LPIPS指标分析了GoPro数据集的性能。结果展示,当我们使用不同的评价指标时会得到不同的结论。在不同的量化指标中去评估去模糊的方法是至关重要的。由于评价指标优化了不同的标准,设计的选择是取决于任务的。
为了分析不同损失函数的有效性,我们设计了一个由几个ResBlocks(由DeblurGAN-v2提供)组成的共同主干。不同的损失函数,包括L1,L2,感知损失,GAN损失和RaGAN损失,以及它们的不同组合被训练。一般来说,当结合重建和感知损失函数时,所评估的模型表现更好。
为了评价非盲法和盲法单幅图像去模糊的性能差异,我们进行了一项研究,在RWBI数据集上比较有代表性的非盲法和盲法单幅图像去模糊方法。