实验配置五台虚拟机server1-5都是rhel6.5版本 所有虚拟机建立hadoop用户 uid gid一致 密码相同 以server1为例

获取安装包hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz解压安装 注意是在hadoop用户下
下载解压相关软件
修改环境变量,使hadoop运行在java平台之上![]()


修改java变量![]()

![]()
单节点部署
创建文件夹 将数据导入文件夹中
wordcount 统计单词算法
查看统计结果
伪节点部署
配置文件系统![]()

配置文件保存的份数![]()

设置ssh免密码认证

[hadoop@server1 hadoop]$ scp -r /home/hadoop/.ssh/ hadoop@server2:~
[hadoop@server1 hadoop]$ scp -r /home/hadoop/.ssh/ hadoop@server3:~
[hadoop@server1 hadoop]$ scp -r /home/hadoop/.ssh/ hadoop@server4:~
[hadoop@server1 hadoop]$ scp -r /home/hadoop/.ssh/ hadoop@server5:~
配置datanode节点
返回值为0表示格式化成功
启动服务 查看进程状态
##网页测试 浏览器访问 http://172.25.62.1:50070/

创建目录上传
点击最右边的 点击第一个查看目录

上传文件至服务端
再次查看
使用命令查看结果
删除并查看其显示结果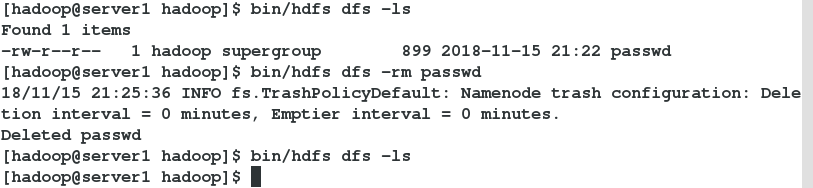





高级配置mapred配置



启动服务 并查看
查看是否成功 浏览器访问http://172.25.62.1:8088/cluster/cluster
分布式配置 先停止伪节点
停止伪节点
切换到超级用户![]()

配置共享存储 刷新查看是否成功
客户端server2安装服务 并设置开机自动挂载 注意启动顺序![]()

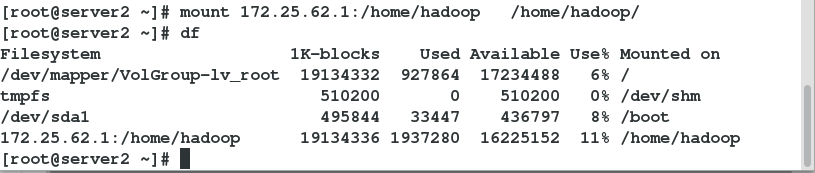
server3与server2一样 注意服务启动顺序
[root@server3 ~]# yum install -y nfs-utils rpcbind
[root@server3 ~]# /etc/init.d/rpcbind start
[root@server3 ~]# /etc/init.d/nfs start
[root@server3 ~]# chkconfig rpcbind on
[root@server3 ~]# mount 172.25.62.1:/home/hadoop/ /home/hadoop/
[root@server3 ~]# df -h查看是否成功
配置datanode节点
配置备份存储2份![]()

格式化namenode节点
返回值为0表示正常
启动服务并查看
datanode节点查看服务

查看节点是否存在并正常挂载

![]()
在线添加节点server4
[root@server4 ~]# yum install -y nfs-utils rpcbind
[root@server4 ~]# /etc/init.d/rpcbind start
[root@server4 ~]# /etc/init.d/nfs start
[root@server4 ~]# chkconfig rpcbind on
[root@server4 ~]# mount 172.25.62.1:/home/hadoop/ /home/hadoop/
[root@server4 ~]# df -h免密启动服务 并查看进程

查看其是否加入存储体系中![]()

节点数据迁移
查看是否上传成功
查看节点的存储状态![]()

配置下线![]()

配置下线用户为server3
使配置生效
查看server3的状态如果是Decommissioned则表示迁移完成 否则表示未完成![]()

同时可以发现其他节点存储增加了 
关闭datanode节点
开启其他节点的nodemanager服务
HDFS高可用 原理待补充
先关闭之前的服务
配置服务![]()

删除原有配置![]()
server1到server4都清空配置以免影响

安装服务zookeeper 总节点数为奇数个
server1到server5都获取安装包
指定对应的ID![]()


server3和server4上如下操作

server2.3.4上启动服务


查看哪个是leader


看到server3是leader 在leader上启动服务并查看相关配置
输入quit退出
配置集群
配置指定hdfs的namenode 为master(名称随意)指定zookeeper 集群主机地址(server2,server3,server4的IP地址)![]()

编辑hdfs-site.xml文件![]()
A 指定hdfs的nameservices为master
B 定义namenode节点(server1,server5)
C 指定namenode元数据在journalNode上存放的位置
D 指定journalnode在本地磁盘存放数据的位置
E 开启namenode 失败自动切换,及自动切换实现方式,隔离机制方式以及使用sshfence 隔离机制需要ssh免密以及隔离机制超时时间等参数
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.62.1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.62.1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.62.5:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.62.5:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.62.2:8485;172.25.62.3:8485;172.25.62.4:8485/masters</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
配置server5进行挂载![]()

启动日志服务器server2 server3 server4


格式化HDFS集群

将生成的数据发送到另一个高可用节点server5
免密在之前已经做过 没做过的话执行下面的命令
启动zkfc服务 格式化zookeeper
启动hdfs集群
查看server1和server5 server2.3.4的状态
server1状态和server5一致 234状态一致


在浏览器查看 server1为master server5为standby
http://172.25.62.1:50070/dfshealth.html#tab-overview
http://172.25.62.5:50070/dfshealth.html#tab-overview
模拟故障切换
在浏览器查看namenode为server5 server1不可连接
http://172.25.62.5:50070/dfshealth.html#tab-overview
再次启动server1的namenode master依然是server5
浏览器再次查看
yarn高可用![]()

![]()
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
##指定yarn的框架为mapreduce
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
##配置可以在nodemanager上运行mapreduce程序
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
##激活RM高可用
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
##指定RM的集群ID
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
##定义RM节点
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.62.1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.62.5</value>
</property>
##激活RM自动恢复
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
##配置RM状态信息存储方式 有memstore和ZKstore
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
##配置zookeeper存储时,指定zookerper集群的地址
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.62.2:2181,172.25.62.3:2181,172.25.62.4:2181</value>
</property>
</configuration>启动服务
另一个节点server5需要手动启动
在浏览器访问
http://server1:8088/cluster/cluster
http://server5:8088/cluster/cluster
yarn故障测试
在server1上断开主节点
查看状态 server5接管资源
再次启动server1
再次访问 还是server5在处理
服务的关闭
server1上
server5节点上
server2.3.4关闭的方法一样