
Challenge
-
目标域上的数据严重不足
-
Detection的任务不仅要定位还要分类,增加任务难度
-
数据量少容易造成over-adaptation
同时,现在存在的Domain-Adaptation Detection中,更多的是做无监督的方式,这样在源域同样需要大量的数据。
所以本文的研究目的是:在源域上训练的检测器,通过few-shot learning的思想转移到在带有部分label的目标域上。(部分label表示一张图不完整标出所有bbx)。
Solution
-
基于第一个挑战
作者提出Pairing Mechanism的方法,缓解目标域中样本数量不足的问题。
-
基于后两个挑战
作者提出bi-level module的模块,分别是Image-Level和Instance-Level两种方式同时应用到Faster R-CNN。可以实现将源域训练的detector转移到目标域。
基于以上两个创新点,构成了文章提出的模型,Few-shot Adaptative Faster R-CNN。

Related Work
相关的的工作主要有:目标检测,Domain-Adaptation Detection, few-shot learning
但是很少有工作深入研究Domain-Adaptation Detection或者说Few-shot learning的Detection。
(可能的原因就是上述的挑战部分)
Details
Pairing Mechanism
- Image Level (解决global domain shift的问题)
- Instance Level(解决语义上的冲突
然后将这些模块组建的网络采用Domain Adversarial Learning Method进行训练。
提一个问题:为啥采用Domain Adversarial Learning Method的方式来训练?
我觉得作者是认为从source domain到target domain的迁移过程类似将一个source distribution 变换为 target distribution的过程,而对抗生成判别的过程刚好是这样一个迁移的函数,所以作者采用domain adversarial learning的训练。

Image-Level Adaptation
Image-Level Adaptation的包含两个过程:
- Split Pooling
- Pairing Sampling
Split Pooling
这一段没理解到位,先占个坑。 ction 4.2)
tasks. Code will be releas
Pairing Sampling
Pairing Sampling的工作是将Split Pooling的features划分为两个Groups,因为有三个scales, 所以有6个Groups。
第一个Group中只包含source domain的特征 , 第二个Group中包含source domain和target domain各一个 。
这种配对策略能有效的对target domain的特征样本进行数据增强。
Instance-Level Adaptation
intance-Level Adaptation的工作是语义上对齐配对的特征。
主要的方法是将Faster R-CNN ROI采样拓展为Instance ROI 采样。
损失函数的公式也是采用对抗训练:
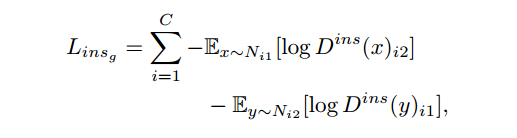
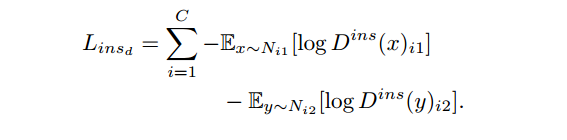
Source Model Feature Regularization
考虑到对抗训练的不稳定性,加入一个强有力的正则化模块,来有效避免over-adaptation。
Experiments
作者还没开源代码,所以这里也先占个坑。
作者采用了5个baseline模型进行对比试验:
-
Source training model
-
ADDA
-
Domain transfer and Fine tuning(DF+FT)
-
Domain Adaptative Faster R-CNN
-
Few-shot Adaptative Faster R-CNN
采取了4个数据集,5个训练场景:
- Scenario-1: SIM10K to Udacity (S- > U)
- Scenario-2: SiM10K to Cityscapes(S -> C)
- Scenario-3: Cityscapes to Udacity (C -> U)
- Scenario-4: Udacity to Cityscapes(U -> C)
- Scenario-5: Cityscapes to Foggy Cityscapes(C -> F)
