DCNN已经成为图片生成及复原的流行工具,其出色的能力被认为是来自于能够从大量的实际图片数据中学习到一个很好的先验。而在本文中,作者表明仅仅是CNN所组成的生成网络结构,就已经能够很好的捕获图片的低级统计特征。一个随机初始化的网络可以作为一种手工设计的先验,并能很好的用于去噪、超分辨率、图片修复任务。
当然作者也从《Understanding deepearning requires rethinking generalization》中得到灵感,在该论文中C. Zhang等人用在一个训练集上表现很好的网络结构去基于另一个label都是随机给定的数据集上进行训练,发现居然出现了过拟合的现象。所以不能简单的将模型的性能归功于大量图像数据本身的信息。Dmitry Ulyanov等人认为,还有网络结构本身的作用没有分析清楚。
作者使用未被训练的CNN网络(其中的权重都是随机初始化的),然后数据上只需要输入一张被损坏的图片。在这个过程中,网络的权重扮演着图像恢复时候所需要的参数:即给定一个随机初始化的网络,然后基于给定的受损图片和任务依赖的观测模型,通过迭代使得模型参数逼近最大似然。
DNN用来做图像生成的原理就如自动编码器的解码部分一样,即学习一个生成器(也可以如AE中叫做解码器)。该方法可以从随机分布中采样真实的图片,甚至这个分布还能限制成如受损的观测样本 x0 x 0 表示的分布。这样的想法自然可以应用于解决逆向的问题,如消噪和超分辨率。作者主要研究了在基于未训练的基础上,不同的生成器网络结构隐式抓取的先验。它还弥补了两种通用的图像恢复方法之间的鸿沟:即使用深度卷积网络的基于学习的方法和基于手动图像先验(如自相似性)的无学习方法。
网络可以表示为参数化形式 x=fθ(z) x = f θ ( z ) , x x 是输出图片,
是网络输入端的随机编码向量。
去噪、超分辨率、图片修复等可以表示为能量极小化问题
E(x;x0) E ( x ; x 0 ) 是任务依赖项, x0 x 0 是带噪声、低分辨率或损坏图片, R(x) R ( x ) 是正则化项。这里先介绍下第二项,也就是一个抓取自然图片上通用先验的正则化项,它相比第一项更困难,而且是许多研究论文的重点。举个简单的例子, R(x) R ( x ) 可以是一个图像的Total Variation(TV),从而希望训练好的模型能够包含统一区域。而在这里,作者用一个神经网络(用它来抓取隐式先验)来代替这里的显式正则化项,其中网络的参数选取如下
θ∗ θ ∗ 是在随机初始化的基础上进行梯度下降训练到的,给定一个(局部)最优的参数 θ∗ θ ∗ ,图像恢复的过程为 x∗=fθ∗(z) x ∗ = f θ ∗ ( z ) 。这里的编码 z z 也是可以优化的,不过作者这里只进行了随机初始化,并且保持固定不变。这里的 是一个 3D 3 D 张量,输出32个特征图,大小和 x x 一样,但内容是随机数据。而且每次迭代时随机扰动 会带来更好的实验效果,这相当对 z z 施加的正则化(虽然这会使优化速度更加缓慢),可以理解为,这样可以使 与 z z 无关,从而使网络学习到更多的 图片信息。因为该网络结构只使用了一张损坏的图片,并没有经过大量数据的预训练,所以这样一个deep image prior先验是完全人为设计的,就如TV norm一样,而不是从数据中自动学习到的。作者通过实验发现,这样的手动设计的先验对于各种不同的图像恢复任务来说效果还是很好的。
高噪音阻抗的参数化。也许有人会疑惑,为什么一个high-capacity的网络 fθ f θ 可以作为一个先验。事实上,我们只期望能够找到参数 θ θ 以去恢复任何包含了随机噪音的图像 x x ,所以该网络在其生成的图片上不应该带入任何的限制才对。不过作者的工作显示,虽然大部分图像的确都可以被拟合,不过网络结构的选择对于解空间的搜索还是一个主要的影响。比如网络比较抵制“坏”的解,并且对于看似自然的图片收敛的更快。如果将这个影响进行量化,那么引入一个最基本的重构问题:给定一个目标图像 ,我们希望找到参数 θ θ 可以重构这个图像。该问题表示为
下图展示了在四种不同图片的情况下,能量函数值 E(x;x0) E ( x ; x 0 ) 执行梯度下降迭代时的变化曲线。

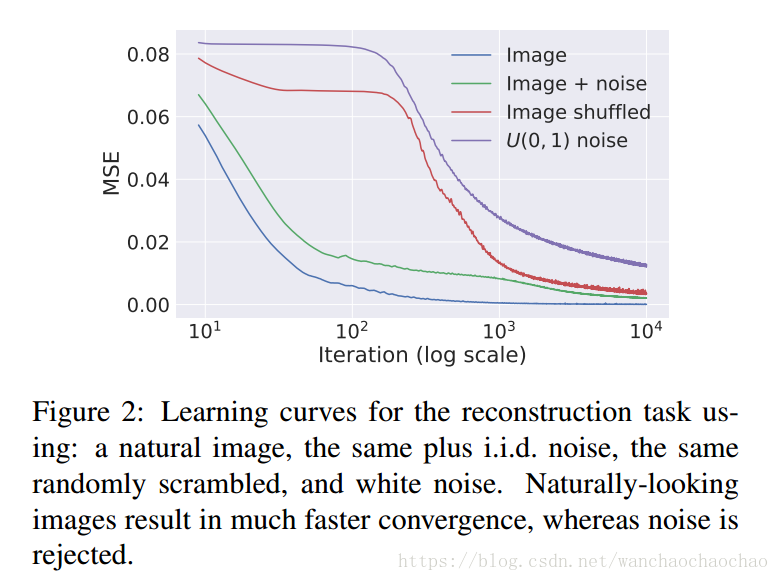
可以看出在1和2下,mse下降的最快;而在情况3和4上,则有着明显的”惯性”。因此,虽然这时也可以参数化拟合无结构噪音,但是它却是很耐抗的,换句话说,参数化拟合训练过程提供了对噪音的高阻抗和信息的低阻抗。因此可以通过限制优化过程的迭代次数,过滤高阻抗的噪声,留下低阻抗的自然图片信号,实现去噪的目的。
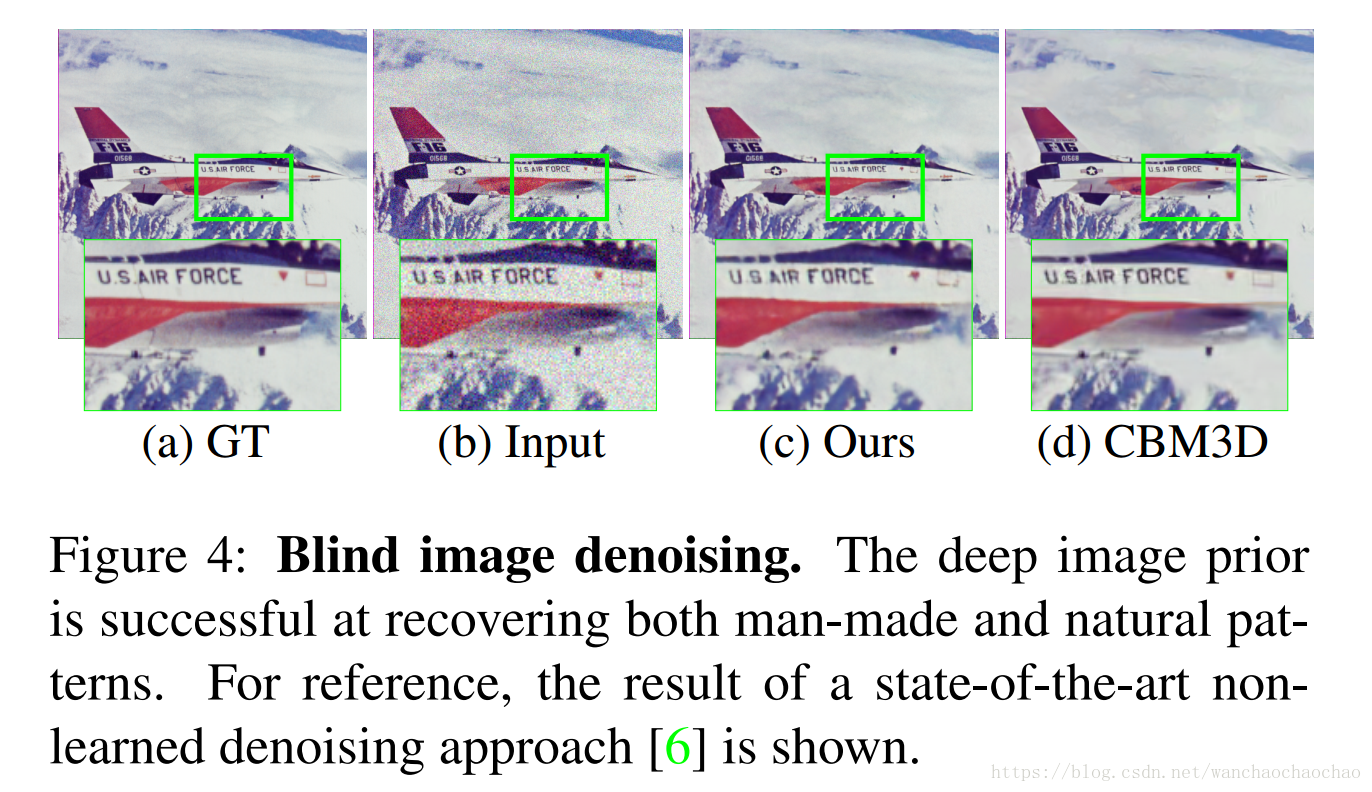
去噪和图片重建。由于CNN结构的参数化会使其对于图片噪声具有高阻抗,这自然可以被用来过滤噪声。去噪的目的是从一个带有噪声的图片 x0 x 0 恢复出一个干净的图片 x x ,产生噪声的模型为 , ϵ ϵ 来自于一个特定分布,但是一般来说具体的噪声模型是未知的。我们在这里就假设噪声模型未知,不过这个方法也可以很容易地改进成知道噪声模型的情况。
具体过程为
1.用随机参数 θ θ 初始化CNN网络 fθ f θ ;
2.令 fθ f θ 的输入为固定的随机编码 z z ;
3.令 的目标为:输入 z z ,输出 ,以此训练 fθ f θ 的参数;
4.注意选择合适的损失函数,例如对于降噪问题可关注整体的MSE,对于填充问题就应该只关心不需要填充的位置的MSE;
5.当训练很久之后, fθ f θ 可实现输出一模一样的 x x ;
6.但如果在训练到一半时打断 ,会发现它会输出一幅“修复过的 x x ”。
这意味着,深度卷积网络先天就拥有一种能力:它会先学会 中“未被破坏的、符合自然规律的部分”,然后才会学会 x x 中“被破坏的部分”。例如,它会先学会如何复制出一张没有噪点的 ,然后才会学会复制出一张有噪点的 x x 。
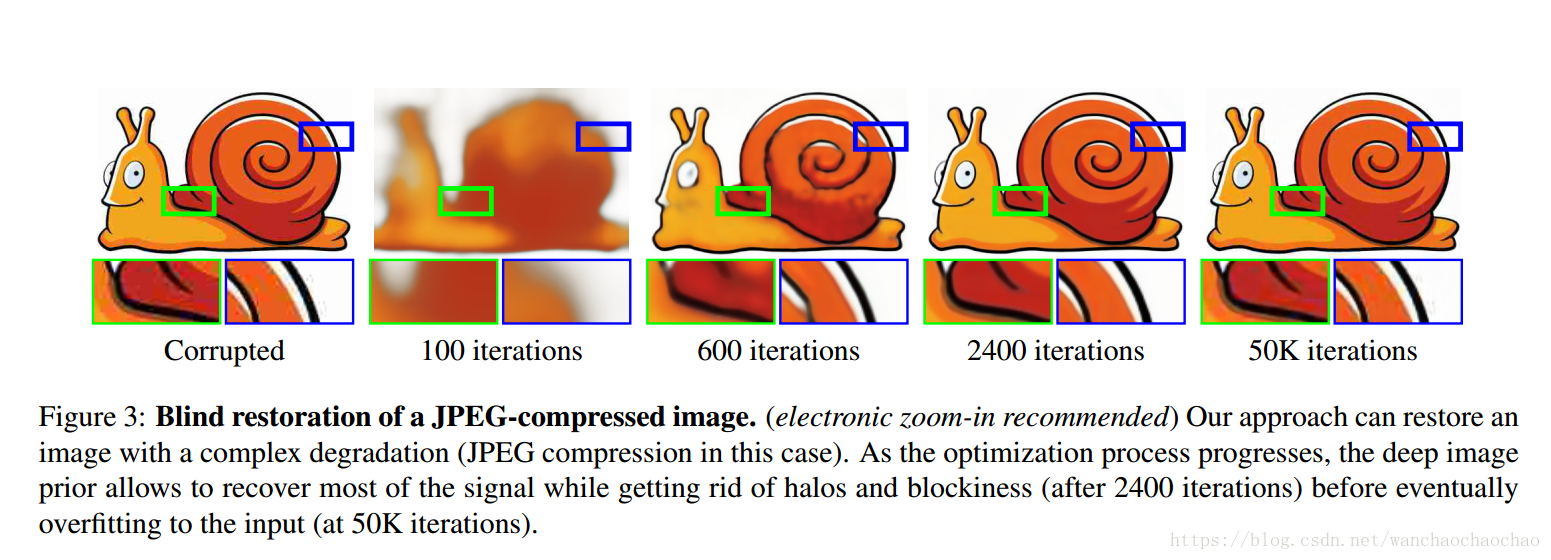
超分辨率。超分辨率问题是给定一个低分辨率图片 和一个上采样因子 t t 后,产生一个与之对应的高分辨率图片 。问题表示为
其中 d(⋅):R3×tH×tW→R3×H×W d ( ⋅ ) : R 3 × t H × t W → R 3 × H × W 是因子为 t t 的下采样操作。超分辨率是欠定病态问题,因为存在很多个高分辨率的 与低分辨 x0 x 0 对应,所以需要添加正则化从而可以在无数个 x x 中选出尽量好的结果。

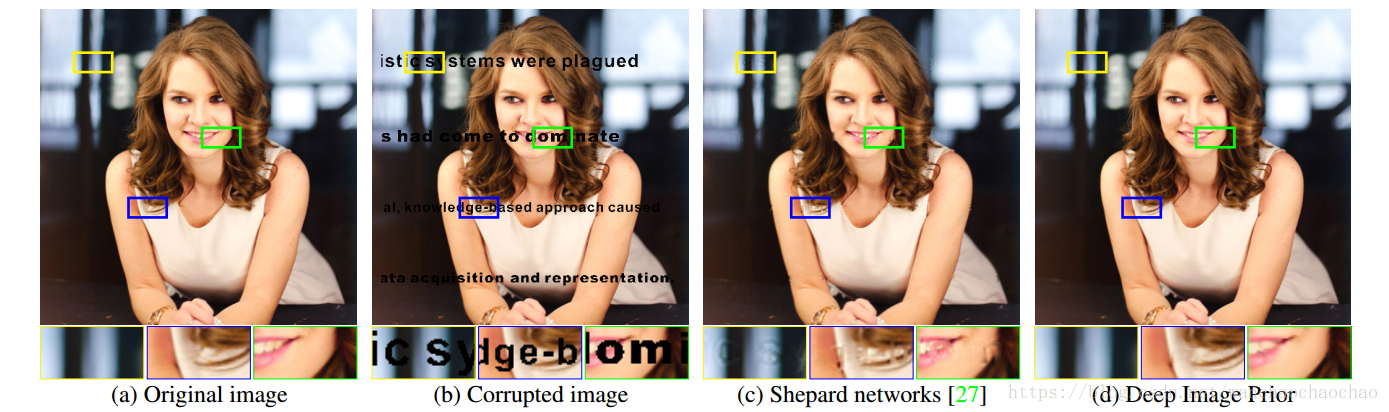
图片修复。给定一个损坏图片 ,其中有一部分像素缺失了,以及一个对应的缺失像素二值掩模 m∈{ 0,1}H×W m ∈ { 0 , 1 } H × W ,问题求解表示为


论文地址
Github
知乎