Mixture of Deep Neural Networks for Instancewise Feature Selection
基于混合深度神经网络的实例特征选择
摘要
在机器学习模型中,学习相关特征对于解释数据非常重要。与为整个数据选择相关特征子集相比,实例特征选择对于模型解释更为灵活。然而,目前的基于实例的特征选择方法比较复杂,计算量大。我们考虑监督学习框架下的实例特征选择。我们设计了一个紧凑的和可解释的神经网络来解决这个问题。为了减少计算量并获得更好的可解释性,我们将相关特征分组并构建混合神经网络。使用softmax作为子模型选择的激活函数,通过梯度下降可以准确地学习模型成员。据我们所知,我们的模型是第一个使用端到端训练进行实例特征选择的可解释深度神经网络模型。
索引项
实例特征选择、深度学习、模型混合。
I. INTRODUCTION
当机器学习模型应用于金融市场、医学和安全等领域时,可解释性对其至关重要。由于高维和大量数据的存在,复杂的机器学习模型,如核方法、集成方法和深度神经网络可以达到较高的精度,但结果难以解释。特征选择为整个数据集拾取全局相关特征,而实例特征选择为每个数据样本生成解释。[1]中提出了一种基于实例的特征选择方法来解释模型,该方法被称为学习解释(L2X,Learning to Explain)。它使用互信息作为评价特征重要性的标准。
在L2X之前,大多数解释方法都是基于训练模型分析单个样本特征的重要性。与[2]、[3]类似,通过局部相加模型近似模型来解释模型。参考文献[4]根据输出相对于输入的梯度选择重要特征。实例特征选择提供了一种解释嵌入在训练过程中的模型的方法。从而在提取相关特征的同时提高模型精度。为了通过子集采样反向传播梯度,L2X使用[5]中的Gumbel-softmax技巧为每个样本选择前l个相关特征。然而,在我们解释模型之前,l通常是未知的。此外,可能并非所有数据都具有相同数量的相关特征。 在[6]中,使用神经网络(INVASE)进行实例变量选择,作为消除L2X限制的模型。该模型由三个深度神经网络:选择器网络、预测网络和基线网络组成。它利用神经网络的大容量来构造特征选择和预测网络。为了优化网络,它采用了actor-critic框架,允许通过采样进行反向传播。
为了测试性能,[6]生成不同的模拟数据。在某些数据集中,不同的数据样本可能具有不同数量的相关特征。对于这些数据集,[6]可以实现高精度以及选择正确的相关特征。当所有数据共享一个全局相关特征子集时,它还可以识别相关特征。[1]、[6]都不限制每个样本的搜索空间。它会导致指数搜索空间,因此这两种算法的计算成本都很高。
为了减少搜索空间,我们的工作假设可能的相关特征子集的数量是固定的。我们提出了一个混合模型来满足这个假设。这样的条件计算可以保持较大的学习能力,而计算量的增长很小。我们将展示我们的模型可以达到高精度,并提供更好的解释性。我们的方法将局限于可能的相关特征子集数量不太大的问题。否则,非参数方法将更合适。
我们的网络结构类似于[7]提出的混合模型。稀疏混合神经网络利用条件计算来实现容量增加,而无需按比例增加计算量。然而,这种模型尚未用于实例特征选择和模型解释。[7 ]不考虑单个模型决定输出的情况,这是我们关注的焦点。据我们所知,我们的工作是第一个使用混合深度神经网络(DNN)来解决实例问题。基于随机梯度下降,我们的模型可以非常准确和有效地解决这个问题,具有良好的解释性。
II. PROBLEM FORMULATION
在监督学习环境下,我们考虑了一个实例特征选择问题。我们专注于分类问题,并且我们的模型可以很容易地扩展到回归。假设我们有N个i.i.d训练数据对(xi,yi)i=1N,其中x∈ X在Rd表示输入数据,y ∈ {1,…,C}表示输入数据是离散输出标签。我们关注两个目标,即预测和实例特征选择。预测是为了揭示x和y之间的关系。实例特征选择是选择特征子集向量s∈ {0,1}d表示每个数据样本,其中si=1表示选择了第i个特征,si=0表示未选择第i个特征。良好的s应与预测相应的输出标签y相关。Instancewise特征选择旨在找到选择器函数S:X→ {0,1}d,使得对于几乎所有的数据对(x,y),
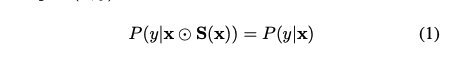
在分类框架中,评估S的标准嵌入在x和y的估计yˆ之间的差异中。我们使用交叉熵来量化差异。也可以使用其他损耗,如最小二乘损耗、精度等。对于判别部分,目标是了解x与y的关系。正如DNN中常用的那样,我们使用one-hot概率向量p来表示y,这样p的第i个元素等于P(y=i|X),i=1,2,…,C。
允许∆ C-1表示C-1单纯形:
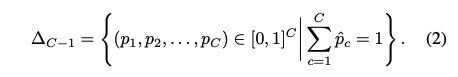
我们希望构造一个函数f:Rd→∆ C-1,输出数据样本x的预测类概率向量p。 函数f将由θ 参数化,并将被写入f(x;θ )。它将实例特征选择与判别学习相结合。我们将根据可用特征对某些目标函数的梯度进行排序,以识别每个实例的相关特征。这将在下一节中详细介绍。样本x’s真实标签y和估计标签之间的交叉熵可以表示为:
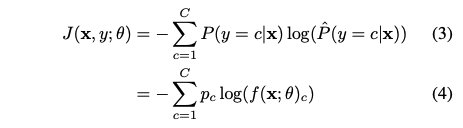
其中,下标c指的是f(x;θ )的第c个元素。
III. PROPOSED MODEL
INVASE假设每个样本都可以有不同的相关特征子集。每个示例都有2d可能的特征子集。对于N个训练样本,可能的选择结果数为2dN。搜索空间是数据维数和样本大小的指数。在实践中,数据点更有可能由一些“模式”生成,因此在每个模式中,都有一组相关特征。基于这一观察,我们施加了一个约束,即完全只有K个特征子集,这样每个样本的相关特征由其中一个K子集给出。通常,K≪ 2d。设K个可能的特征子集表示为{s{1},…,s{K}}。每个数据样本x都有一个唯一的相关特征选择器S(x)∈ {s{1},…,s{K}}。
为了对约束进行建模,我们建议混合使用K种不同的判别模型。我们分两步实现了实例化特征选择。首先,我们需要确定样本x取自哪个判别模型。其次,所选子模型将选择一个全局特征向量并将其分配给样本。
A.子模型选择
我们假设每个样本仅从一个子模型生成。使用M(x):Xd→ {0,1}K将x映射到模型选择向量m。M(x)输出数据x从子模型k生成的概率,k=1,…,k。M应为一个one-hot向量。在此向量中,只有真实子模型的值为1,否则为0。如果样本对(x,y)由子模型k生成,则条件概率分布为
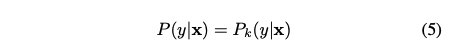
其中Pk指第k个子模型的条件分布。更一般地,我们可以把P(y|x)写成K个子模型的线性组合
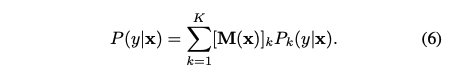
我们使用估计量Mˆ(x)来近似M(x)。如果我们将Mˆ(x)约束为输出一个one-hot向量,问题将变得离散,这也使得损失函数不可微。因此,梯度下降不能用于优化损耗。为了克服这个障碍,我们放松约束,让Mˆ(x)是从Xd到K−1的单一映射∆K−1.
softmax函数σ:RK→ RK通常用作概率归一化。它由以下公式定义:
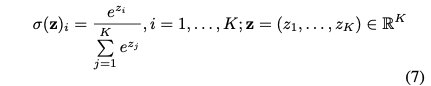
以函数Mˆ(x)为例,用激活函数softmax的一层神经网络对子模型进行建模
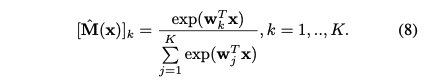
B.讨论
1) 为什么选择softmax:我们的模型与普通模型的关键区别在于模型选择层,这对问题至关重要。如果我们可以为每个数据样本预测正确的子模型,那么我们可以根据模型标签对数据进行聚类。在这之后,问题变得微不足道,因为我们只需要解决K个全局特征选择问题。因此,子模型选择是模型优化的瓶颈。如果我们使用argmax作为激活函数,则表示输出神经元是参数的分段常数函数。根据反向传播规则,所有子模型选择的参数始终具有0个梯度。因此,用梯度下降法训练网络是不可能的。另一种方法是保留最大值,并将剩余值设置为0。虽然[7]可以直接使用反向传播来训练网络,但原因是他们选择了多个模型,而不是只选择一个。为了进行概率解释,将在选择最可能的模型后应用softmax。当选择多个模型时,softmax函数可以进行归一化,输出不是分段常数,而是在单纯形空间中变化。因此,梯度不会始终为0。然而,在我们的例子中,只选择了一个子模型,该值将始终标准化为常数1,因此梯度为0。
为了解决这个问题,[8]提出了一种“直通式”估计来近似梯度。设计了二元神经网络和反向传播规则。然而,这些方法并不准确,也不容易实现。
因此,我们使用softmax作为激活,在没有任何正则化项的情况下,它在模型预测中表现出良好的性能。模型的估计概率几乎是稀疏的。在推理阶段,我们将为样本分配模型概率值较大的子模型。
2) 无正则化:为了逼近one-hot向量,可以在子模型概率中添加正则化项。one-hot向量是稀疏的,因此将考虑稀疏正则化。通常使用的l1范数正则化在我们的模型中并不有用,因为我们使用softmax函数作为激活来预测子模型成员。Softmax函数允许所有成员的值总和为1。l1范数始终是一个常数,因此不能作为惩罚项影响损失函数。
对于两个模型的混合,子模型概率预计为二维one-hot向量。一种可能的惩罚是最大化成员们之间的差异|mˆ1− mˆ2|。项越大,成员向量越接近一个one-hot向量。 −λ|mˆ1− mˆ2|形式的惩罚术语将是凹形的,这可以使优化问题变得困难。当K>2时,几乎没有直观的正则化来近似one-hot向量。我们决定优化损失函数,而不对模型选择进行任何正则化。以两种模型的混合为例,我们的数值结果显示了令人满意的结果。随机梯度下降可以获得近似稀疏的值,即两种模型概率之间的差异相当大。这种现象可能是由于模型假设很好地拟合了数据,并且它可以被视为一种强大的先验知识,可以隐式地规范学习过程。
C.K个子模型的混合
我们假设子模型估计是
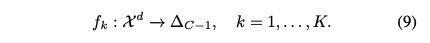
它们共享相同的网络结构,但参数不同。因此,参数θ可分为K组,即θ={θ1,…,θK}。第k个模型选择全局特征Sk(x)≡ sk∈ {0,1}d。特征选择后,鉴别结果应相同,即。
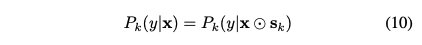
我们估计样本x的分类结果使用混合K DNNs。因此f可以写成:
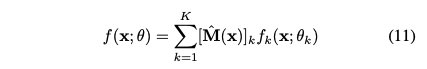
其中fk(x;θk)用于近似Pk(y|x)。在下文中,fk是一个多层神经网络,在这种情况下,θk由所有层的权重和偏差组成。
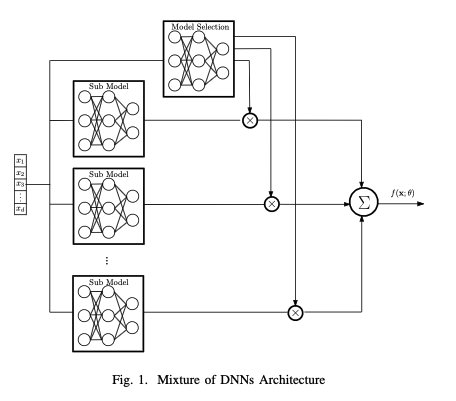
我们使用图1说明了我们的模型。首先使用神经网络估计子模型概率。然后每个子模型独立地输出自己的分类标签分布。最后,所有估计的标签分布将线性组合。
为了优化整个模型f,我们将最小化训练数据上的交叉熵之和。在推理阶段,将具有最大概率的类标签分配给样本。除了为每个数据样本确定正确的标签外,另一个重要目标是选择最相关的特征子集,即找出s{k}。这将帮助我们解释输入和输出数据之间的相关性。我们使用连续向量sˆ{k} ∈ Rd近似于s{k}。我们使用fk对x的灵敏度大小作为估计量。
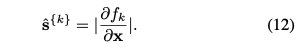
sˆ的元素将用作特征的分数,并对其进行排序,以便选择与前l值对应的特征作为相关特征。
IV. EXPERIMENTS
为了验证有效性,我们在模拟数据集上测试了我们的模型,其中相关特征是已知的,并且可以验证。我们将使用L2X[1]中的中值排序来评估特征选择性能。这些特征将根据s{k}进行排序。每个子模型都有自己的特征排序,排序基于所有的训练数据。在模拟数据中,真实相关特征的中位数是已知的。我们的模型可以估计真实特征的等级。我们可以观察估计秩的中值,并与ground真实值进行比较。我们还将我们的模型与INVASE[6]和L2X[1]进行了比较。为了公平比较,INVASE[6]中的预测网络与我们的子模型具有相同的体系结构。L2X[1]中要解释的模型也是如此。对于L2X[1],其解释网络如[1]所示。
在本节中,我们使用INVASE[6]设计的相同数据集。输入x的维数为d = 11,每个维数都是独立同分布(i.i.d)高斯分布。输出标签y是从伯努利分布中采样的。
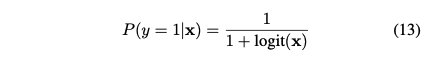
logit(x)函数在以下情况下不同。我们同时考虑全局特征选择和实例特征选择。全局特征选择是实例特征选择的一种特殊情况。看看混合的dnn是否能对具有全局特征的数据集做出正确的决策,这将是很有趣的。在这种情况下,测试3个数据集:
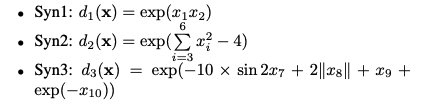
其余的数据集是为实例特征选择而设计的,每个样本的标签是从两个子模型中的一个生成的。其logits功能如下:
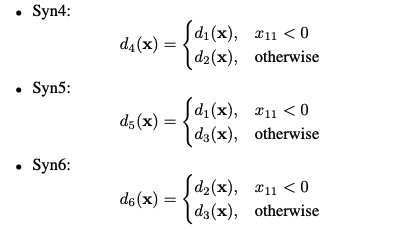
对于数据集Syn4和Syn5,两个相关的特征子集的大小不同。因此,L2X不可能训练模型,因为它需要对顶级l特性进行采样。我们为所有数据集生成20000个样本。数据随机分为9000个训练数据样本,1000个验证数据样本和10000个测试数据样本。验证数据用于监控训练过程。
子模型选择是一个具有softmax激活功能的双节点层。这2个子模型中的每一个都有相同的3层架构。第一层和第二层都有2d节点。当网络处理数据集Syn1、Syn2、Syn3时,激活函数为RELU
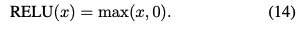
对于数据集Syn4、Syn5和Syn6,激活函数为比例指数线性单元(SELU)
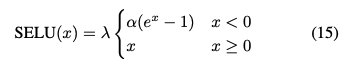
其中λ,α在[9]中设置默认值。最后一层将输出预测的类概率。
我们使用Tensorflow框架[10]来实现学习过程。对于L2X[1]和INVASE[6],我们在Github上使用它们的实现。L2X和INVASE的实现可以在GitHub - Jianbo-Lab/L2X和GitHub - jsyoon0823/INVASE: Codebase for INVASE: Instance-wise Variable Selection - 2019 ICLR上找到。所有的实现都运行在一个Nvidia GeForce GTX 1080Ti GPU上。在训练过程中,我们使用交叉熵作为损失函数,并使用Adam对其进行优化。学习速率设置为0.08,最大时间为3000。当验证错误在两个以上的时间间隔内停止减小时,训练过程将提前停止,否则继续训练,直到达到最大时间间隔。我们对所有正则化系数为1e−3的网络权值使用权值衰减。
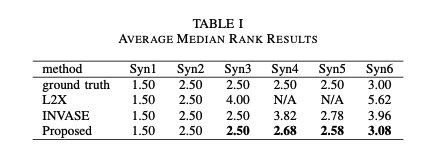
表1显示了所有测试数据的平均中位数排名结果。它列出了ground truth, L2X, INVASE和我们的方法的结果。Ground truth是所有算法能够实现的最低中值排序结果。中值秩越低,特征选择结果越好。对于Syn1、Syn2和Syn3,除了数据集Syn4上的L2X之外,几乎所有的方法都可以准确地选择真正的特性。结果表明,所有方法都能较为可靠地选择全局特征。在本例中,我们的方法的两个子模型选择相同的相关特性。对于更复杂的情况,如Syn4、Syn5和Syn6, x11也被认为是一个相关的特性,也是决定标签的特性。我们的结果是最好的三个复杂的数据集。与ground truth的偏差是由于子模型预测错误造成的。
当K较小时,我们的模型在训练参数的数量上具有较低的模型复杂度。当K变大,我们将失去低模型复杂度的优势。如果one-hot向量近似不准确,我们可能需要更多的训练时间。在推理阶段,我们仍然有优势,因为我们只需要计算一个子模型。
V. CONCLUSION
在本文中,我们建议使用混合DNN进行实例特征选择。该模型结构紧凑,易于解释,并且易于使用随机梯度下降进行训练。通过数值算例表明,特征选择结果是准确的,并与现有的方法进行了比较。进一步的工作将考虑更复杂的场景,如高维数据或少量标签。另一个扩展是更精确的one-hot近似和注意机制。