最近看了YOLOV1的论文,论文中很多细节并不清楚。之前看了RCNN系列的论文,也尝试跑了跑Tensorflow复现的代码,最近打算看看YOLO系列的目标检测论文。看了这篇论文后,第一个感觉这个方法速度很快,好像很厉害的样子,然后有一个很大的疑惑就是,这个YOLO到底是怎么提取'region proposal'的,如果你也有这个疑惑,那说明我们都是受RCNN系列的毒太深。YOLO系列号称单阶段目标检测算法,而RCNN系列是双阶段目标检测算法。个人理解这个区别就在'region proposal',RCNN系列是需要显示的先提取候选区域的,RCNN和Fast RCNN使用Slective Search算法提取候选框,Faster RCNN通过RPN网络提取候选区域,而YOLO则是没有显示的提取region proposal的过程,换句化说YOLO不用提取region proposal。下面来说说一些实现细节地方,一下基于个人理解,难免有理解不到位的地方。
1.YOLO特点
YOLO使用单一网络架构实现目标检测,不像RCNN系列把检测器当作一个分类器,分类每个候选区域的类别。YOLO则采用一种基于回归的端到端的思想直接预测一张图片中的所有类别以及它们bbounding box 位置。它的特点就是流程简单,速度非常快,本人在测试时候,用实验室GTX 1080 Ti达到了32/FPS.
2.YOLO训练过程
(1)darknet网络架构
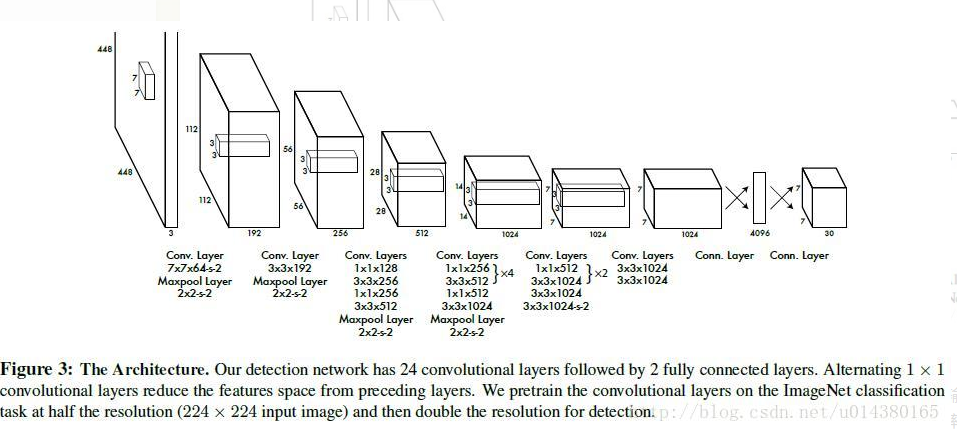
网络首先在Imagenet上预训练,预训练的时候,输入尺寸是224x224x3,所以只使用前20个卷积核,这时输出FeatureMap尺寸是7x7x1024,然后接一个全局平均池化,最后接一个全连接层分类。检测的时候输入resize到448x448x3,添加2个卷积层和2个全连接层,最后输出是7X7X30张量,当然是压缩成一维向量输出。
darknet
def build_network(self,
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
with tf.variable_scope(scope):
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
activation_fn=leaky_relu(alpha),
weights_regularizer=slim.l2_regularizer(0.0005),
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01)
):
# 对输入在宽度和高度上进行填充
# input shape batchx454x454x3
net = tf.pad(
images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),
name='pad_1')
# conv1 7x7x64 s=2
# padding valid
net = slim.conv2d(
net, 64, 7, 2, padding='VALID', scope='conv_2')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3')
# conv2 3x3x64x192
net = slim.conv2d(net, 192, 3, scope='conv_4')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5')
# 一组卷积操作
net = slim.conv2d(net, 128, 1, scope='conv_6')
net = slim.conv2d(net, 256, 3, scope='conv_7')
net = slim.conv2d(net, 256, 1, scope='conv_8')
net = slim.conv2d(net, 512, 3, scope='conv_9')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')
net = slim.conv2d(net, 256, 1, scope='conv_11')
net = slim.conv2d(net, 512, 3, scope='conv_12')
net = slim.conv2d(net, 256, 1, scope='conv_13')
net = slim.conv2d(net, 512, 3, scope='conv_14')
net = slim.conv2d(net, 256, 1, scope='conv_15')
net = slim.conv2d(net, 512, 3, scope='conv_16')
net = slim.conv2d(net, 256, 1, scope='conv_17')
net = slim.conv2d(net, 512, 3, scope='conv_18')
net = slim.conv2d(net, 512, 1, scope='conv_19')
net = slim.conv2d(net, 1024, 3, scope='conv_20')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21')
net = slim.conv2d(net, 512, 1, scope='conv_22')
net = slim.conv2d(net, 1024, 3, scope='conv_23')
net = slim.conv2d(net, 512, 1, scope='conv_24')
net = slim.conv2d(net, 1024, 3, scope='conv_25')
net = slim.conv2d(net, 1024, 3, scope='conv_26')
# pad batchx16x16x1024
net = tf.pad(
net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),
name='pad_27')
net = slim.conv2d(
net, 1024, 3, 2, padding='VALID', scope='conv_28')
net = slim.conv2d(net, 1024, 3, scope='conv_29')
net = slim.conv2d(net, 1024, 3, scope='conv_30')
# outshape batchx7x7x1024
net = tf.transpose(net, [0, 3, 1, 2], name='trans_31')
# 转置后将按照每一个7x7的矩阵按每一行进行展开
net = slim.flatten(net, scope='flat_32')
net = slim.fully_connected(net, 512, scope='fc_33')
net = slim.fully_connected(net, 4096, scope='fc_34')
net = slim.dropout(
net, keep_prob=keep_prob, is_training=is_training,
scope='dropout_35')
net = slim.fully_connected(
net, num_outputs, activation_fn=None, scope='fc_36')
# logists batchx(7x7x30) = batchx1470
return net (2)训练细节
一开始自己的疑问是怎么产生候选区域。YOLO首先把输入图像尺寸resize 到448x448,然后把输入图像划分成SXS个grid,论文中是7*7,所以每个grid的分辨率是64*64.接下来是重点,我们怎么制作训练标签???YOLO在将输入图像划分成7*7网格后,图像中一个目标的BBOX的中心点若是落在某个网格内,则由这个网格负责预测这个目标。输入划分成7*7,对应的输出也是7*7*30,只不过最后是以向量的形式输出,但是宽度和高度是对应的大小。一张图像划分7*7grid,对每个grid建立一个标记,维度是25=20+4+1,20代表数据集的类别,这里使用的是VOC数据集,4代表若是这个grid中含有目标,则是[x,y,w,h],同样最后一个维度代表当前grid是否含有目标,若是则为1,否者为0.所以一张图像的label信息形式:label = np.zeros(size=(7,7,20)).这里还有一个小问题,上面label的形式说明每个grid最多只有一个真实的目标,如果在一个64*64的grid里面包含了多个目标,则只能取一个作为真实的标记,忽略其他的目标。自己认为这是YOLO精度稍差的一个重要的原因,网络架构设计的问题,导致YOLO很难去检测一群小目标,我想作者为了解决这个问题,把输入增大到448x448,相当于原始输入的2倍,相当于把原图像的小目标扩大2倍,以便让算法能够检测到,所以提高输入的分辨率YOLO能后检测到的目标分辨率降到32*32,也就是说若目标的尺寸大于32*32,就不会出现多个目标在一个grid中。
一个grid产生2个bbox,每个bbox产生五个预测值x,y,w,h,confidence.x,y是预测的bbox的中心点坐标,此坐标是相当于当前gird的偏移量,所以归一到0-1,w,h是bbox宽高,相对于输入图像的尺寸归一化到0-1,confidence是bbox的置信度得分,confidence = P(obj)*IOU,本质就是IOU值,若次grid含有目标,则置信度就是IOU值,否者为0。在计算IOU时,注意坐标转换x,y只是偏移量坐标,例如第2行第二列的grid的一个bbox坐标预测是0.2,0.5,实际上坐标是(1+0.2,1+0.5)/7归一化到原图尺寸的坐标。每个grid同时产生20个条件类别概率,这样一个图像输出维度是7x7x(20+5*2)=1470
计算损失函数:
以一张图像为例子,一个图像的标记是label=7x7x25,输出outout = 7x7x30=1470,预测的条件类别是7x7x20,pred_class = np.reshape(output[:7x7x20],(7,7,20)),预测的bbox置信度是7x7x2,pred_score = np.reshape(output[7x7x20:7x7x20+7x7x2]),预测的box坐标是7x7x8,pred_box = np.reshape(output[:7x7x8:-1],(7,7,2,4)),gt_box = label[...,1:5],gt_class = label[...,:5:],response = label[...,0](shape=7x7x1)-response就是判断每个grid中是否含有目标。

坐标损失有更大的权重 lambda_obj=5.0,分类损失权重是1,置信度损失含有目标的grid是1.0,不含目标的grid置信度损失权重是lambda_noobj=0.5,因为一个图像中有大量grid是不包含目标。
分类损失:cls_loss = np.mean(np.sum(np.square(gt_class-pred_class)*response,axis=(1,2)))
置信度损失也即IOU损失:
训练时每个grid二个bbox中只有一个bbox负责预测目标,也即具有和gt最大IOU的bbox负责预测,每个bbox都对应一个真实的标记信息。首先把gt_box(shape=7x7x4)进行变形-->gt_box = np.reshape(gt_box,(7,7,1,4))-->gt_box = np.tile(gt_box,[1,1,2,1]),在第三个维度扩展2倍。
iou = cal_iou(pred_box,gt) shape=7x7x2
iou_max = np.maxmium(iou,axis=-1,keep_dims=True) shape=7x7x1 得到负责预测的那个bbox
iou_mask = np.array(iou>=iou_max,dtype=bool) shape=7x7x2
obj_mask = iou_mask*response shape=7x7x2 即代表含有目标的gird中哪个bbox负责预测
noobj_mask = ~obj_mask
iou_loss1 = np.mean(np.sum(np.square(predict_score-iou)*obj_mask,axis=(1,2)))
iou_loss2 = lambda_noobj*np.mean(np.sum(np.square(predict_score-iou)*noobj_mask,axis=(1,2)))
定位损失:
obj_mask = np.expand_dim(obj_mask,axis=3)
coord_loss = np.mean(np.sum(np.square(pred_box-gt_box)*obj_mask,axis=(1,2,3)))
(3) 测试
测试的时候,输出是7x7x30,每个grid的2个bboxIOU得分和当前gird的20类条件类别概率输出相乘,得到概率输出是probs=7x7x2x20,最后一维代表当前bbox在每个特定类别的得分以及拟合的精确度,根据设置的得分阈值实验中0.2筛选满足阈值条件的bbox,然后进行NMS得到最后检测结果输出:
# 根据得分阈值过滤概率
filter_mat_probs = np.array(probs >= self.threshold, dtype='bool')
# np.nonzero()返回非0元素的索引
# 四元组list
filter_mat_boxes = np.nonzero(filter_mat_probs)
# 7x7x2x4
# 得到满足得分阈值的BOX坐标
# shape = nums*4
boxes_filtered = boxes[filter_mat_boxes[0],
filter_mat_boxes[1], filter_mat_boxes[2]]
# print('remain boxes',boxes_filtered.shape)
# print(boxes_filtered)
# 得到满足得分阈值的BOX类别概率
# shape = nums*1
probs_filtered = probs[filter_mat_probs]
# print('pros remian',probs_filtered.shape)
# print(probs_filtered)
# 得到满足条件的类别索引
# filter_mat_probs is a bool array
# can only find the first True
# 得到挑选出的类别标号
classes_num_filtered = np.argmax(
probs, axis=3)[
filter_mat_boxes[0], filter_mat_boxes[1], filter_mat_boxes[2]]
# print('class_num',classes_num_filtered.shape)
# print(classes_num_filtered)
boxes_filtered,classes_num_filtered,probs_filtered = self.NMS(boxes_filtered,
classes_num_filtered,
probs_filtered)4(检测结果):
mAP:0.414



5 (更多代码细节详见github)
更多代码细节,请参考我的github地址,下载预训练的权重,用于自己的数据集上。