Hadoop高可用集群搭建
搭建高可用集群,需要涉及到 8 个配置文件
1.zookepper 节点的 zkdata文件目录下的 myid
2.zookepper 节点的zkdata文件目录下的zoo.cfg
3.hadoop安装目录下的etc/hadoop/ 目录下的 hadoop-env.sh
4.hadoop安装目录下的etc/hadoop/ 目录下的 core-site.xml
5.hadoop安装目录下的etc/hadoop/ 目录下的 hdfs-site.xml
6.hadoop安装目录下的etc/hadoop/ 目录下的 slaves
7.hadoop安装目录下的etc/hadoop/ 目录下的 yarn-site.xml
8.hadoop安装目录下的etc/hadoop/ 目录下的 mapred-site.xml
`集群策略:
zk 1 、2 、3为 zookapper
hadoop4、5为 namenode
hadoop6、7为``resourcemanager
hadoop 8、9 、10为 namdnode 、journalnode 以及 nodemanager
集群搭建思路与配置文件详细内容
1.搭建zookepper集群
目的:为了保证集群环境下故障的自动转移(至少3台、奇数)
①myid
1
在系统上创建一个 zkdata 的文件目录,向其中touch 一个名为myid 的文件
为了保证每台zk都有自己的唯一标识。
②zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata
clientPort=3001
server.1=主机名:3002:3003
server.2=主机名:4002:4003
server.3=主机名:5002:5003
在zkdata文件目录下创建zoo,cfg文件,内容如上所示。
dataDir 为文件目录
clientPort 3001 为zk服务器的端口(客户端处理端口)
3002:内部作数据的原子广播端口
3003:内部作选举容错的端口
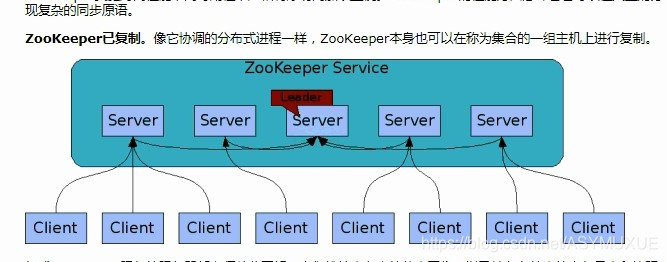
原子广播:即任一fellow服务器将客户端的写的请求,在所有服务器间同步。
至此,zookepper集群准备工作已完成的。
zk集群的命令:
在 zk安装目录下的bin目录中执行
./zkServer.sh start /root/zkdata/zoo.cfg (启动)
./zkServer.sh status /root/zkdata1/zoo.cfg (查看状态)
2.搭建hdfs集群
前置工作:
修改静态ip地址: vim /etc/sysconfig/network-script/ifcfg-ens37
主机名: vim /etc/hostname
ip映射: vim /etc/hosts
配置ssh免密登录: ssh-keygen -t rsa (生成秘钥 ) 、 ssh-copy-id 主机名 (分发秘钥)
③hadoop-env.sh
修改其中的jdk的环境变量,目的:远程访问时,环境变量是失效的,保证远程访问时能够正常运行。
export JAVA_HOME=/自己的安装目录
④core-site.xml
hadoop核心的配置文件
<!-- 高可用集群的配置 -->
<!-- 文件系统的入口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 文件系统的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.9.2/data</value>
</property>
<!-- ZK系统的IP及Port -->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:3001,zk2:4001,zk3:5001</value>
</property>
因为是集群,所以不再具体指定文件系统的入口,以自定义名称***ns*** 代替。
⑤hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop4:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop4:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop5:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop5:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop8:8485;hadoop9:8485;hadoop10:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 可视化界面可写操作 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
⑥slaves
hadoop8
hadoop9
hadoop10
配置的三台主机,既作为dataNode 又作为nodeManager。
⑦yarn-site.xml
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop24</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop25</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop6:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop7:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk:3001,zk:4001,zk:5001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
⑧mapred-site.xml
<!--配置计算框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--配置历史服务器的TCP端口-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop10:10020</value>
</property>
<!--配置历史服务器的web端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop10:19888</value>
</property>
注:因为hadoop目录下默认没有mapred-site.xml 的文件。所以需要手动复制,执行如下命令:
cp hadoop-2.9.2/etc/hadoop/mapred-site.xml.template hadoop-2.9.2/etc/hadoop/mapred-site.xml
可以建立出mapred文件
至此,集群搭建的配置工作已完成
3.启动hadoop高可用集群
命令(有顺序)
☆☆☆☆ yum install psmisc -y (所有节点安装centos7.x搭建集群的依赖)
☆☆☆☆hdfs zkfc -formatZK (在任意的nameNode上执行,格式化ZK)
☆☆☆☆hadoop-daemon.sh start journalnode (在所有journalNode节点执行启动)
先启动journalNode是为了保证在格式化nameNode(拥有数据)之前,保证数据的同步性。
☆☆☆☆hdfs namenode -format ns (在active【自选】的nameNode上执行启动)
☆☆☆☆start-dfs.sh (启动hdfs文件系统)
☆☆☆☆hdfs namenode -bootstrapStandby(在standby的nameNode上执行格式化)
☆☆☆☆hadoop-daemon.sh start namenode(启动standby的nameNode节点)
☆☆☆☆start-yarn.sh (在active【自选】的resourcesNode上执行启动雅恩节点)
☆☆☆☆yarn-daemon.sh start resourcemanager(启动standby的resourcesManager节点)
4.测试集群
访问
ip:50070 文件系统HDFS的web界面
ip:8088 雅恩yarn resourcesManager 的web界面
其他命令:
☆☆☆☆ mr-jobhistory-daemon.sh start histroyserver (启动历史服务器)
☆☆☆☆ hadoop jar 包名 (运行jar包,执行job作业)
ip:19888 历史服务器的web界面
