快捷跳转
站在hadoop2.x的角度批斗hadoop1.x
- HDFS
- NameNode压力过大,内存受限,系统扩展性差
- NameNode单点故障,NameNode宕机系统就瘫痪了,在线场景中难以应用.
- MapReduce
- JobTracker访问压力大,影响系统扩展性
难以支持除MapReduce之外的计算框架,比如Spark、Storm等.
hadoop 2.x
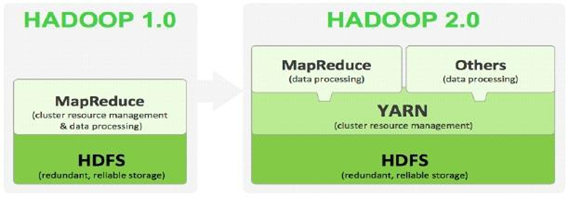
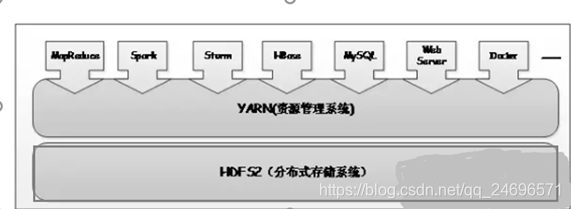
- HDFS:分布式文件存储系统;
- YARN:资源管理系统
- Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;
- 将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
- ResourceManager: 负责整个集群的资源管理和调度。
- ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
- YARN的引入,使得多个计算框架可运行在一个集群中
- 每个应用程序对应一个ApplicationMaster
- 目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、Storm
等。
- MapReduce:运行在YARN上的MR;
- HDFS结构图
- 解析
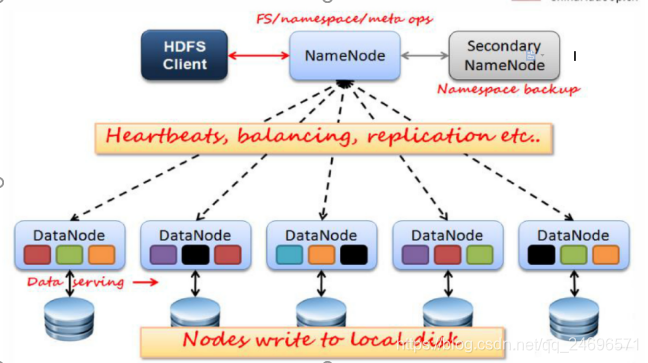
- DateNode心跳保持,每3秒向NameNode发送相关信息.
- 2.x的架构支持2个NameNode节点
- NameNode接受读写服务,将元数据信息交给JournalNode(JN) .
- 2台NameNode,谁拿到竞争锁,谁就是active,另外一台作为备份,active的NameNode宕机之后会释放竞争锁,另一台NameNode就会持有竞争锁,进入active状态
- journalNode是一个集群,至少3台及以上,NameNode提交的对元数据信息进行读写保存操作.journalNode的副本备份策略是过半原则:3台服务器最少备份2份,集群基本是奇数量的服务器.
- Zookeeper服务器的作用是帮助NameNode之间做主备切换
- FailoverControllerActive:竞争锁,NameNode服务器谁抢到谁就是主,余者备
- 解决单点故障
-部署了2台NameNode,服务器启动时,抢到竞争锁的NameNode对外提供服务(active),另一台NameNode(Standby),同步NameNode(active)的元数据,通过JN服务器,所有DataNode需要同时向两台NameNode汇报信息.
- 主备NameNode之间的切换:1.手动切换,通过命令实现,常用于HDFS升级的场合. 2.自动切换:基于Zookeeper实现
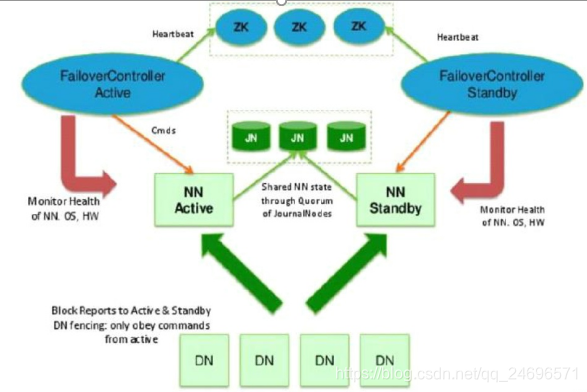
- YARN资源管理任务调度流程
-
- 客户端提交一个任务或者请求或者操作给yarn的ResourceManager资源管理,ResourceManager掌握整个集群的资源
- ResourceManager会根据它掌握的信息,随机找一台DateNode启动ApplicationMater进行任务调度.
- ApplicationMaster启动后,开始任务调度,向ResourceManager请求资源,用来启动进程(Executor),执行任务
- ResourceManager将任务的资源信息返回给ApplicationMaster
- ApplicationMaster获得资源信息 , 去执行任务.去指定的DateNode启动进程,然后对应的资源返回给客户端
集群搭建
-
规划
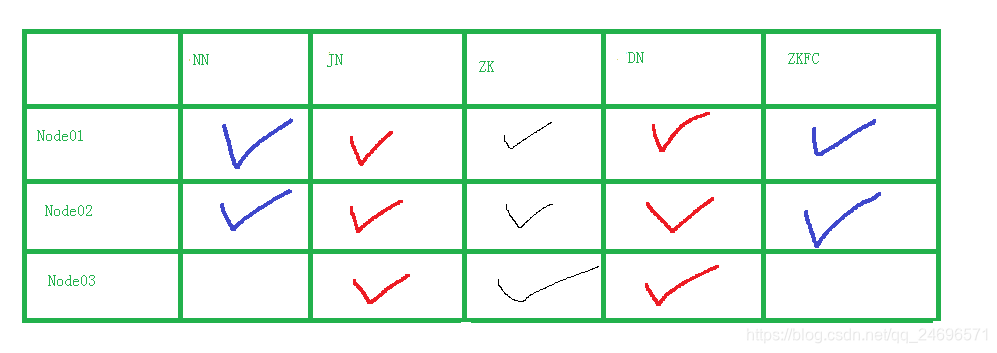
-
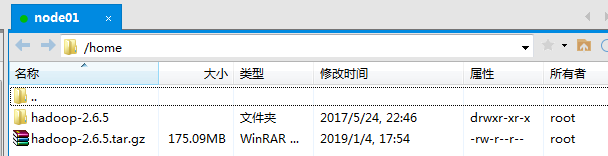
首先将hadoop安装包上传到服务器,并且解压
-
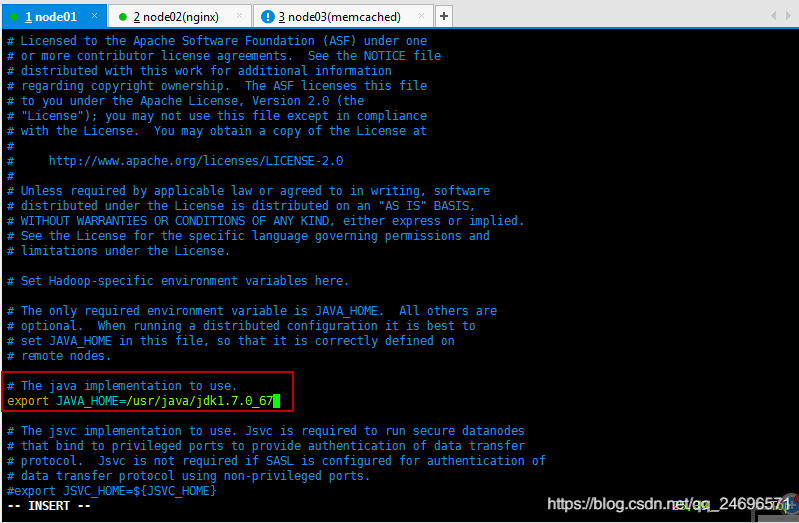
环境变量配置,安装包解压的文件夹中的ect/hadoop目录下的hadoop-env.sh
-
vim /home/hadoop-2.6.5/etc/hadoop/hadoop-env.sh打开配置文件,修改环境变量
- 修改同一目录下,vim core-site.xml设置核心的相关配置
vim /home/hadoop-2.6.5/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Credi</value> #与hadoop1.x不同,NameNode有2台,所以取个别名
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value> #填写规划作为zookeeper的三台服务器
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.5</value> #namenode和datanode的数据文件的存放位置,默认就放在这个路径中
</property>
</configuration>
- 修改同一目录下,vim hdfs-site.xml
vim /home/hadoop-2.6.5/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name> <!-- 命名的服务 -->
<value>Credi</value> <!-- 刚才指定了两台NameNode集群别名 ,下面如果有Credi的字符请自行更改自己的别名-->
</property>
<property>
<name>dfs.ha.namenodes.Credi</name>
<value>nn1,nn2</value> <!-- NameNode集群每台服务器别名,有几台写几台-->
</property>
<property>
<name>dfs.namenode.rpc-address.Credi.nn1</name><!--nn1别名的服务器配置-->
<value>node01:8020</value> <!--nn1别名指向的规划作为NameNode的服务器,自主分配-->
</property>
<property>
<name>dfs.namenode.rpc-address.Credi.nn2</name>
<value>node02:8020</value> <!--nn2别名指向的规划作为NameNode的服务器,自主分配-->
</property>
<property>
<name>dfs.namenode.http-address.Credi.nn1</name>
<value>node01:50070</value> <!-- 客户端访问NameNode的url和端口 192.168.200.211:50070 或者windows环境下设置了ip地址别名的话可以:node01:50070 -->
</property>
<property>
<name>dfs.namenode.http-address.Credi.nn2</name>
<value>node02:50070</value> <!-- 客户端访问NameNode的url和端口 192.168.200.212:50070 或者windows环境下设置了ip地址别名的话可以:node02:50070 -->
</property>
<property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<name>dfs.namenode.shared.edits.dir</name><!--edits操作日志目录-->
<value>qjournal://node01:8485;node02:8485;node03:8485/Credi</value><!--规划作为journal服务器(JN)的ip地址别名:端口-->
</property>
<property>
<!-- 指定HDFS客户端连接active namenode的java类,固定写法 -->
<name>dfs.client.failover.proxy.provider.Credi</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置隔离机制为ssh 防止脑裂 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value><!-- 指定自己秘钥的位置 -->
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop2.6.5/data</value><!-- 指定journalnode日志文件存储的路径 -->
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value><!-- 开启自动故障转移 -->
</property>
</configuration>
- 修改同一目录下,slaves文件,配置DataNode服务器
vim /home/hadoop-2.6.5/etc/hadoop/slaves填写规划为DateNode的服务器
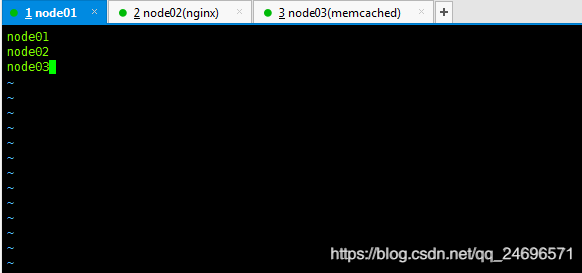
- 将/home/目录下的hadoop解压文件发送给其他规划为hadoop集群中的服务器
scp -r /home/hadoop-2.6.5 node02:/home/
scp -r /home/hadoop-2.6.5 node03:/home/
- 安装zookeeper
- 将zookeeper安装包上传到服务器
- /home/zookeeper-3.4.6/conf , conf目录下zoo_sample.cfg文件更名为zoo.cfg并编辑
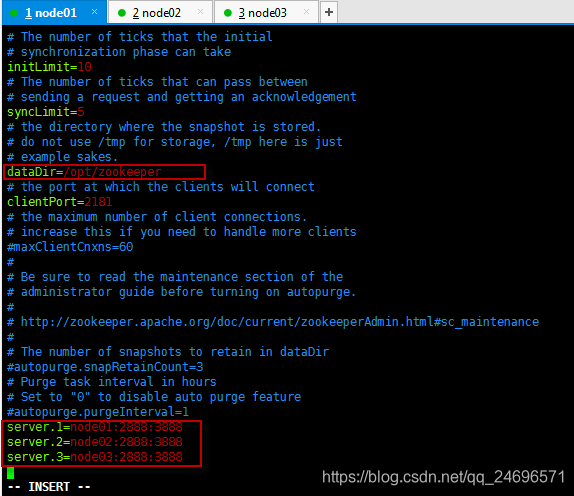
-修改dataDir=/opt/zookeeper,并配置规划为zookeeper服务器的别名和端口
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
3.在指定目录下创建myid文件
1.创建zookeeper文件夹
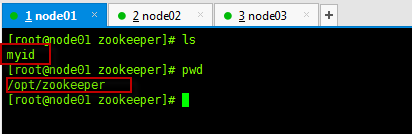
2. 创建myid文件vim /opt/zookeeper/myid
写入1,表示刚才zoo.cfg文件中配置的zookeeper服务器的server.1
3.将/opt/zookeeper目录发送其他规划为zookeeper的服务器的相同目录下,并各自更名,node02改2,node03改3,根据自身对zoo.cfg文件的设置
scp -r /opt/zookeeper/ node02:/opt/
scp -r /opt/zookeeper/ node03:/opt/
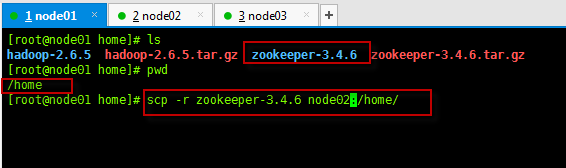
- 将/home/目录下的zookeeper解压文件发送给被规划为zookeeper服务器的node02和node03同等目录下
scp -r zookeeper-3.4.6 node02:/home/
- 配置hadoop和zookeeper的局部环境变量
vim ~/.bash_profile
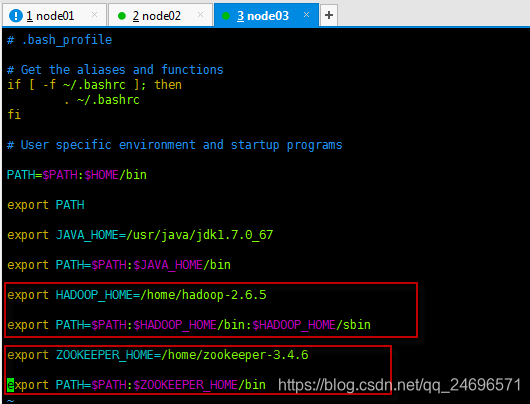
- 将配置好的文件拷贝到规划中,hadoop和zookeeper各自需要配置的服务器的同等路径下,此处需要灵活.
scp -r ~/.bash_profile node02:/root/
scp -r ~/.bash_profile node03:/root/ - 现在让这些配置好环境变量的服务器使用source命令生效
source ~/.bash_profile
追加配置链接:
启动hadoop2.x集群
- 关闭所有防火墙
- 启动所有的zookeeper服务器(ZK)
zkServer.sh start,
jps命令可以查看进程:QuorumPeerMain
zkServer.sh status查看状态
- if .非首次启动
- :全面启动
start-dfs.sh - yarn-daemon.sh start resourcemanager (yarn resourcemanager )
- else .首次启动
- 启动所有JournalNode服务器(JN)
hadoop-daemon.sh start journalnodejps:JournalNode - 启动NameNode服务器,JPS:NameNode
- 在NameNode服务器(NN)其中一台例如node01,执行格式化
hdfs namenode -format- 然后启动node01
hadoop-daemon.sh start namenode- 另外一台没有格式化的NameNode上执行
hdfs namenode -bootstrapStandby同步metadate元数据信息- 启动该台NameNode服务器
hadoop-daemon.sh start namenode
- 在两台NameNode中选择一台初始化zkfc:
hdfs zkfc -formatZK - :停止节点
stop-dfs.sh,为了获取竞争锁 - :全面启动
start-dfs.sh - yarn-daemon.sh start resourcemanager (yarn resourcemanager )
关闭集群
- 关闭yarn
yarn-daemon.sh stop resourcemanager - 关闭服务器集群:
stop-dfs.sh - 关闭所有zookeeper服务器(ZK)
zkServer.sh stop
有可能会出错的地方
1, 确认每台机器防火墙均关掉
2, 确认每台机器的时间是一致的
3, 确认配置文件无误,并且确认每台机器上面的配置文件一样
4, 如果还有问题想重新格式化,那么先把所有节点的进程关掉
5, 删除之前格式化的数据目录hadoop.tmp.dir属性对应的目录,所有节点同步都删掉,别单删掉之前的一个,删掉三台JN节点中dfs.journalnode.edits.dir属性所对应的目录
6, 接上面的第6步又可以重新格式化已经启动了
7, 最终Active Namenode停掉的时候,StandBy可以自动接管!
配置MapReduce后启动和关闭hadoop2.x集群
启动集群
- 关闭所有防火墙
service iptables stop - 启动所有的zookeeper服务器(ZK)
zkServer.sh start,
jps命令可以查看进程:QuorumPeerMain
zkServer.sh status查看状态 - 全面启动
start-all.sh - 规划作为RM服务器的节点启动ResourceManeger:
yarn-daemon.sh start resourcemanager
关闭集群
- 全面关闭
stop-all.sh - 关闭所有的zookeeper服务器(ZK)
zkServer.sh stop, - 规划作为RM服务器的节点关闭ResourceManeger:
yarn-daemon.sh stop resourcemanager