Faster R-CNN
R-CNN, Fast R-CNN 和 Faster R-CNN 是目标检测的三部曲,作者不断地创新和吸纳新的思想和算法,从而R-CNN系列算法的运行速度越来越快,同时检测精度也不断提高。R-CNN 是目标检测历史上的一个里程碑,它提出来的思想——提取 region proposals, 然后对每个region proposal用卷积网络进行识别,最后用回归算法对目标边界进行微调——成为许多目标检测算法的基本思想。Fast R-CNN 通过共享卷积网络的接收域(对整个图片进行卷积)提高了卷积识别过程的计算速度。现在R-CNN的主要瓶颈是 region proposal method 的计算速度。
Region proposal method
R-CNN 和 Fast R-CNN 使用到的 region proposal method 有 Selective Search(SS), 但是SS实在是太慢了,在CPU中处理一张图片需要2s。EdgeBoxes 是另外一种 region proposal method 方法,它权衡了 proposal 的质量和运算速度,速度达到0.2s/image。但是 region proposal 这一步在目标检测网络中占用了大部分时间。
作者觉得 region proposal method 在CPU上运行太慢了,于是想把它运行到GPU上,同时,如果 region proposal method 能嵌入到检测网络中,那么运算速度可以更快,于是作者提出了 Region Proposal Networks(RPNs)。
RPN
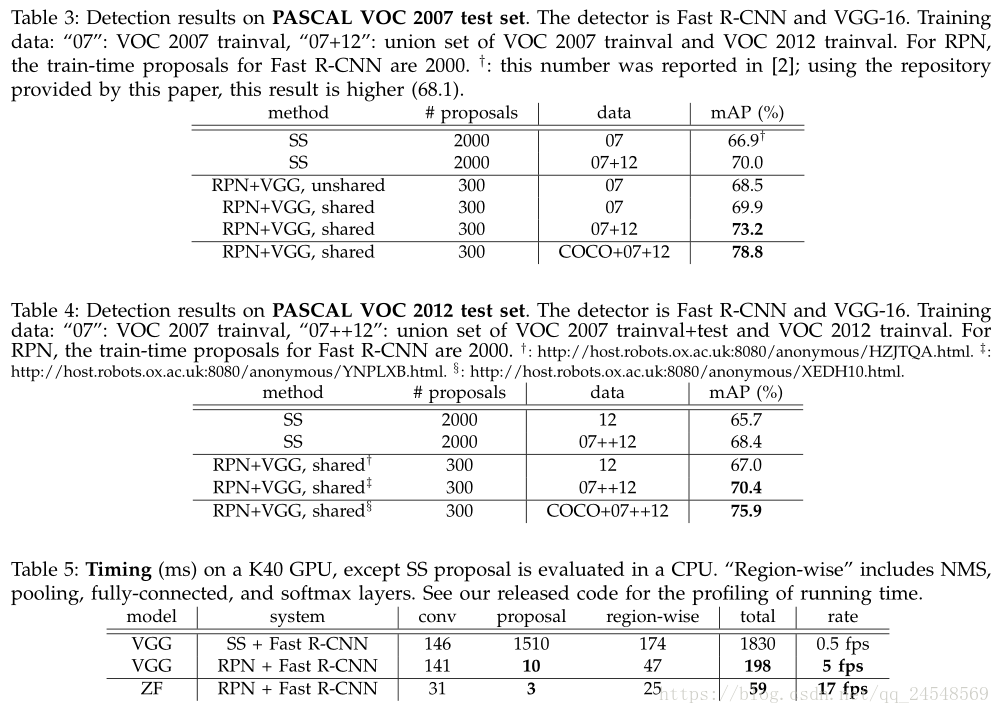
Faster R-CNN 包括两个模块,第一个模块就是RPN,用于生成 region proposals,第二个模块就是 Fast R-CNN 的识别器。RPN在Faster R-CNN的位置如下图所示。
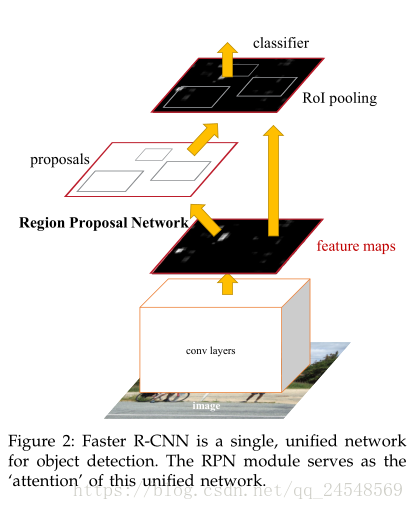
作者尝试用 Zeiler and Fergus model (ZF) 和 Simonyan and Zisserman model (VGG-16) 两种网络的卷积层作为 Faster R-CNN 的共享卷积层。ZF有5个可以共享的卷积层,VGG-16有13个可以共享的卷积层。RPN 就建立在最后一个共享卷积层之上。在最后一个共享卷积层输出的 feature map,使用一个
滑动窗体遍历一遍(作者取n)。每个滑动窗体映射成一个低纬度的特征,在ZF网络映射成256-d,在VGG中映射成521-d。接着这个特征分别传递到两个全连接层,一个是 box-regression layer (reg),用于预测 anchors 的 bounding-box 的位置,另一个是 box-classification layer (cls),用于对 anchor 是否是一个识别对象进行打分。RPN的网络图如下

Anchor
Anchor可以帮助网络生成不同大小尺度的 region proposals,识别同一区域的不同形状的对象,比如

即使人和马的位置几乎重合在一起,Faster R-CNN依然可以检测出人和马的 bounding-box。一个anchor锚定位于所讨论的滑动窗口的中心,并且与一种形状(anchor box)相关联。如RPN网络图所示,一个滑动窗体有k个anchor(论文中k取9),每个anchor对应一种bounding-box的形状。cls层预测每个anchor box中存在对象的概率,cls有2k个输出,分别是“是对象”和“不是对象”的概率值。reg层预测每个anchor box的4个坐标值,有4k个输出。从上一个例子看,人的bounding-box和RPN图的第二个anchor box吻合,因此第二个anchor box就提取出人的 region proposal,马的bounding-box和RPN图的第四个anchor box吻合,因此第二个anchor box提取出马的region proposal。其他anchor box没有匹配的对象,因此其他的anchor boxes在cls的输出值表示没有检测到对象。
Loss Function
RPN网络的损失函数是:
其中,i表示在mini-batch中anchor的序号, 表示 anchor i 是对象的概率,ground-truth 标签 为1当且仅当anchor i有对象,否则为0。 是代表4个关于预测bounding-box的参数坐标的向量, 则是ground-truth box的参数坐标向量。
是分类的交叉熵损失函数。
,其中R是鲁棒性的损失函数——smooth
,在Fast R-CNN中定义。
表示只有当 anchor box i中有对象时才计算回归损失。 用来权衡分类损失和预测损失。 和 用于标准化(normalize)两个损失项。
关于bounding box 的4个参数坐标,作者是通过下列式子求出来的:
其中 是bounding box的中心坐标, 表示bounding box的宽高。 分别代表预测的box,anchor box和ground-truth box。作者是通过bounding box 与 anchor box的相对位置求出区域的位置。
Faster R-CNN Architecture
Faster R-CNN的整体结构如下图
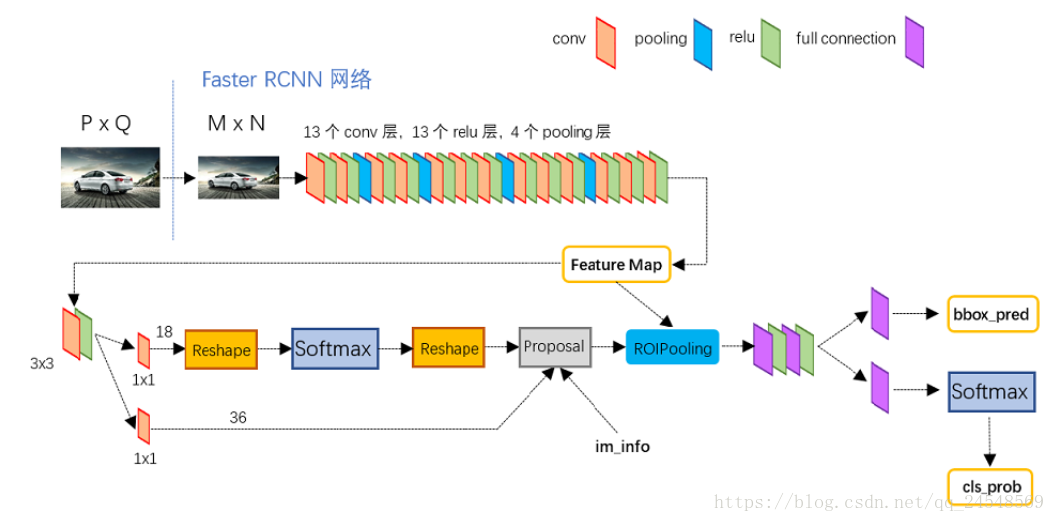
上半部分是VGG-16的卷积层,然后接着RPN。RoI pooling 层接收VGG-16提取到的图片特征和RPN提取的 region proposals,把每个region pooling 成固定大小的feature map。网络最后分为一个分类网络和回归网络,分别用来识别对象和修正区域的bounding-box,提高对象位置的预测精度。(RoI pooling之后的网络是 Fast R-CNN 的内容)
训练 Faster R-CNN
因为RPN和Fast R-CNN是共用底层的卷积层,所以训练时不能分开训练两个网络,而是要使用共享的特征来训练。作者提出了三种训练方法。
1. Alternating training. 首先训练RPN,然后使用RPN得到的 region proposals 来训练 Fast R-CNN。Fast R-CNN 调优后的网络用来初始化RPN。如此不断迭代。作者在论文的实验都是使用这种方法。
2. Approximate joint training. 把RPN和Fast R-CNN合成一个网络,在训练Fast R-CNN dectector时,前向传播生成 region proposals,这些 region proposals当成是固定的,预先计算出来的。在反向传播中,共享的卷积层同时受RPN和Fast R-CNN的影响。但是这种解决方法忽视了 proposal boxes坐标的导数的影响,因此这种方法近似联合训练。
3. Non-approximate joint training. 在反向传播中同时考虑梯度和box的坐标。
作者使用第一种方法训练 Faster R-CNN,共4步。第一步,训练RPN。第二步,使用训练得到的RPN生成的 region proposals训练Faster R-CNN。第三步,使用Faster R-CNN的网络初始化RPN训练,固定共享卷积层,只对RPN特有的层进行 fine-tune。第四步,继续固定共享卷积层,只对Fast R-CNN特有的层进行 fine-tune。
Faster R-CNN 效果
这里简单的放上论文中的实验结果。