Large Kernel Matters ——
Improve Semantic Segmentation by Global Convolutional Network
论文创新点:
1、提出GCN网络结构,权衡定位与分类之间的精度矛盾
2、提出边界精细化模块Boundary Refinement block,提高语义分割前景物体边界的定位精度
Abstract
One of recent trends in network architec- ture design is stacking small filters (e.g., 1x1 or 3x3) in the entire network because the stacked small filters is more efficient than a large kernel, given the same computational complexity. However, in the field of semantic segmentation, where we need to perform dense perpixel prediction, we find that the large kernel (and effective receptive field) plays an important role when we have to perform the classification and localization tasks simultaneously. Following our design principle, we propose a Global Convolutional Network to address both the classification and localization issues for the semantic segmentation. We also suggest a residual-based boundary refinement to further refine the object boundaries. Our approach achieves state-of-art performance on two public benchmarks and significantly outperforms previous results, 82.2% (vs 80.2%) on PASCAL VOC 2012 dataset and 76.9% (vs 71.8%) on Cityscapes dataset.
摘要比较重要,原文粘在这里了,着重强调了卷积核小型化的趋势,但是大的卷积核提供更大的接受域,提出了GCN,全局卷积网络,并提出基于残差的边界refine去得到更好的分割边界。
文章总结
文章将语义分割定义为一个逐像素分类的任务,并阐明了该任务的两大挑战:分类、定位
但是呢,分类和定位任务又是natrually contradictory的:分类任务需要转换的不变性(比如平移和旋转),而定位任务需要对转换的敏感性
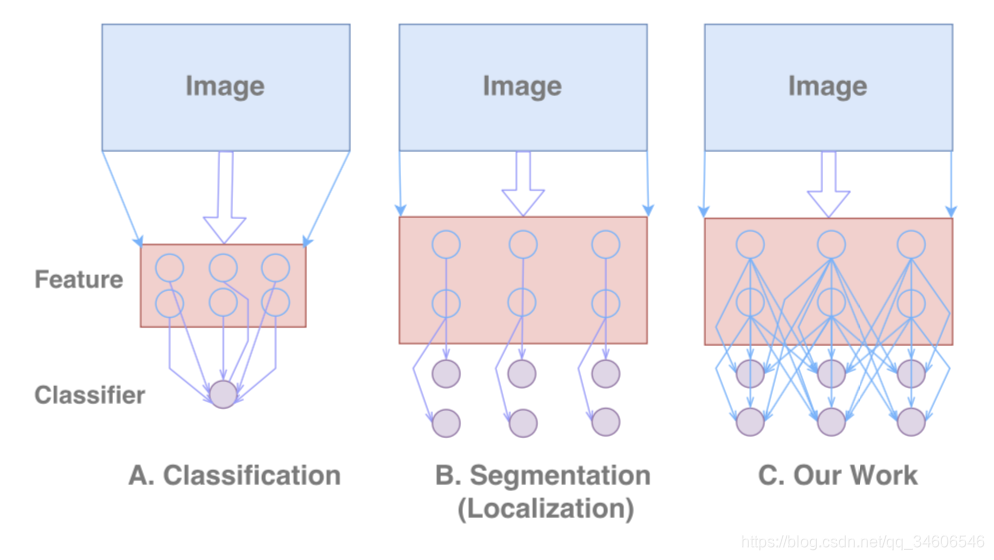
上图的解释:(Feature层表示提取的特征图,classifier表示分类器,分类网络有一个分类器在特征图后面,分割网络是aligned classifier,Our Work是两者的组合。)
A.Classification分类结构
典型的是imagenet竞赛中经典的分类特征提取网络如AlexNet、VGG Net 、 GoogleNet 、ResNet等锥形结构网络。通过对应的隐层进行特征提取,尾部的分类器或全局池化对提取的特征进行密集连接。这使得网络对局部扰动和低阶分类器具有鲁棒性,能够处理不同类型的输入转换。
B.Localization定位结构
与分类不同,该任务需要大的特征图,而不是像分类中对特征进行提取精化得到小的特征图,这里大特征图的目的是定位任务需要编码更多的空间位置信息,这也就解释了大多分割网络如FCN、DeepLab、Deconv-Net等网络采用桶装结构–保留更多的空间信息。目前通常使用的用来扩展特征图的方法有:1)Deconvolution、2)Unpooling、3)Dilated-Convolution。并且不同于分类网络,分类器与特征图密集连接,这里分类器与特征图是局部连接的,因为特征图比较大,即实现逐像素的分类。
C.Our Work文章提出的结构
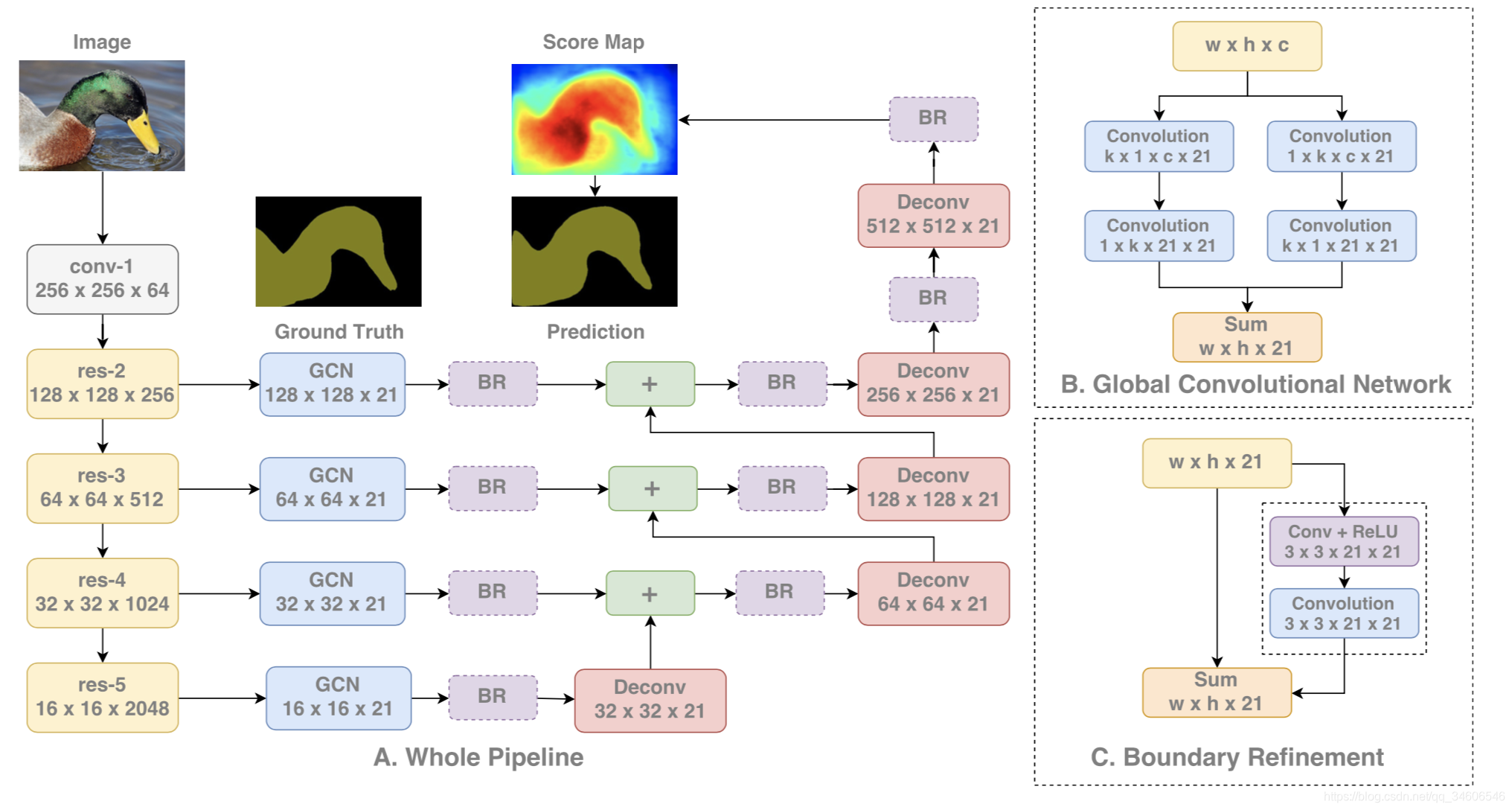
文章提出GCN结构,两个设计原则:
1)定位角度:使用全卷积保持定位信息,不使用全连接和全局池化结构,因为这两种结构会丢失掉一些位置信息;定位角度缺失了分类的旋转、尺度缩减的不变性,文章提到了有效接受域VRF,当输入的尺度改变时,有效接受域随之改变了,但是GCN保持了有效接受域足够大能包围目标物体,如下图:

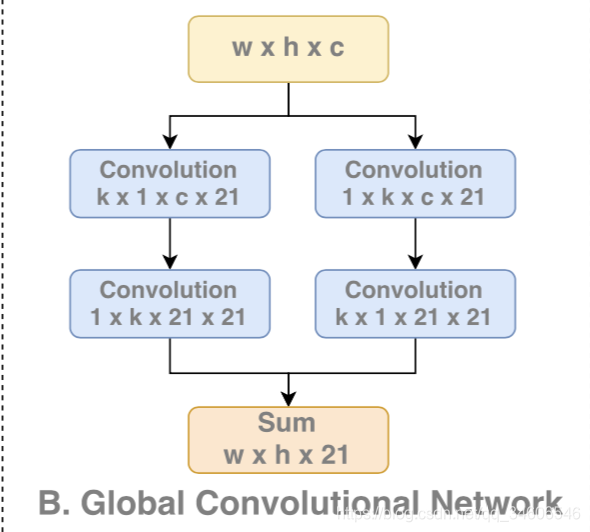
2)分类角度:大尺寸的卷积核,这里用对称的独立卷积核组成大size的卷积核,减小了大量的参数(kxk -> kx1+1xk),并且没有非线性操作。
还要注意这里文章有段原话是the kernel size of the convolutional
structure should be as large as possible.卷积核size尽可能的大,为什么呢?我认为是因为从定位角度出发取消了全连接结构,但又要维持分类性能即需要全连接的特性,所以用一个尽可能大的卷积size来取缔全连接结构。试想其实一个与feature map的宽高相同的kernel size进行卷积操作其实就是全连接计算。
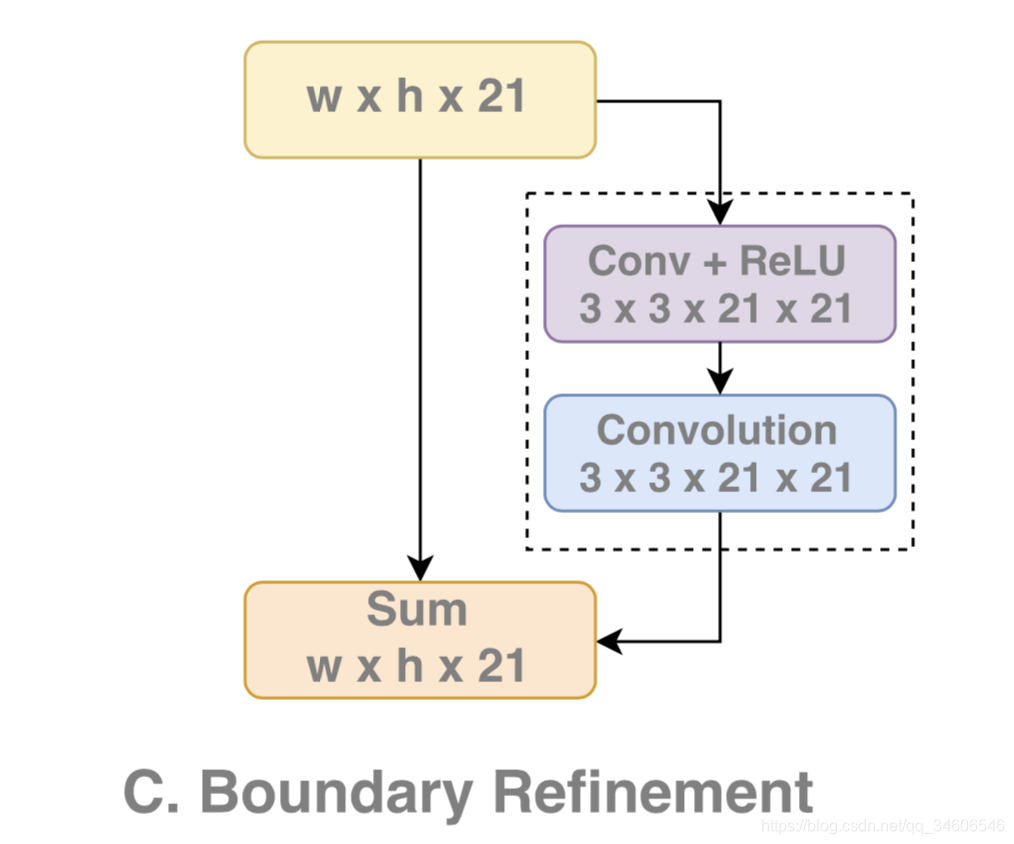
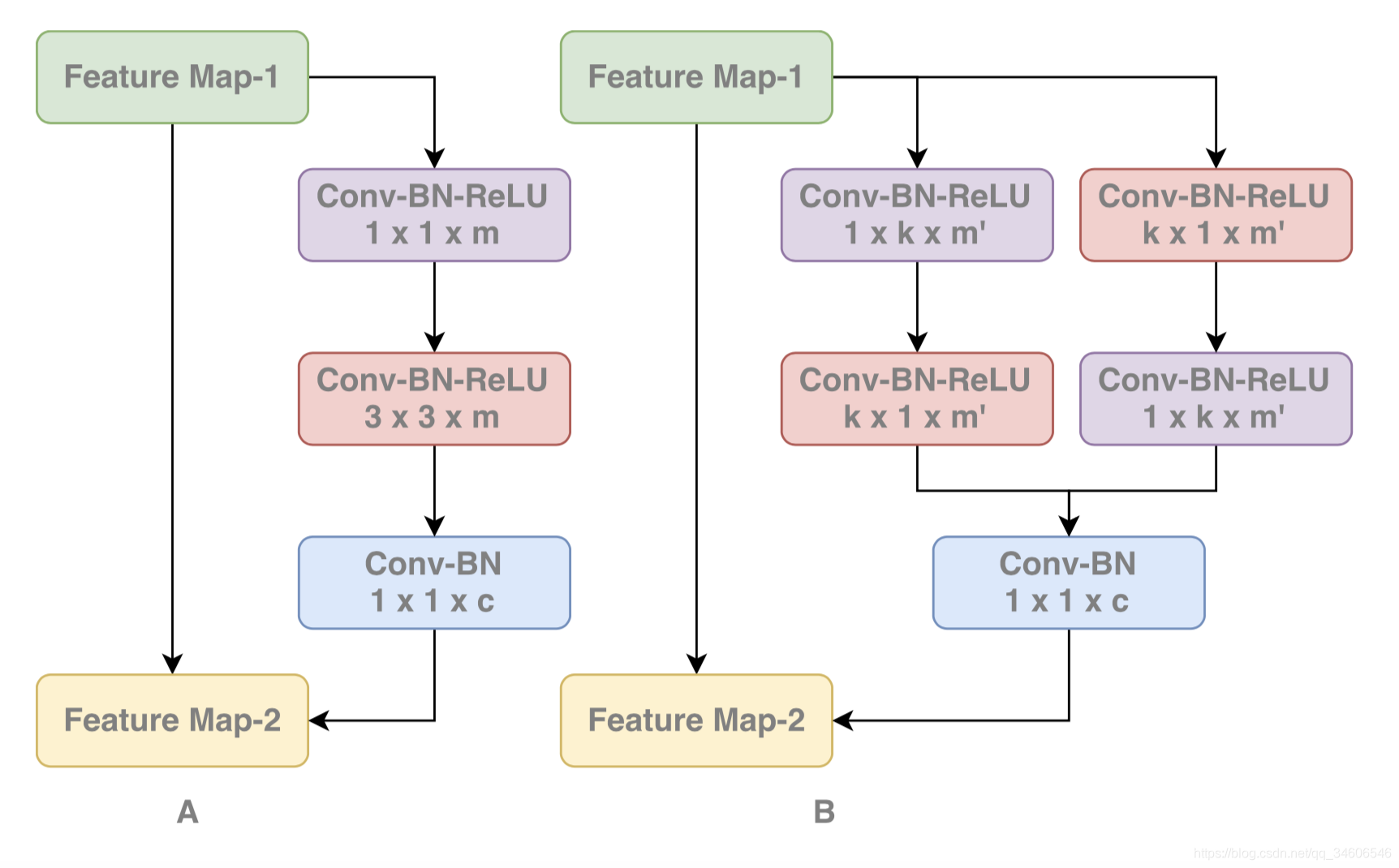
3)、BR模块
另外设计BR模块使边界处的定位能力大大提升。这里是一个残差结构,进行边缘的refinement。

文章通过消融实验(Ablation Experiments)对比了卷积核size对实验效果的影响,同时也比较了四种实现kxk卷积核的结构:
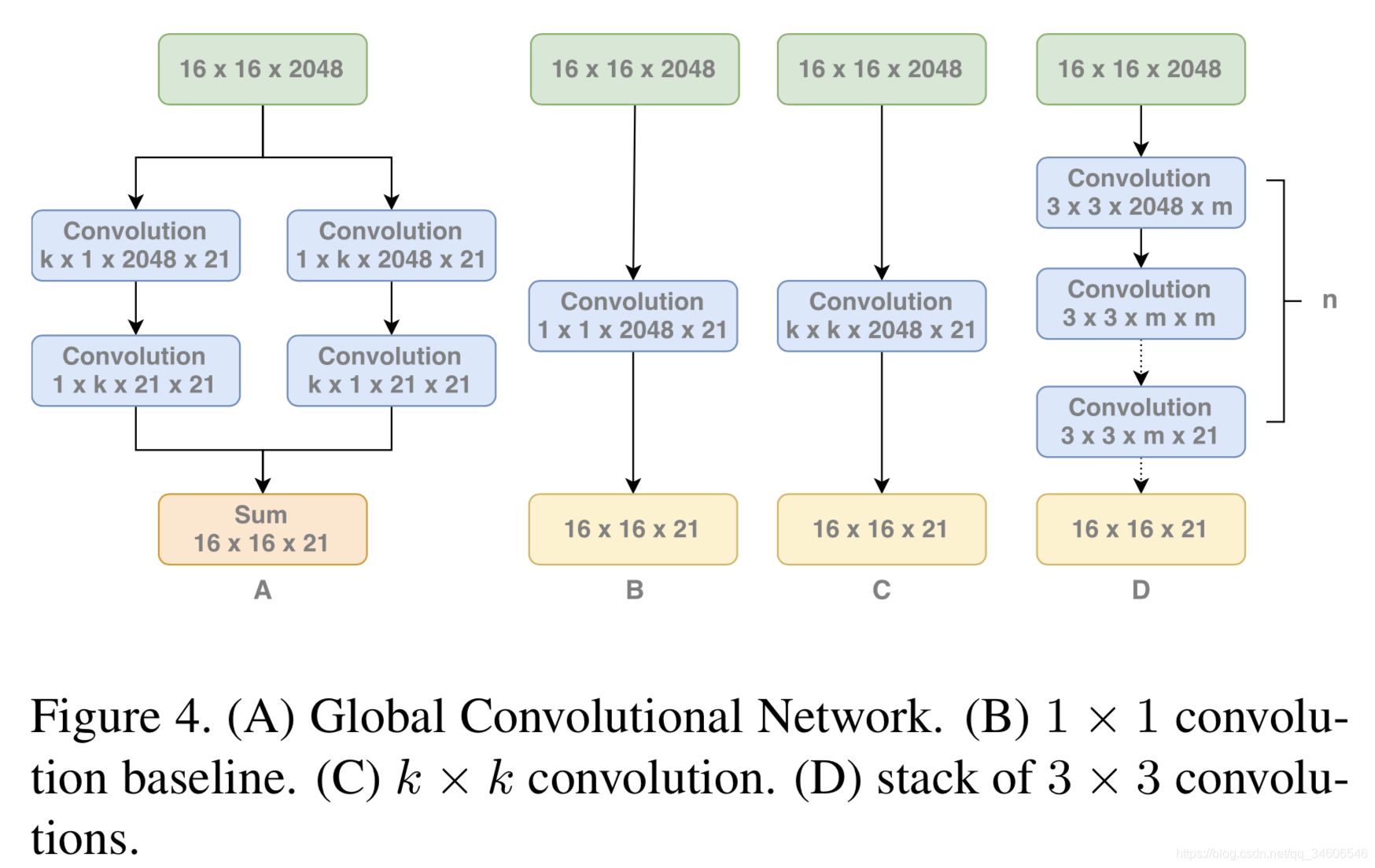

的确随着k的增加,score越来越高了,不过原因真的是因为GCN结构带来的好处还是只是因为k的增加带来了更多的参数,所以表示能力更强导致的呢,作者又进行了新的比对实验
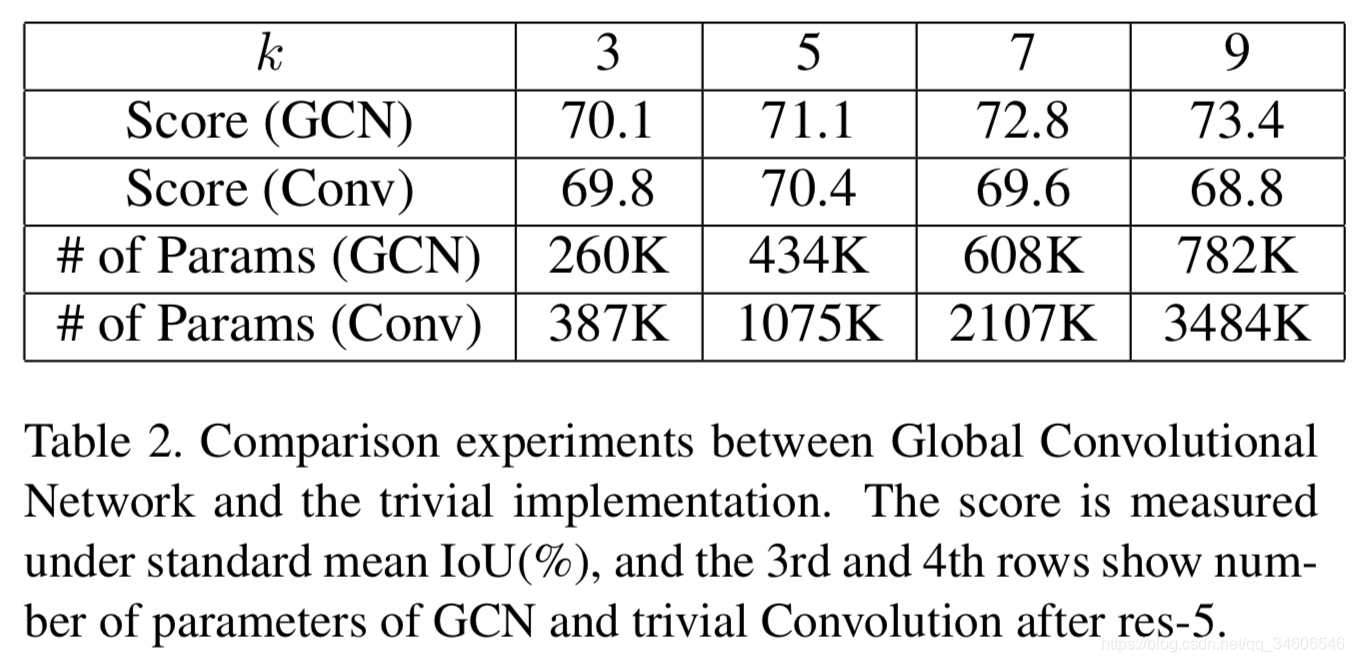
过对的参数导致过拟合,在k由5–>7时conv的参数增加但是IoU下降了。下面是多个小卷积核与单大卷积核的对比

另外一个重要的实验对比是将特征图分为两个区域(边界区域、物体内部区域)为的是比较GCN结构中密集连接对那一部分有更强的改进效果,同时也比对了BR模块对边界分割效果。这也解释了为什么我们在跑GCN时内部空洞小了很多,但是对小尺度的物体,分割边界肉眼效果与BiseNet还是差了一些的。

既然大size 的卷积核已经被验证有着重要的作用,那么干脆backbone里的卷积也直接用GCN好了,所以作者又提出了ResNet-GCN结构:
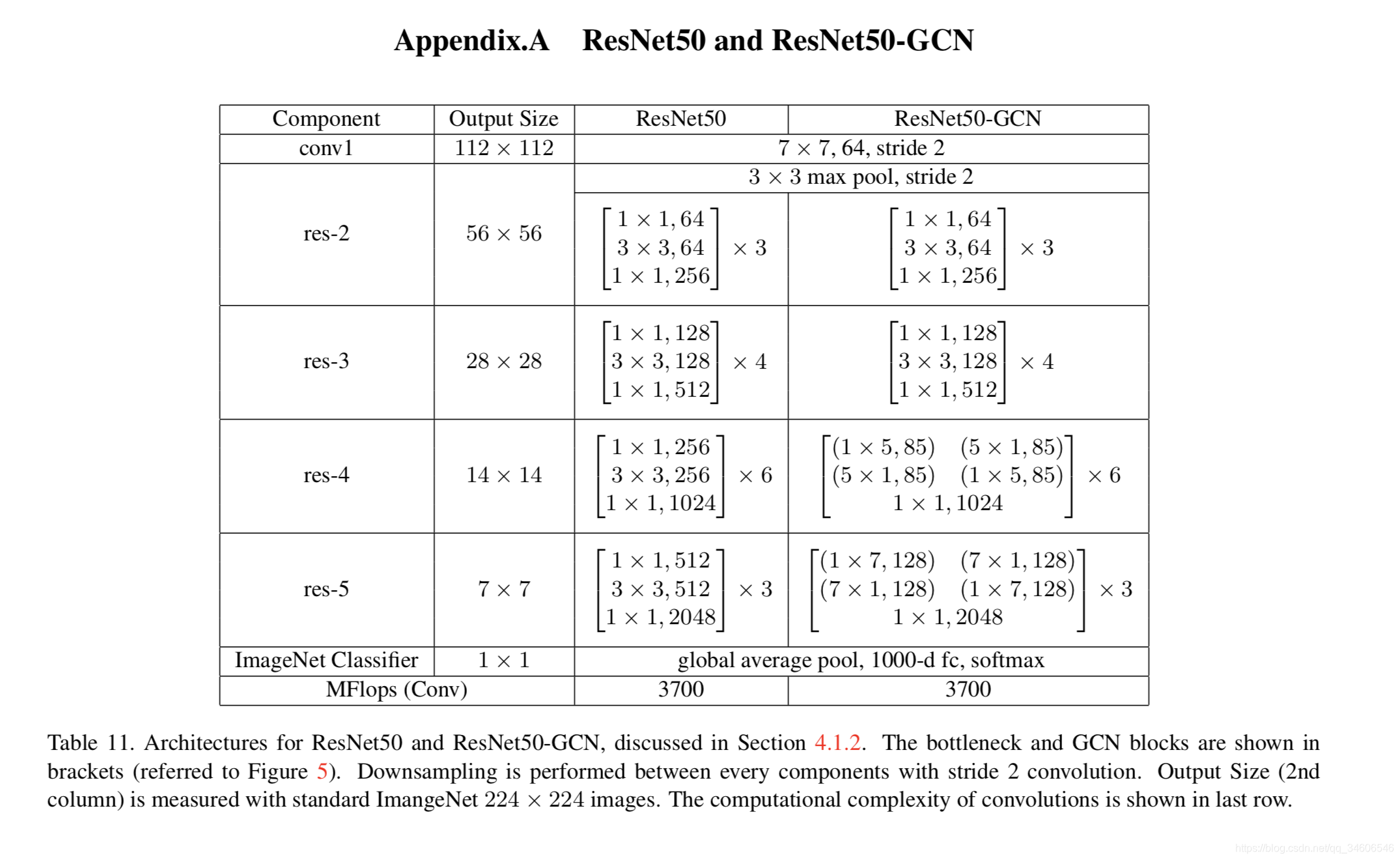

用ImageNet2015进行预训练,PASCAL VOC2012微调的实验对比:
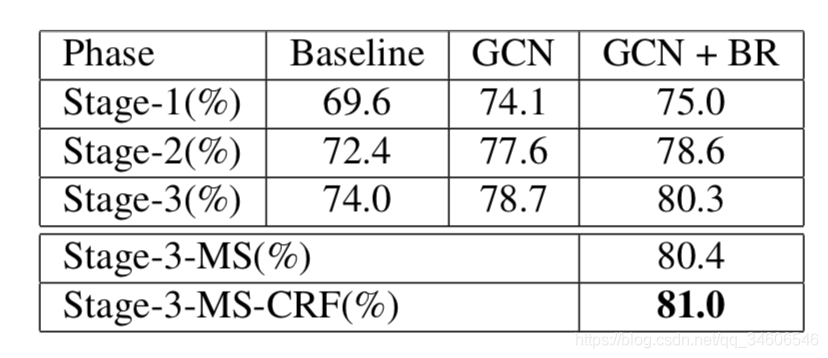
不同阶段比对,效果:GCN+BR > GCN > Baseline,并且加CRF效果更好,因为边界处理的确实存在问题。
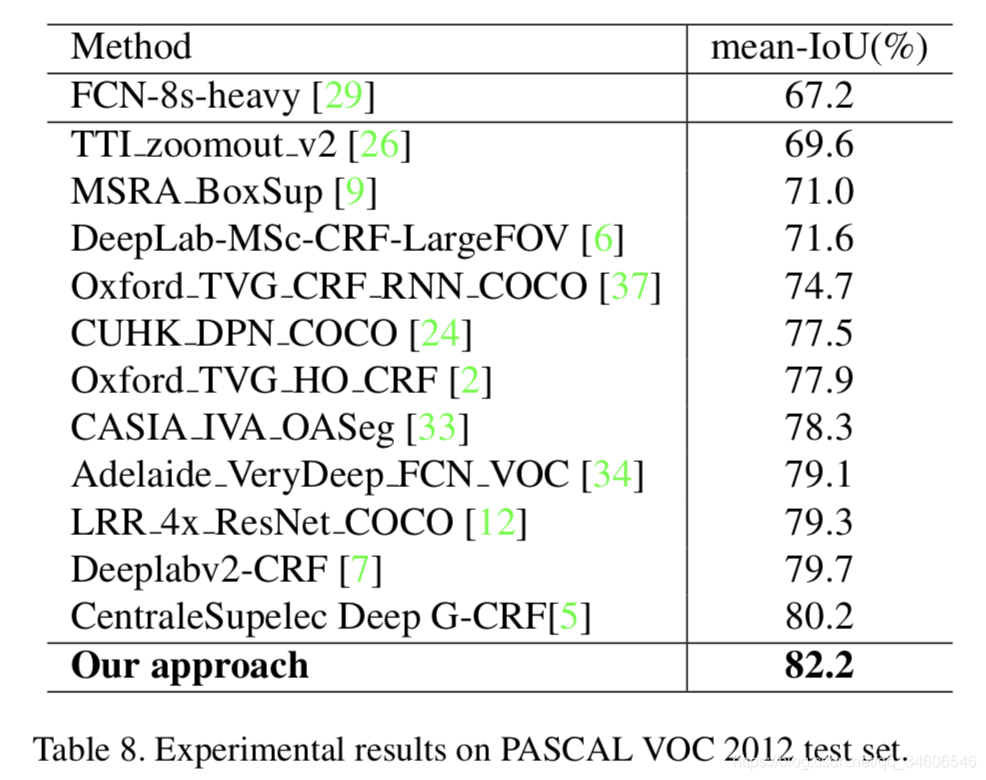
与state-of-the-arts的比对:
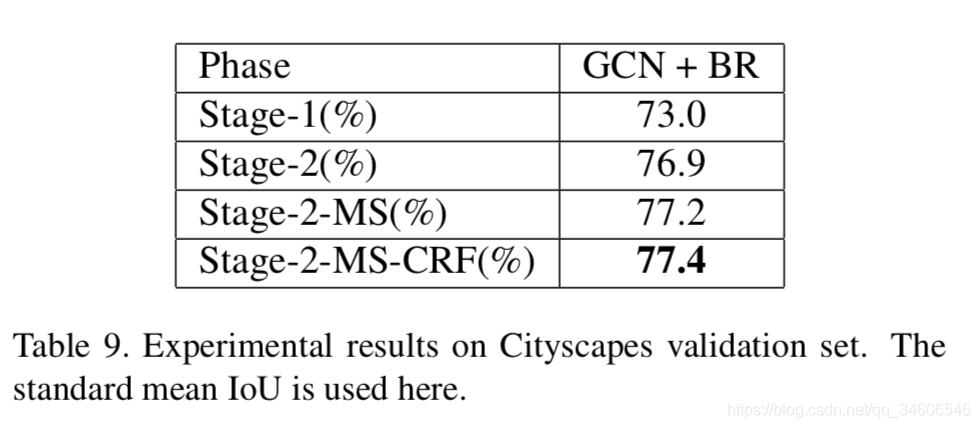
最后是在Cityscapes数据集上的实验效果:

最后发现一个很棒的github地址,里面有非常多的分割网络的pytorch实现,学习pytorch的时候可以用啦。
https://github.com/zijundeng/pytorch-semantic-segmentation
这篇博客里也比较详细的为GCN的pytorch代码添加了注释
https://blog.csdn.net/u011974639/article/details/78897066
GCN:
# many are borrowed from https://github.com/ycszen/pytorch-ss/blob/master/gcn.py
class _GlobalConvModule(nn.Module):
def __init__(self, in_dim, out_dim, kernel_size):
super(_GlobalConvModule, self).__init__()
pad0 = (kernel_size[0] - 1) / 2
pad1 = (kernel_size[1] - 1) / 2
# kernel size had better be odd number so as to avoid alignment error
super(_GlobalConvModule, self).__init__()
self.conv_l1 = nn.Conv2d(in_dim, out_dim, kernel_size=(kernel_size[0], 1),
padding=(pad0, 0)) # 左kx1卷积
self.conv_l2 = nn.Conv2d(out_dim, out_dim, kernel_size=(1, kernel_size[1]),
padding=(0, pad1)) # 左1xk卷积
self.conv_r1 = nn.Conv2d(in_dim, out_dim, kernel_size=(1, kernel_size[1]),
padding=(0, pad1)) # 右1xk卷积
self.conv_r2 = nn.Conv2d(out_dim, out_dim, kernel_size=(kernel_size[0], 1),
padding=(pad0, 0)) # 右kx1卷积
def forward(self, x):
x_l = self.conv_l1(x)
x_l = self.conv_l2(x_l)
x_r = self.conv_r1(x)
x_r = self.conv_r2(x_r)
x = x_l + x_r # sum操作
return x
BR:
class _BoundaryRefineModule(nn.Module):
def __init__(self, dim):
super(_BoundaryRefineModule, self).__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(dim, dim, kernel_size=3, padding=1) # 分支3x3卷积
self.conv2 = nn.Conv2d(dim, dim, kernel_size=3, padding=1) # 分支3x3卷积
def forward(self, x):
residual = self.conv1(x)
residual = self.relu(residual) # Conv + ReLU
residual = self.conv2(residual) # Conv
out = x + residual # sum操作
return out
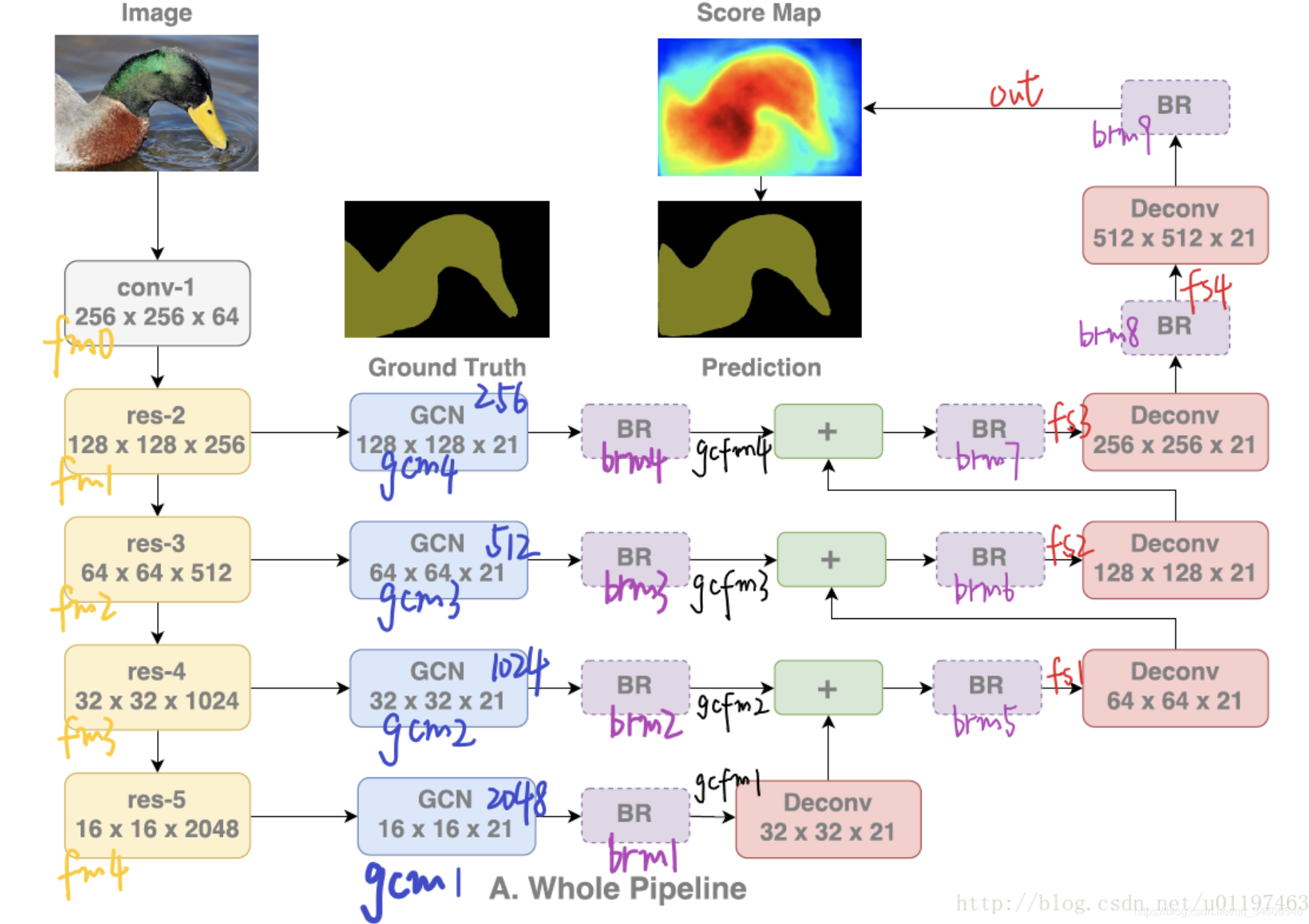
class GCN(nn.Module):
def __init__(self, num_classes, input_size, pretrained=True):
super(GCN, self).__init__()
self.input_size = input_size
resnet = models.resnet152()
if pretrained:
resnet.load_state_dict(torch.load(res152_path))
self.layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu)
self.layer1 = nn.Sequential(resnet.maxpool, resnet.layer1)
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
# 所有GCN模块
self.gcm1 = _GlobalConvModule(2048, num_classes, (7, 7))
self.gcm2 = _GlobalConvModule(1024, num_classes, (7, 7))
self.gcm3 = _GlobalConvModule(512, num_classes, (7, 7))
self.gcm4 = _GlobalConvModule(256, num_classes, (7, 7))
# 所有BR模块
self.brm1 = _BoundaryRefineModule(num_classes)
self.brm2 = _BoundaryRefineModule(num_classes)
self.brm3 = _BoundaryRefineModule(num_classes)
self.brm4 = _BoundaryRefineModule(num_classes)
self.brm5 = _BoundaryRefineModule(num_classes)
self.brm6 = _BoundaryRefineModule(num_classes)
self.brm7 = _BoundaryRefineModule(num_classes)
self.brm8 = _BoundaryRefineModule(num_classes)
self.brm9 = _BoundaryRefineModule(num_classes)
initialize_weights(self.gcm1, self.gcm2, self.gcm3, self.gcm4, self.brm1, self.brm2, self.brm3,
self.brm4, self.brm5, self.brm6, self.brm7, self.brm8, self.brm9)
def forward(self, x):
# if x: 512
fm0 = self.layer0(x) # 256
fm1 = self.layer1(fm0) # 128
fm2 = self.layer2(fm1) # 64
fm3 = self.layer3(fm2) # 32
fm4 = self.layer4(fm3) # 16
gcfm1 = self.brm1(self.gcm1(fm4)) # 16
gcfm2 = self.brm2(self.gcm2(fm3)) # 32
gcfm3 = self.brm3(self.gcm3(fm2)) # 64
gcfm4 = self.brm4(self.gcm4(fm1)) # 128
# 上采样融合输出
fs1 = self.brm5(F.upsample_bilinear(gcfm1, fm3.size()[2:]) + gcfm2) # 32
fs2 = self.brm6(F.upsample_bilinear(fs1, fm2.size()[2:]) + gcfm3) # 64
fs3 = self.brm7(F.upsample_bilinear(fs2, fm1.size()[2:]) + gcfm4) # 128
fs4 = self.brm8(F.upsample_bilinear(fs3, fm0.size()[2:])) # 256
out = self.brm9(F.upsample_bilinear(fs4, self.input_size)) # 512
return out