前提准备
1:准备多台虚拟机(我准备了四台) ,分别为:node1,node2,node3,node4
2.配置好java环境变量和Hadoop的环境变量以及Hadoop的二次JAVA_HOME的配置在虚拟机上实现搭建1.x版本的Hadoop伪分布式中 有介绍环境的配置
3.配置好网络,保证虚拟机之间能够ping通
虚拟机中linux系统网络的配置文章中介绍了配置虚拟机网络的步骤,在/ect下的hosts中,加上对应的ip名和别名即可,即:ip:name
4.HA中各个部分的分工如下
node1虚拟机作为NameNode,node2作为NameNode,DataNode有node2,node3,node4担任。zookeeper集群用node2,node3,node4三台虚拟机担任,JournalNode由node1,node2,node3担任。
开始操作
第一步,免秘钥配置
在node1虚拟机(根据需要选择虚拟机作为NameNode节点)的root/.ssh文件下生产免秘钥文件。
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
使用ssh node1测试,如果不需要验证就能登录node1则配置成功,接下来将生成的id_dsa.pub文件分发到其他虚拟机上,使用如下命令:
进入到.ssh文件夹下
scp id_dsa.pub node2:`pwd`/node1.pub #为了能够使node1虚拟机免密钥登录,需要将node1中的id_dsa.pub文件改名为node1.pub(名字随意起)
...进行上述操作将免密钥文件分发给其他三个虚拟机
然后在其他虚拟中使用如下命令,则可配置完成
cat ~/.ss.pub >> ~/.ssh/authorized_keys
第二步,将两个NomeNode节点的虚拟机之间免密钥
1:现在node2虚拟中生成免密钥文件,然后分发给node1,然后写入到authorized_keys文件中
,具体命令是第一步的命令,改动少许即可。
第三步,配置Hadoop
1:配置hadoop-2.6.5/etc/hadoop下的 hdfs-site.xml文件,在
中加入如下配置
<property>
<name>dfs.replication</name>
<value>2</value> #副本数
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value> # mycluster 可以自己命名,但下面的凡是用到mycluster的地方都要和自己起的名字 一致
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value> #声明NodeNode节点的别名
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value> #表明NameNode节点
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>#表明NameNode节点
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value> #配置journalNode节点,声明了文件写到哪里
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/sxt/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value> #是否自动切换
</property>
2:配置hadoop-2.6.5/etc/hadoop下的 core-site.xml 文件,在
中加入如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> #mycluster和 hdfs-site.xml文件中声明的名字一样
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hist/hadoop/ha</value> #上传的数据到哪里
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value> #指明zookeeper集群都有那些虚拟机
</property>
3:配置slavers文件,将其中内容改为如下内容,用来指定谁是datanode节点,这里使用的是虚拟机的IP的别名
node2
node3
node4
将配置好的文件分发到其他虚拟机上
scp core-site.xml hdfs-site.xml node2:`pwd` #通过命令分别分发给node2,node3,node4
第四步,配置zookeeper集群
1:解压zookeeper-3.4.6.tar.gz(版本根据自己的需要选择)
2:进入到文件夹中下的/conf文件夹下:将zoo_sample.cfg文件重命名为zoo.cfg
命令如下:
mv zoo_sample.cfg zoo.cfg
3.进行配置,编辑zoo.cfg
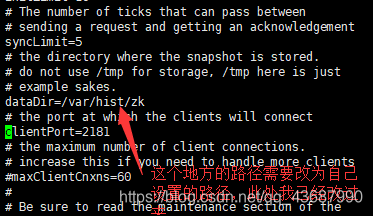
在末尾加上:
server.1=node2:2888:3888 #server.数字 ,该数字作为id用来进行选择谁是主谁是备用,可以根据需要选择,node2是准备作为zookeeper的虚拟机别名,也可以改为ip
server.2=node3:2888:3888
server.3=node4:2888:3888
4.在zookeeper集群中创建上面dataDir对应的文件目录路径
mkdir -p /var/hist/zk
5.向zookeeper集群中的虚拟机中写如id,id对应着上面配置的server1等
如在node2中,使用下面命令写如id:
echo 1 > /var/hist/zk/myid
,在node3,node4中分别写如对应配置中的id,如node3在配置文件中写的是2,则写2
6.配置zookeeper的环境变量,在/etc/profile文件中添加zookeeper的环境变量
#所有路径都写自己对应的路径
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
export HADOOP_HOME=/root/hadoop-2.6.5
export ZOOKEEPER=/root/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER/bin
7.测试环境变量的配置
任意目录下,zkCli.sh能自动补全则可以使用
8.启动zookeeper 和测试zookeeper
使用zkServer.sh start启动
使用zkServer.sh status查看状态
如果出现
和 说明配置成功
说明配置成功
9.使用zkServer.sh 停止
第五步,启动高可用前的最后配置
1:共享启动zkServer.sh start 集群
2:1,2,3节点启动journalnode 集群:hadoop-daemon.sh start journalnode
3:随意找一个namenode节点格式化:hdfs namenode -format
4: 启动格式化的namenode节点: hadoop-daemon.sh start namenode
5:另一nn节点同步:hdfs namenode -bootstrapStandby
6:格式化zkfc,在zookeeper中可见目录创建: hdfs zkfc -formatZK
7:启动hadoop集群:start-dfs.sh
上述是第一次启动时需要的步骤因为需要配置一些信息,如果再次启动,则需要按照下面的顺序:
1.启动zookeeper集群
2.启动hadoop集群,journalnode在这一步中可以被启动,不用单独启动
以上配置完成,如果有错误,欢迎指正