[1] Borisov V , Haug J , Kasneci G . CancelOut: A Layer for Feature Selection in Deep Neural Networks[C]// 2019.
CancelOut: A Layer for Feature Selection in Deep Neural Networks
摘要
特征排序(FR)和特征选择(FS)是数据预处理的关键步骤;它们可以用来避免维数灾难问题,减少训练时间,提高机器学习模型的性能。在本文中,我们提出了一个新的深层神经网络层-CancelOut,可用于FR和FS任务,用于监督和非监督学习。实验结果表明,该方法能够找到优于传统特征分析方法的特征子集。此外,该层易于使用,只需向深度学习训练循环中添加几行额外的代码。我们使用PyTorch框架实现了所提出的方法,并将其在线发布(代码可从www.github.com/unnir/CancelOut获得)。
https://github.com/unnir/CancelOut![]() https://github.com/unnir/CancelOut
https://github.com/unnir/CancelOut
关键词:
深度学习·特征排序·特征选择·无监督特征选择·机器学习可解释性
1 Introduction
机器学习(ML)模型的特征重要性和可解释性近年来受到了广泛关注,因为准确的估计并不总是足以解决数据问题。对机器学习模型结果的解释不仅有助于理解模型的结果,而且有助于引入新的测试,更好地理解数据,并因此提高对模型的信任,这在其他领域的专家使用模型时非常重要。然而,通常无法解释最精确和稳健的ML模型[4]。
当今最有效的ML方法之一是深度学习(DL),它可以用普遍逼近定理[2]来解释。它主要说明Rn上的任何紧支撑连续函数都可以用一个隐层前馈神经网络(NN)来逼近。然而,由于DL固有的高度复杂性,大多数DL模型主要作为黑盒处理。尽管最近已尝试解决其可解释性和特征选择问题[1,4],但现有的方法是复杂的。
2 Related Work
许多关于使用DL的特征排序(FR)和特征选择(FS)的研究文章都提出了置换方法,这种方法基于这样一种思想:如果我们从数据集中删除或破坏特征,性能将发生变化。通过分析这些变化,可以确定某个特征是否有价值。这种想法的明显缺点是计算量大,为了检查n个特征,需要至少对DL模型进行n次训练。
[1]中提出了另一种类似的策略,其中利用dropout层进行特征排序[12]进行特征排序。为了分析哪些特征是重要的,带有dropout层的人工神经网络模型必须实现最小损失,dropout层应该学习重要特征的小dropout率,同时增加其余不重要特征的dropout率。在这种情况下,模型可以运行一次。
论文[6]提出了一种有趣的方法,用于量化单个输入信号对深度神经网络计算的输出的影响。该方法基于对网络中每个神经元的局部线性模型的估计,并将这些模型传播和聚合成网络范围的模型。
[9]中的工作引入了与弹性网络正则化线性模型类似的思想,但它采用了多层神经网络。该方法同时使用l1和l2范数对损失函数中的输入权重进行正则化;如果没有这些项,该方法是不稳定的。
此外,许多文章对单个数据样本的ANN决策的解释进行了研究[13]。然而,这种方法很难应用于整个数据集的特征排序。
本文分为四个部分。
在第3节介绍了所提出的特征排序方法。
第4节介绍了研究的实施和结果。
最后,第5节是工作总结。
3 CancelOut
在本节中,我们为深层神经网络提供了一个新的层-CancelOut,一种帮助识别数据集中相关输入特征(变量)子集的方法。该方法也可用于特征灵敏度分析。
CancelOut是一个人工神经网络(ANN)层,与完全连接(FC)层相比有一个区别:FC层中的神经元连接到每个输入,而CancelOut层中的神经元仅连接到一个特定输入(图1)。

CancelOut层背后的主要思想是在训练阶段更新其权重(Wco),以便使用负权重(等式1)取消不相关的特征。另外,对学习过程贡献更大的最佳变量将以正权重传递。
CancelOut(X) = X ⊙ g(Wco) (1)
其中⊙ 表示元素相乘,X是输入向量X∈ RvN,Wco是权重向量Wco ∈ RvN,Nv是特征尺寸,g是激活函数。注意,g(x)在这里表示元素应用,例如:
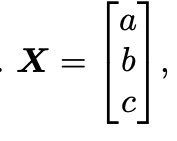
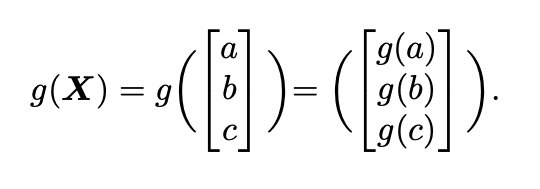
3.1 Theoretical Justification of the CancelOut Layer
为了简单起见,考虑在层(2)和(3)之后具有线性激活功能的三层人工神经网络(图1),其中具有sigmoid激活函数σ的 CancelOut层被用作输入层(上标(1))。注意,简单起见,FC层中的偏置项被省略。然后,网络的输出由下式给出:
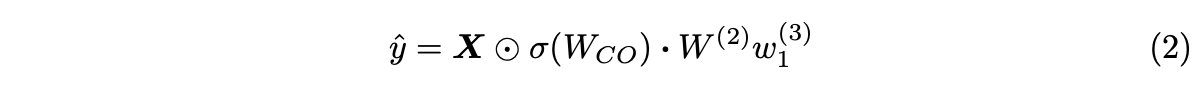
其中X = [x1, x2, x3], Wco ∈ R3,W(2) ∈ R3,w1(3) ∈ R,注意 · 是两个向量的点积。
Eq. 2可以看作是一个线性回归模型:
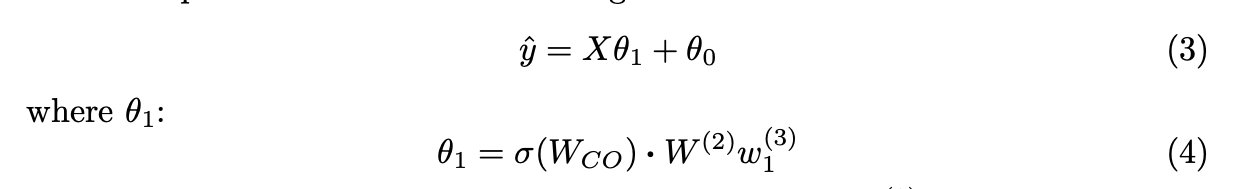
当隐层(2)中有多个人工神经元时(图2),输出为:

由式2可知,若CancelOut层中激活函数g(wco(1))后任意值为0,则对应的g(wco(1))的输入值xn也为0。下面的引理总结了这个观点。
引理1。如果CancelOut层的激活函数后的值为0,则相应的输入变量不影响ANN的输出。
举例说明:让CancelOut层的激活函数之后的值为0。
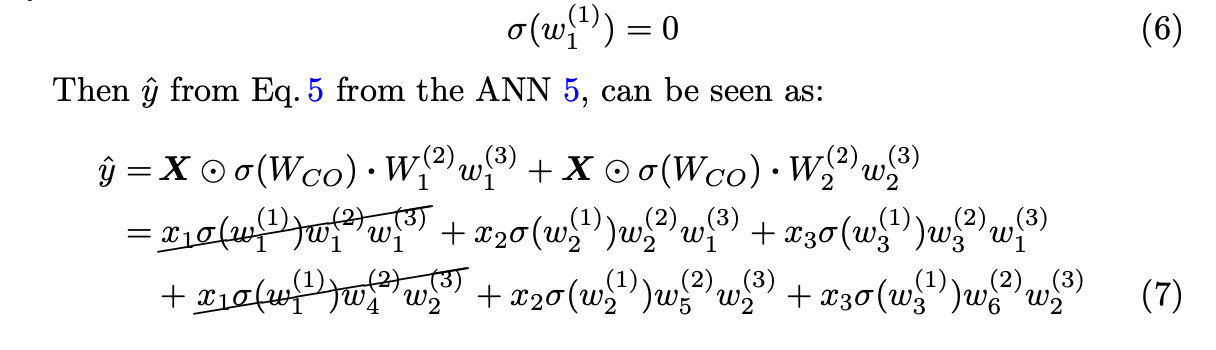
备注1。显然,如果在Eq. 7中w1(2) = w4(2) = 0,并且bias项(此处省略偏差项,见第3.1节)也是0,那么CancelOut权值w1(1)不代表有益信息。为了避免这种结果,我们建议考虑以下建议:
-
在CancelOut层之后选择适当的激活函数有助于绕过这个问题
-
正则化项可用于损失函数中
-
最后,建议在CancelOut层之后的层中加更多人工神经元,因为这减少了在W(2)CancelOut层之后的层中所有神经元权重为零的可能性。
此外,如果CancelOut层中的权重wi为0,那么相对于wi的梯度为0。下面的引理总结了这个观点。
引理2。如果CancelOut层的激活函数后的值近似为0,则权值的梯度也近似为0。
结合引理1和2,我们得到以下定理:
定理1。CancelOut层中激活函数之后的值表示对相应变量输出的贡献。
因此,CancelOut层以类似于线性模型的方式对特征进行排序,例如,CancelOut层中的绝对值越大,相应的输入变量对输出的贡献越大。此外,与线性模型相比,CancelOut方法考虑了输入数据的线性和非线性组合。
备注2。CancelOut值σ(Wco(1))中系数为零会导致优化参数较少,因此模型学习速度较快。这也有助于减少特征的数量,从而减轻过拟合。另外,使用CancelOut层进行特征选择可以在两种场景中使用;用户可以指定特征的数量,也可以使用所选的阈值提取特征。
我们的FR方法类似于[9],但在我们的工作中,输入标量σ(Wco(1))在所选间隔内被绑定(例如,对于sigmoid激活函数为0,1)。因此,我们的方法更稳定,而且由于用户只选择一个阈值,所以对特征进行排序更简单。此外,CancelOut-FR方法不需要损失函数中的惩罚系数。
3.2 CancelOut Layer Weights Initialization
CancelOut层不需要随机权重初始化,因为它可能会使特征的一个子集优于另一个子集。因此,使用均匀分布[5]和附加β系数初始化权重:
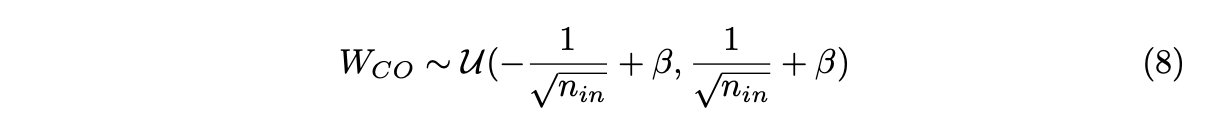
其中nin是前一层的大小,β是取决于激活函数选择的系数。
我们在等式8中引入了β系数,以控制激活函数g(WCO)后的初始输出值,它需要为g(WCO)!=0,因为我们假设每个特征都同等重要,例如对于逻辑激活函数β ∈ [−3,inf)。
3.3 Loss Function
为了加速CancelOut层中的特征排序过程,我们在损失函数中引入了两个正则化项(等式9):
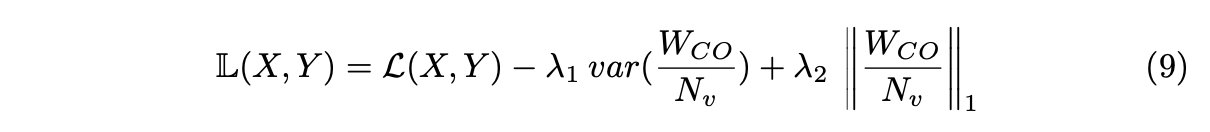
其中,L是一个选定的损失函数,对于分类任务,它可以被视为:
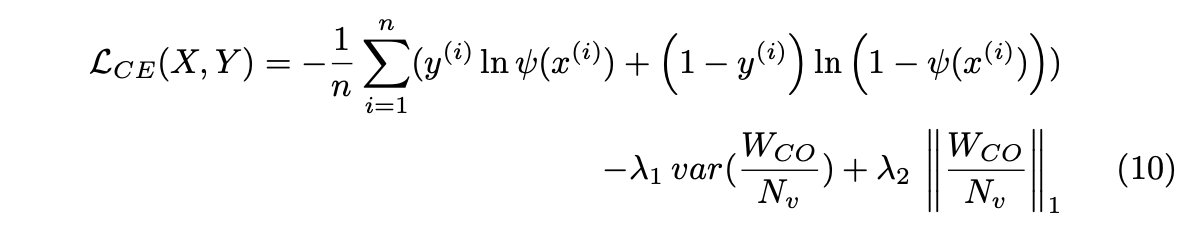
其中X={x(1),...,x(n)}是训练数据集中的输入示例集,Y={y(1),...,y(n)}是相应的标签集。ψ(x)表示给定输入x的神经网络的输出,λ1和λ2是用户指定的参数系数λ1∈ [0, 1], λ2 ∈ [0,1],Nv是数据集中的多个变量,WCO是CancelOut权重。
均方误差(MSE)损失可用于回归任务:
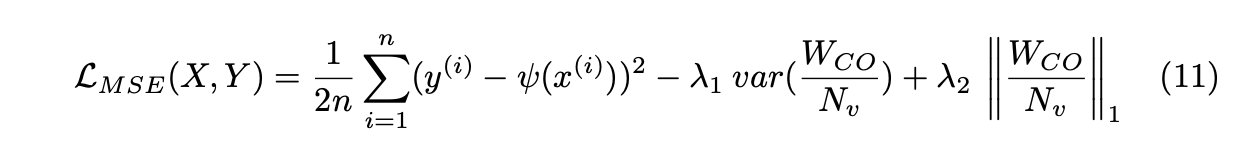
来自CancelOut层var(WCO/Nv)的权重方差有助于刺激CancelOut层中的多样性,其中l1范数用于在WCO权重中引入稀疏性,并将方差限制为小权重。此外,l1惩罚限制模型选择相关特征。最后,我们的特征选择方法支持所有损失,并且不需要实现条件(表1)。
4 Experimental Results
在本节中,我们将执行几个实验来评估CancelOut层的不同方面。在第一个实验中,我们使用Statlog(澳大利亚信贷批准)和糖尿病数据集[3](第4.1节)检查分类和回归任务算法的性能。我们选择这些数据集,因为它们包含不同的特征类型,如连续和象征性的。我们使用k-折叠交叉验证(分层用于分类实验)比较了CancelOut神经网络、随机森林和梯度增强算法提出的特征。
在第二个实验中,我们添加了一个虚拟变量(Y+ε1)∈ X与正态分布噪声ε一起添加到澳大利亚信贷批准数据集,以查看提出的方法是否能够检测到与目标特征高度相关的特征(第4.2节)。此外,我们还引入了一个“噪声”变量Xrandom ∼ N(0,1)+ε2来评估CancelOut是否丢弃了不相关的特征。注意,ε1 != ε2。
接下来,我们比较LASSO、SHAP[10]和CancelOut(第4.3节)中的特征重要性特征。在最后一个实验中,我们使用卷积自动编码器(第4.4节)评估了无监督场景下的模型。
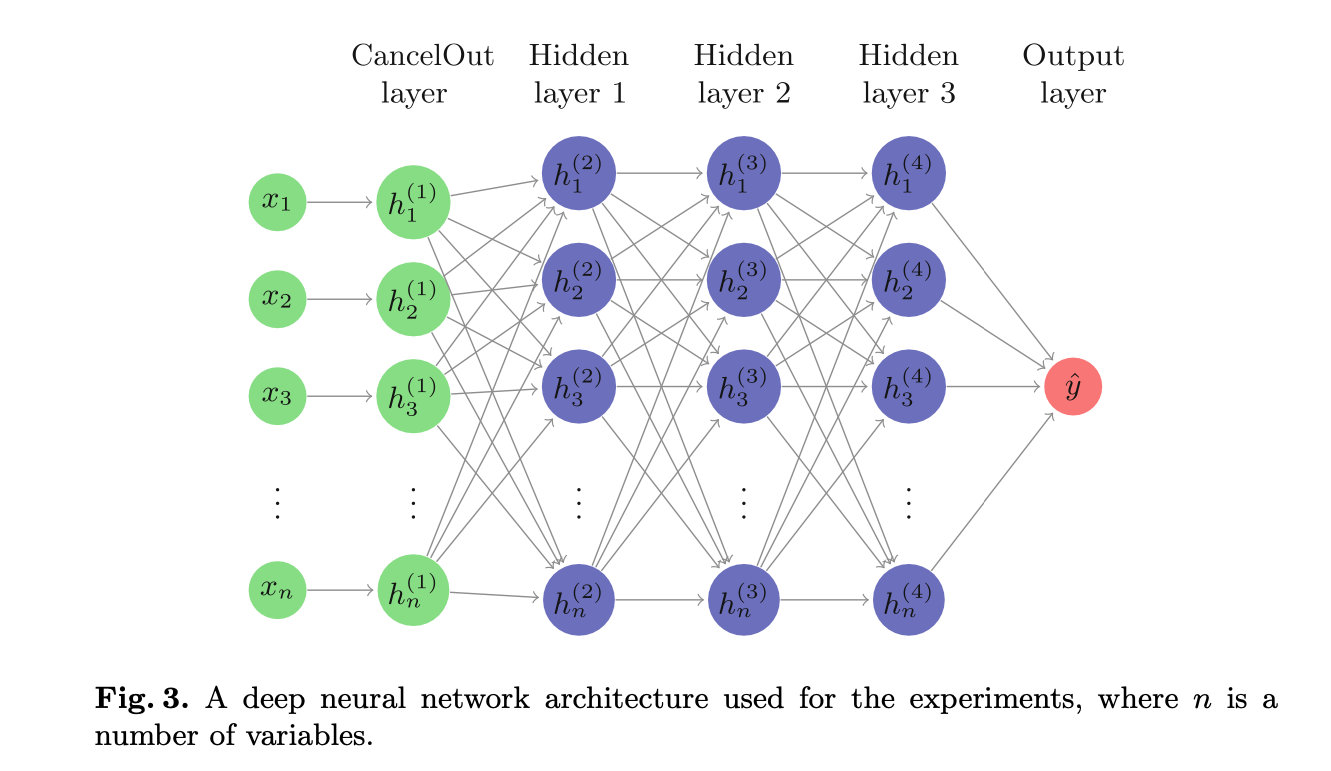
在所有实验中,我们使用五层DL模型(图3),其中输入层是在每个FC层应用ReLU激活函数[5]后使用sigmoid激活函数的CancelOut层。此外,我们使用优化算法Adam[7],学习率为0.003,β1=0.9,β2=0.999,ε=10−9 . 我们利用early stopping技术来控制模型的过度拟合。
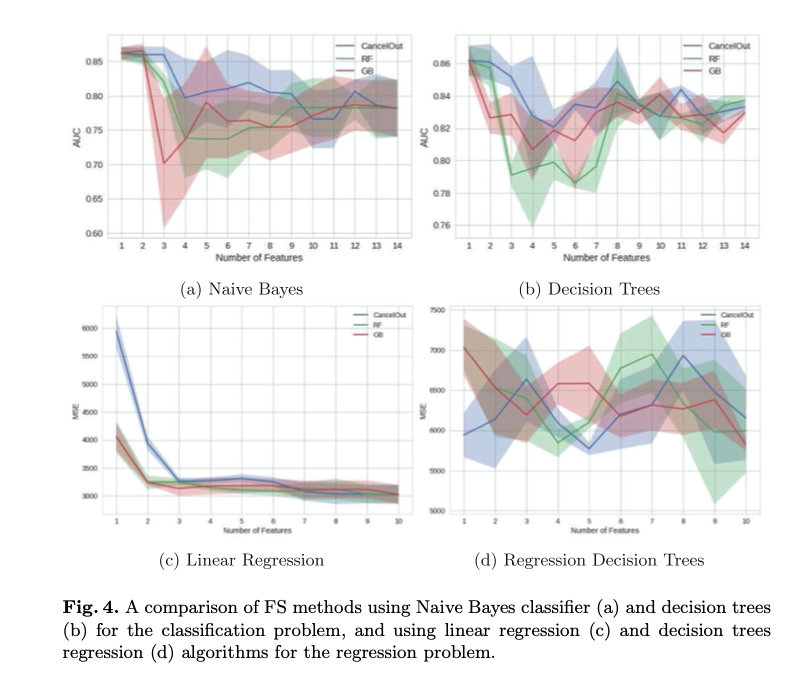
4.1 Feature Ranking
分类示例。我们在图4中说明了不同大小的特征子集[3]的AUC分数。结果通过使用朴素贝叶斯(图4a)和决策树(图4b)对澳大利亚信贷批准数据集进行五重分层交叉验证获得。我们的算法实现了对分类器和所有特征集大小的一致良好预测。此外,CancelOut对小特征子集的预测效果更好。所有算法的AUC可变性相似。
回归例子。为了在回归问题的背景下评估CancelOut,我们在糖尿病数据集上应用线性回归(图4c)和决策树回归(图4d)。我们在图4中说明了不同大小的缩减特征集的MSE。我们通过五次交叉验证再次获得MSE分数。如果特征数小于3,则CancelOut对于线性回归有缺点。然而,我们的算法在缩小的特征集大小的中间和末端范围内获得了有竞争力的结果。具有决策树的回归任务的误差度量随着所选特征的数量而高度波动。然而,我们的算法在较小的缩减特征集上获得了最佳结果。这些观察结果表明,CancelOut通常可以获得在回归任务中表现良好的特征集。
4.2 Identifying Target and Noisy Features
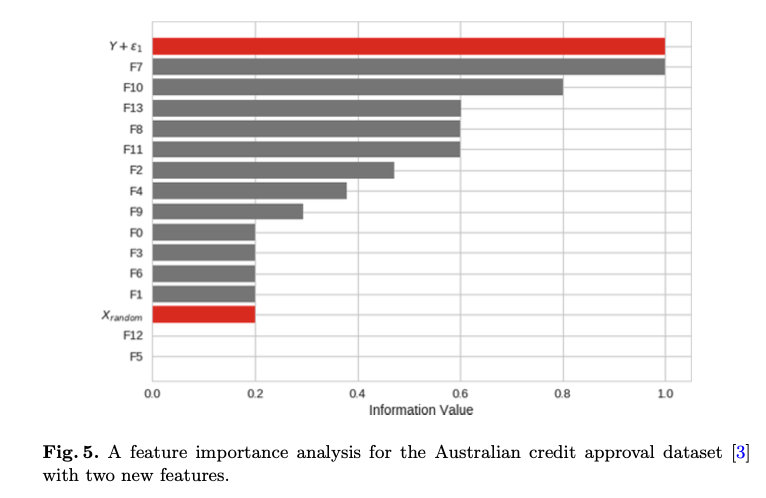
在本实验中,我们在澳大利亚信贷批准数据集中引入了两个新特性[3]。第一个变量Y+ε1与目标特征高度相关,第二个变量是由正态分布Xrandom ∼ N(0,1)+ε2生成的随机噪声特征。实验的目的是证明所提出的FR方法能够检测数据集中的关键特征和噪声特征。
在图5中,我们对增强的澳大利亚信贷批准数据集进行了特征重要性分析。描述的值是使用CancelOut层获得的十次ANN运行的平均值。分析表明,我们的方法可以成功地检测到与目标高度相关的变量,将它们作为最重要的变量进行评估。此外,CancelOut通过赋予噪声特征较低的权重来减轻噪声特征的影响。Xrandom的低秩示例性地显示了这一点。
4.3 Evaluating Individual Feature Importance
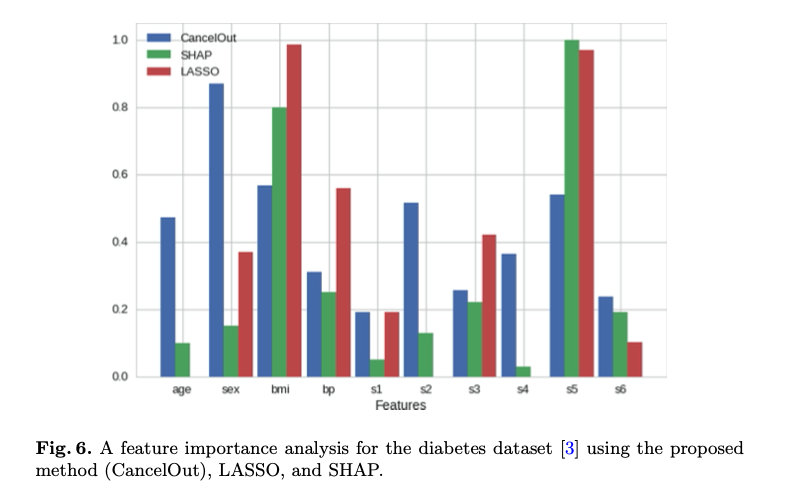
我们研究了糖尿病数据集的几种特征分析方法,并将其总结为图6。此比较的目的是显示CancelOut的表现与其他算法相当。虽然单一特征的年龄、性别、s2和s3在特征重要性上存在差异,但CancelOut权重的总体分布与SHAP和LASSO模型的分布相当。
4.4 Unsupervised Feature Ranking Using Autoencoder
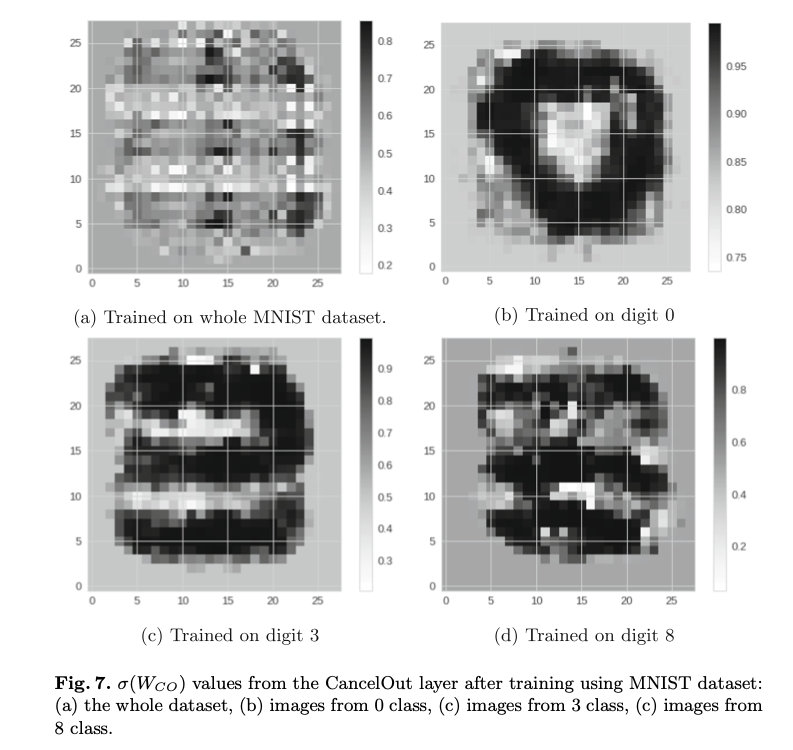
在本小节中,我们将演示如何利用CancelOut层进行卷积自动编码器的无监督学习任务[11]。自动编码器的结构包括编码器和解码器部分的三个卷积神经网络(CNN)层,以及编码器的输入层CancelOut。本实验使用MNIST数据集[8]。
图7显示了在整个数据集(a)、仅在数字0(b)、仅在数字3(c)和仅在数字8(c)上训练卷积自动编码器后的CancelOut权重。CancelOut为所有四个训练集捕获图片中最相关的区域。CancelOut层权重提供的信息有助于模型理解、调试和调整,例如,如果模型性能不佳,则通过引入“关注”相关特征。
5 Conclusion
在本文中,我们介绍了一种新的特征排序方法,使用深度神经网络的各种机器学习问题。所提出的方法非常容易实现,可以使用所有现代DL框架来实现,并且这种方法可以简单地扩展。由于神经网络的强大功能,该方法学习线性和非线性数据依赖关系。此外,CancelOut层可以应用于任何数据类型和机器学习任务,例如分类和回归问题,甚至可以作为自动编码器的输入层应用于无监督问题。最后,建议的层有助于理解数据及其对DL模型性能的影响。