**
Hadoop高可用集群搭建(遇到的错误)及测试
**
本文主要介绍的是hadoop的高可用集群搭建步骤,个人觉得还挺详细得哈哈哈哈哈哈还附有截图,希望可以给有需要的童鞋一点帮助。然后文章的最后也列举了本人在安装过程中所遇到的困难以及解决办法,希望可以给正在为错误焦头烂额的你一点点渺茫的希望哈哈哈哈哈~
**
一、前期准备
**
1、 首先安装VMware 虚拟机,先配置好一台虚拟机的公共配置,然后其余的克隆出来即可(我用的是4台克隆的虚拟机),Linux环境要搭好,每台虚拟机的IP地址要和对应的虚拟机对应。 !!!!最重要的是每台虚拟机的防火墙一定都要关了!!!!(如果不关闭防火墙后面搭建集群的过程中真的会有很多错误!)
关闭防火墙: service iptables stop
查看防火墙状态: service iptables status(下图为关闭防火墙时图片)

2、如果觉得在VMware中跑四台机子,可能会很麻烦,要来回切换在Windows系统与Linux之间。这个时候就可以下载一个软件:Xshell 5 链接:https://pan.baidu.com/s/14iO-wsRXt8AxOpmuj4qR2A
提取码:npqj

这个软件真的很方便,不仅仅不用在Windows和Linux中来回切换,还可以直接把Windows中的文件传输到Linux中:

这个时候还要下载一个软件:Xftp 4
链接:https://pan.baidu.com/s/14XSkeJ9fU30_otAAlbMfGw
提取码:mo3e

3、你还要确保你的四台虚拟机之间可以ping的通,因为后面要互相之间传输文件!!!(下图举例为node02上ping node01正确的情况)
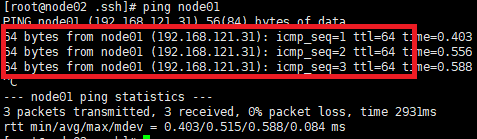
**
二、搭建过程(具体步骤)
**

1、我是在4台虚拟机上跑Hadoop集群,主机名以及IP分别为:
node01 192.168..31
node02 192.168..32
node03 192.168..33
node04 192.168..34
2、安装jdk(在node01上安装,已经在第一台机子上安装过的就不用了),我安装的版本是:jdk-7u67-linux-x64
链接:https://pan.baidu.com/s/1WU28omtvsHH_LCHk1HxuPg
提取码:zqlr
下载到桌面上后,用Xftp 4传输到Linux中,接着安装:
**①rpm安装命令:rpm -i jdk-7u67-linux-x64.rpm
**②查看java路径:whereis java
③****添加环境变量:vi + /etc/profile
在文件最后加上(我的):
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin
④加载一下刚才更改过的profile文件:source /etc/profile(只要更改profile中的内容就要重新加载一下,不然是没有用的!)
如果出现 -bash: jps: command not found
改:
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin
此时已经安装好jdk,这个时候你就可以键入:jps(如图则安装成功!)
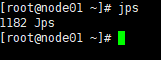
⑤****分发jdk到node02、03、04:
scp jdk-7u67-linux-x64.rpm node02:`pwd`
scp jdk-7u67-linux-x64.rpm node03:`pwd`
scp jdk-7u67-linux-x64.rpm node04:`pwd`
⑥****分别在node02、03、04上执行rpm安装命令:
rpm -i jdk-7u67-linux-x64.rpm
并在Xshell的全部会话栏里一起ll,看jdk是否发送成功。
⑦****在node01上cd /etc,在此目录下把profile文件分发到node02、03、04上,键入命令:
scp profile node02:`pwd`
scp profile node03:`pwd`
scp profile node04:`pwd`

⑧利用Xshell全部会话栏:source /etc/profile
利用Xshell全部会话栏,jps,看02、03、04这三台机子的jdk是否装好。

jdk安装好的 话,会出现下图:
⑨****同步所有服务器的时间:
在全部会话栏里键入:date (查看机子当前的时间)
比较四台机子的时间,如果出入很大的话,就要安装时间同步器。因为时间不能差太大,否则集群启动后某些进程跑不起来。
yum进行时间同步器的安装:yum -y install ntp
执行同步命令:ntpdate time1.aliyun.com (和阿里云服务器时间同步)
3、装机之前的配置文件检查:
①****查看主机名是否和当前虚拟机一致,以及网络状态:cat /etc/sysconfig/network

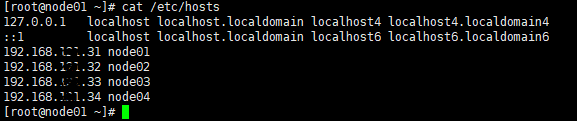
②****查看IP映射是否正确:cat /etc/hosts
(查看主机名是否和IP相对应)
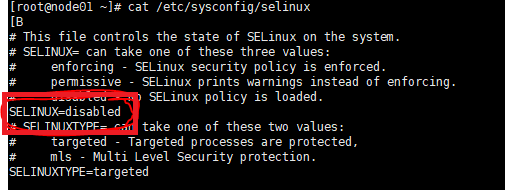
③****关闭SELINUX服务:cat /etc/sysconfig/selinux
看是否SELINUX=disabled,若不是则修改。
④****查看防火墙是否关闭:service iptables status
(下图显示已关闭,若没有关闭则使用关闭防火墙命令:service iptables stop)

4、免秘钥设置(此举的目的就是为了以后node01可以不用密码就可以给其他三台虚拟机发送文件等)
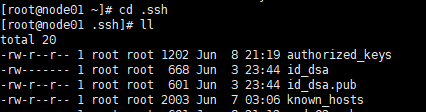
①在家目录下 :ll –a
看下有无.ssh文件,如果没有就使用命令:ssh localhost(生成秘钥)(ssh localhost后要exit)。

如果有的话就打开.ssh文件:cd .ssh
并且ll一下
②****把node01的公钥发给其他三台机子:
scp id_dsa.pub node02:`pwd`/node01.pub
scp id_dsa.pub node03:`pwd`/node01.pub
scp id_dsa.pub node04:`pwd`/node01.pub
此时一定要在.ssh文件下键入此命令,不然报错显示找不到此文件

③然后分别在node02、node03、node04上打开.ssh文件,看是否有node01.pub
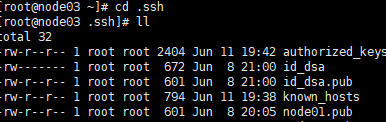
④如果有node01.pub,那就分别在node02、node03、node04上把node01.pub追加到authorized_keys,键入命令:cat node01.pub >> authorized_keys
(此命令分别在node02、node03、node04上键入!还有就是要在.ssh的目录下执行此命令,不然会报错显示找不到此文件)

⑤当④完成后,就在node01上分别键入命令:ssh node02、ssh node03,ssh node04
看是否能免密钥登录(每次ssh都不要忘了exit!!!)

⑥此时node01是可以免秘钥登录node02、node03、node04的,但是还需要node02是可以免秘钥登录node01,这时需要操作:
在node02上:
首先键入命令:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa(以dsa的方式生成秘钥,并把秘钥放在家目录下的.ssh中)
然后键入命令:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys(把id_dsa.pub 追加到authorized_keys中,这样下次登录就不用了密码了,即免秘钥登录)
接着键入命令:ssh localhost(验证一下是否可以不用密码直接登录!记得exit!!)

然后在node02上把id_dsa.pub分发到node01上,并把node02的公钥(id_dsa.pub)重命名为node02.pub,以免和node01的公钥有冲突,键入命令:
scp id_dsa.pub node01:pwd/node02.pub

接着在node01的.ssh目录下键入命令:cat node02.pub >> authorized_keys

最后在node02上键入命令:ssh node01 验证一下可否免密钥登录(记得exit!!!)
此时,node01和node02是可以相互免秘钥登录的。
5、修改node03中一些配置信息
①首先回到家目录下,键入命令:cd /opt/zqq/hadoop-2.6.5/etc/hadoop
然后键入:ll

②此时需要修改hdfs-site.xml中的配置,键入命令:vi hdfs-site.xml
首先去掉snn的配置
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
增加以下property
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/zqq/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
③修改core-site.xml中的配置,键入命令:vi core-site.xml
configuration中全部修改为:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
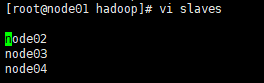
④****修改slaves中的配置:vi slaves
改为:node02
node03
node04
6、安装hadoop
①****首先键入命令:cd /opt

将其下的zqq目录分发到node02、03、04上:
scp –r zqq/ node02:`pwd`
scp –r zqq/ node03:`pwd`
scp –r zqq/ node04:`pwd`
例如:
此时node01发送文件给其他三台虚拟机是不用输入密码的,因为前面已经免秘钥了
②****回到家目录下,键入命令:cd /opt/zqq/hadoop-2.6.5/etc/hadoop
将hdfs-site.xml和core-site.xml分发到node02、03、04
scp hdfs-site.xml core-site.xml node02:`pwd`
scp hdfs-site.xml core-site.xml node03:`pwd`
scp hdfs-site.xml core-site.xml node04:`pwd`
例如:

7、安装zookeeper
此时,需要在node02、node03、node04上安装zookeeper。
我安装的版本是zookeeper-3.4.6
链接:https://pan.baidu.com/s/1HNmdVyfzVmMUlrxgMYDUcw
提取码:xze8
你可以下载到桌面上然后利用Xftp 4传输到Linux中的指定目录下。
在node02中存放zookeeper的目录下执行以下命令:
①****解压安装zookeeper
键入命令:tar xf zookeeper-3.4.6.tar.gz -C /opt/zqq

②****修改zookeeper的配置文件
首先打开conf,键入命令:cd /opt/zqq/zookeeper-3.4.6/conf
然后给zoo_sample.cfg改名为zoo.cfg并保存到conf中,键入命令:cp zoo_sample.cfg zoo.cfg
下图是已经改好过的:
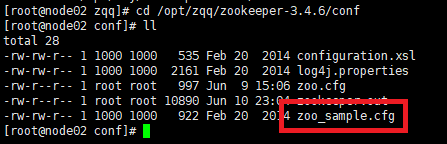
③****修改zoo.cfg,输入命令:vi zoo.cfg
修改数据路径:改dataDir=/var/zqq/zk
并在末尾追加
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
其中2888主从通信端口,3888是当主挂断后进行选举机制的端

④把zookeeper分发给node03、node04,此时要回到你存放zookeeper的目录下,分别输入命令:
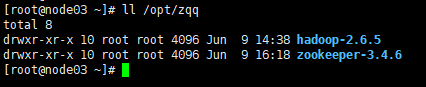
scp -r zookeeper-3.4.6/ node03:`pwd`
scp -r zookeeper-3.4.6/ node04:`pwd`


并用ll /opt/zqq分别在node03、node04上检查下看分发成功没。
例如:
⑤在步骤③种我们写了server.1是node02、server.2是node03、server.3是node04,此时我们就要标识到底谁是server.1、server.2、server.3,这是我们就要分别在node02、node03、node04中给每台机子配置其编号:
首先给每台机子(node02、node03、node04)创建刚刚配置文件里的路径,输入命令:mkdir -p /var/zqq/zk
对node02来说,执行:
echo 1 > /var/zqq/zk/myid
cat /var/zqq/zk/myid
对node03来说,执行:
echo 2 > /var/zqq/zk/myid
cat /var/zqq/zk/myid
对node04来说,执行:
echo 3 > /var/zqq/zk/myid
cat /var/zqq/zk/myid
⑥在node02中修改配置问题,输入命令:vi /etc/profile
配置结果如下图,把ZOOKEEPER_HOME改成了绝对路径(你可以在没进到profile文件前,先确定zookeeper的路径,并用pwd显示路径,然后复制到profile文件中,如果没有的话就增加这一行),并且也要在PATH后追加zookeeper的bin目录。

⑦****然后再把/etc/profile分发到其他node03、node04:
scp /etc/profile node03:/etc
scp /etc/profile node04:/etc
例如:

⑧在node02、03、04里执行:source /etc/profie 这步千万别忘,加载一下修改后的profile文件,否则修改是没有用的。
验证source这句是否完成,分别在node02、node03、node04上输入zkCli.s,按Tab可以把名字补全zkCli.sh,就安装成功!

8、启动zookeeper
全部会话:zkServer.sh start
全部会话后你会发现node01上显示:-bash: zkServer.sh: command not found 这是因为我们没有在node01上安装zookeeper,而是在另外三台机子上。
(如果启动不起来,请把用命令:vi + /etc/profile把profile中的JAVA_HOME改成绝对路径,即你jdk所存放的路径,查看路径同⑥步骤类似,修改后记得source /etc/profile ,加载一下)
接着同样全部会话,用命令:zkServer.sh status查看每个zookeeper节点的状态(就算node01上没有安装zookeeper,我们使用此命令也还是可以的,不会有什么关系的),如果正确启动zookeeper后,就会发现node02、node03、node04中有两个是follower,一个是leader,如下图:



此时你已经成功启动了zookeeper,说明你的安装以及配置很成功!
如果!不是如图所示,那就回头检查配置是否正确。
9、启动journalnode
(Why启动journalnode?为了使两台namenode间完成数据同步)
在node01、node02、node03三台机子上分别把journalnode启动起来,使用命令:hadoop-daemon.sh start journalnode
用jps检查下进程启起来了没(jps用来显示当前有哪些进程启动了)
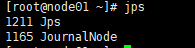
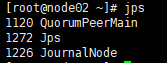
node02上jps一下发现多了一个1120 QuorumPeerMain,这是因为我们node02上启动了zookeeper。
node03结果同node02。
10、格式化任一namenode
在node01上,格式化namenode(因为我们的namenode是在node01和node02这两台虚拟机上面),执行命令:hdfs namenode –format 另一台namenode(即node02)不用执行,否则clusterID变了,找不到集群了。出现下图这种情况,就是格式化成功了。

11、启动namenode
启动刚刚格式化的那台namenode,即node01,执行命令:hadoop-daemon.sh start namenode
然后用命令:jps(如下图)

12、给另一namenode同步数据
那另一台namenode怎么办,什么都不做吗?
在node01上,我们要给另一台namenode(node01)同步一下数据,用以下命令:hdfs namenode -bootstrapStandby

13、格式化zkfc
格式化zkfc,使用命令:hdfs zkfc -formatZK
出现下图这种,就是格式化成功!

在node02上执行:zkCli.sh打开zookeeper客户端看hadoop-ha是否打开。
执行打开客户端命令时,可以不用再node02上执行,我们可以双击node02的标签,就会出来,一个新的node02界面,在这个新的界面执行,结果如下图。

14、启动hdfs集群
在node01上启动hdfs集群。执行命令:start-dfs.sh
注意:如果那个节点没起来到hadoop目录下去看那个node的日志文件log

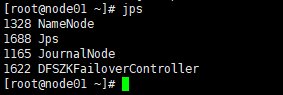
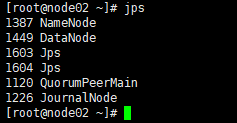
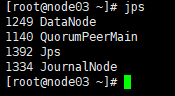
然后,在全部会话里执行命令:jps 看一下都起来些什么进程
node01上:
node02上:
node03上:
node04上:
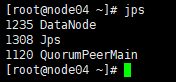
总之,node01和node02上是要有namenode的,反正对照一下,node02、node03、node04上是开启了zookeeper,所以进程要多一点的。然后journalnode我们是在01、02、03上开启的,所以04要少一个journalnode!所以不要惊慌!
用浏览器访问node01:50070和node02:50070


注意上面两张图中的标注,必须是一个是active,另一个是standby!!!除此之外都是错误的,需要检查是否是配置问题或者其他问题。
如果到此为止都是成功的话,那么我们的hadoop高可用模式就已经搭建了90%了,距离成功只有一步之遥了!
15、关闭集群
到这里,我们其实已经快成功了,这时我们需要关闭集群,进行下一步操作。关闭集群命令:stop-dfs.sh 关闭zookeeper命令:zkServer.sh stop
这两个命令都执行后,你可以执行:jps 查看还有什么进程没有关闭,如果还有进程没有关闭的(除了jps),可以简单粗暴执行命令:stop-all.sh(不建议!)正常情况下是执行对应节点的关闭命令。例如journalnode节点的启动命令是:hadoop-daemon.sh start journalnode 则关闭命令就是:hadoop-daemon.sh stop journalnode。
注意:你下一次启动hdfs集群的时候还需要用hadoop-daemon.sh start journalnode命令启动journalnode吗?不需要!只要start-dfs.sh就可以了。我们之前启动journalnode是为了同步两个namenode之间的信息。
16、为MapReduce做准备
①在node01上,到hadoop文件下修改配置,执行命令:cd /opt/zqq/hadoop-2.6.5/etc/hadoop
此时你在hadoop的路径下:ll

把mapred-site.xml.template留个备份,并且改下名字,执行命令:cp mapred-site.xml.template mapred-site.xml
在mapred-site.xml里添加如下property,执行命令:vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
添加后保存并退出!(按下Esc加上“:wq”)
在yarn-site.xml里添加如下property,执行命令:vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node05</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node06</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node04:2181,node05:2181,node06:2181</value>
</property>
添加后,保存并退出(按下Esc加上“:wq”)
②把mapred-site.xml和yarn-site.xml 分发到node02、03、04,在node01中分别执行命令:
scp mapred-site.xml yarn-site.xml node04:`pwd`
scp mapred-site.xml yarn-site.xml node05:`pwd`
scp mapred-site.xml yarn-site.xml node06:`pwd`
前提是要在hadoop的路径下,否则找不到.xml文件,就会有错误!
③****由于node03和node04都是resourcemanager,所以它俩应该相互免密钥
node03上免密钥登录node04:
首先执行命令:cd .ssh 下面要在.ssh路径下执行其他命令。
在node03的.ssh目录下生成密钥,执行命令:ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys,执行命令:cat id_dsa.pub >> authorized_keys
然后用命令:ssh localhost验证看是否需要密码,别忘了exit
将node03 的公钥分发到node04,执行命令:scp id_dsa.pub node04:pwd/node03.pub
在node04的.ssh目录下,追加node03.pub,执行命令:cat node03.pub >> authorized_keys
在node03上执行命令:ssh node04,看是否免密钥,如果不需要密码则免秘钥成功!
相同操作,node04免秘钥登录node03。最后要互相验证,并且不要忘记exit!
16、启动
①启动zookeeper,全部会话:zkServer.sh start
②在node01上启动hdfs:start-dfs.sh
③在node01上启动yarn:start-yarn.sh
④在node03、04上分别启动resourcemanager,执行命令:yarn-daemon.sh start resourcemanager
⑤全部会话:jps,看进程全不全!
node01为:
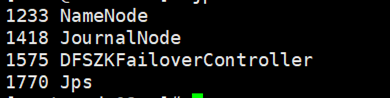
node02为:
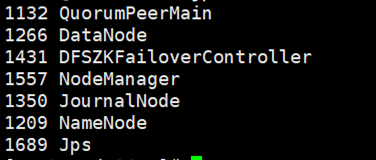
node03为:
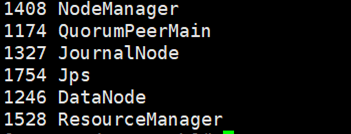
node04为:
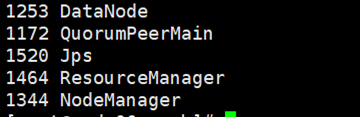
对应着看,自己有哪些节点没有开起来,没有的话,就去检查相关配置或者去百度查找解决办法。
如果都成功的话就在浏览器上访问node05:8088,查看resourcemanager管理的内容

至此,hadoop的高可用集群已经搭建完成!!!!
**
三、测试
**
集群搭建完成后,我们来跑一个wordcount试试!
在node03上:
①cd /opt/ldy/hadoop-2.6.5/share/hadoop/mapreduce
②在hdfs里建立输入目录和输出目录
命令为:hdfs dfs -mkdir -p /data/in
命令为:hdfs dfs -mkdir -p /data/out
③将要统计数据的文件上传到输入目录并查看
命令为:hdfs dfs -put ~/500miles.txt /data/input
命令为:hdfs dfs -ls /data/input
④运行wordcount(注意:此时的/data/out必须是空目录
命令为:hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result
命令④结束后,就会出现下图所示,一定要出现图中的红圈圈才可以!

⑤查看运行结果
命令为:hdfs dfs -ls /data/out/result
命令为:hdfs dfs -cat /data/out/result/part-r-00000
结果如图:
然后切换到浏览器上,刷新刚才的页面:

如上图,即可!
测试完成!
Hadoop高可用集群搭建完成!
能做到这一步的人可都是小天才呢!ヾ(◍°∇°◍)ノ゙
最后!不要忘了关闭集群以及zookeeper哦!
四、报错以及解决办法
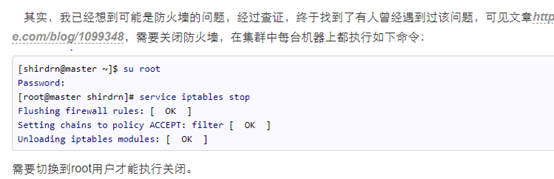
1、格式化namenode错误:
不能格式化namenode,下图是去日志里找到的错误:

百度了好久,最开始是要求关闭防火墙,就按照一般的关闭防火墙的命令
关闭后发现还是不能正确的格式化namenode,最后百度到要求在
root用户里去关闭防火墙,然后格式化成功。
具体网址如下:http://www.voidcn.com/article/p-qtkiyjco-tt.html
2、虚拟机繁忙问题(大多是不正当操作引起的!)
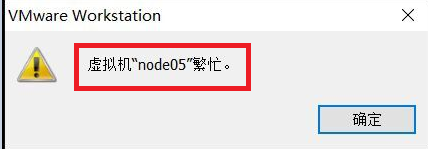
解决:①如果出现这种情况,你是无法通过任务管理器关闭的!这个时候你就要重启你的计算机!
②重启后先不要开启VMware,你可以到你刚才无法打开的那台虚拟机的文件下,删除.lck文件,再重启即可!

3、启动第二个namenode遇到的问题
node01节点已经采用hadoop-daemon.sh start namenode启动了一个namenode节点
这时候如果你还用hadoop-daemon.sh start namenode去02节点启动namenode是起不来的
必须现在02节点bin目录下执行:sh hdfs namenode -bootstrapStandby
其实没那么多错误,大部分的错误是因为自己的不细心而产生的,所以大家配置的时候一定要**细心!细心!**不然会被错误折磨到大半夜的!!!
加油!奥利给!