PASCAL VOC 数据集:https://blog.csdn.net/baidu_27643275/article/details/82754902
yolov1阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82789212
yolov1源码解析:https://blog.csdn.net/baidu_27643275/article/details/82794559
yolov2阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82859273
本文介绍了yolo v1的实现过程,同时就其实现过程中几个关键的函数进行了详细的注释。
本文结构如下: 一、源码概述 二、建立网络 三、训练 四、测试
源码概述
源码地址:https://github.com/1273545169/object-detection/tree/master/yolo
./data下存放的是voc数据集和模型的权重;
config是配置文件,可以在此修改模型参数;
yolo_net.py建立网络和loss函数;
utils中的pascal_voc.py 用于处理训练样例;
train.py模型训练
predict.py模型测试
./test中存放的是测试图片;
一、建立网络
通过yolo_net.py中的build_network()方法建立网络,使用了dropout方法来防止过拟合
def build_network(self,
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
二、训练
使用train.py中的main()开始训练模型
pascal = pascal_voc('train')
yolo = YOLONet()
solver = Solver(yolo, pascal)
2.1、从PASCAL VOC 中获取训练数据并进行处理
首先,从VOC2007/ImageSets/Main/文件夹中获得所有训练样例的索引index(图片名),再通过def load_pascal_JPEGImages_annotation(index) 方法利用图片的索引值index来得到训练样例的路径和图片信息。此外,使用def prepare()增加水平翻转的训练样例,使得模型的拟合能力更好。
def load_pascal_JPEGImages_annotation(self, index):
"""
Load image and bounding boxes info from XML file in the PASCAL VOC
format.
"""
# data/VOCdevkit/VOC2007/JPEGImages存放源图片
# imname为训练样例路径
imname = os.path.join(self.data_path, 'JPEGImages', index + '.jpg')
im = cv2.imread(imname)
h_ratio = 1.0 * self.image_size / im.shape[0]
w_ratio = 1.0 * self.image_size / im.shape[1]
# im = cv2.resize(im, [self.image_size, self.image_size])
label = np.zeros((self.cell_size, self.cell_size, 25))
# data/VOCdevkit/VOC2007/Annotations存放的是xml文件
# 包含图片的boxes等信息,一张图片一个xml文件,与PEGImages中源图片一一对应
filename = os.path.join(self.data_path, 'Annotations', index + '.xml')
# 将xml文档解析为树
tree = ET.parse(filename)
# 得到图片中所有的box info
objs = tree.findall('object')
for obj in objs:
bbox = obj.find('bndbox')
# Make pixel indexes 0-based
x1 = max(min((float(bbox.find('xmin').text) - 1) * w_ratio, self.image_size - 1), 0)
y1 = max(min((float(bbox.find('ymin').text) - 1) * h_ratio, self.image_size - 1), 0)
x2 = max(min((float(bbox.find('xmax').text) - 1) * w_ratio, self.image_size - 1), 0)
y2 = max(min((float(bbox.find('ymax').text) - 1) * h_ratio, self.image_size - 1), 0)
# 得到类的索引值
cls_ind = self.class_to_ind[obj.find('name').text.lower().strip()]
# boxes (x1,y1,x2,y2)->(x,y,w,h)
boxes = [(x2 + x1) / 2.0, (y2 + y1) / 2.0, x2 - x1, y2 - y1]
# 确定(x,y)在哪个网格中
x_ind = int(boxes[0] * self.cell_size / self.image_size)
y_ind = int(boxes[1] * self.cell_size / self.image_size)
if label[y_ind, x_ind, 0] == 1:
continue
# p(object)
label[y_ind, x_ind, 0] = 1
# box
label[y_ind, x_ind, 1:5] = boxes
# p(class)
label[y_ind, x_ind, 5 + cls_ind] = 1
return imname, label, len(objs)
2. 2、loss函数
yolo_net.py中的loss_layer()方法定义loss函数
# predicts为模型预测值,shape(45,7,7,30),labels为真实值,shape(45,7,7,25)
def loss_layer(self, predicts, labels, scope='loss_layer'):
with tf.variable_scope(scope):
# 预测值
# class-20
predict_classes = tf.reshape(
predicts[:, :self.boundary1],
[self.batch_size, self.cell_size, self.cell_size, self.num_class])
# confidence-2
predict_confidence = tf.reshape(
predicts[:, self.boundary1:self.boundary2],
[self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell])
# bounding box-2*4
predict_boxes = tf.reshape(
predicts[:, self.boundary2:],
[self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell, 4])
# 实际值
# shape(45,7,7,1)
# response中的值为0或者1.对应的网格中存在目标为1,不存在目标为0.
# 存在目标指的是存在目标的中心点,并不是说存在目标的一部分。所以,目标的中心点所在的cell其对应的值才为1,其余的值均为0
response = tf.reshape(
labels[..., 0],
[self.batch_size, self.cell_size, self.cell_size, 1])
# shape(45,7,7,1,4)
boxes = tf.reshape(
labels[..., 1:5],
[self.batch_size, self.cell_size, self.cell_size, 1, 4])
# shape(45,7,7,2,4),boxes的四个值,取值范围为0~1
boxes = tf.tile(
boxes, [1, 1, 1, self.boxes_per_cell, 1]) / self.image_size
# shape(45,7,7,20)
classes = labels[..., 5:]
# self.offset shape(7,7,2)
# offset shape(1,7,7,2)
offset = tf.reshape(
tf.constant(self.offset, dtype=tf.float32),
[1, self.cell_size, self.cell_size, self.boxes_per_cell])
# shape(45,7,7,2)
x_offset = tf.tile(offset, [self.batch_size, 1, 1, 1])
# shape(45,7,7,2)
y_offset = tf.transpose(offset, (0, 2, 1, 3))
# convert the x, y to the coordinates relative to the top left point of the image
# the predictions of w, h are the square root
# shape(45,7,7,2,4) ->(x,y,w,h)
predict_boxes_tran = tf.stack(
[(predict_boxes[..., 0] + x_offset) / self.cell_size,
(predict_boxes[..., 1] + y_offset) / self.cell_size,
tf.square(predict_boxes[..., 2]),
tf.square(predict_boxes[..., 3])], axis=-1)
# 预测box与真实box的IOU,shape(45,7,7,2)
iou_predict_truth = self.calc_iou(predict_boxes_tran, boxes)
# calculate I tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
# shape(45,7,7,1), find the maximum iou_predict_truth in every cell
# 在训练时,如果该单元格内确实存在目标,那么只选择IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标
object_mask = tf.reduce_max(iou_predict_truth, 3, keep_dims=True)
# object prosibility (45,7,7,2)
object_probs = tf.cast(
(iou_predict_truth >= object_mask), tf.float32) * response
# calculate no_I tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
# noobject prosibility(45,7,7,2)
noobject_probs = tf.ones_like(
object_probs, dtype=tf.float32) - object_probs
# shape(45,7,7,2,4),对boxes的四个值进行规整,xy为相对于网格左上角,wh为取根号后的值,范围0~1
boxes_tran = tf.stack(
[boxes[..., 0] * self.cell_size - x_offset,
boxes[..., 1] * self.cell_size - y_offset,
tf.sqrt(boxes[..., 2]),
tf.sqrt(boxes[..., 3])], axis=-1)
# class_loss shape(45,7,7,20)
class_delta = response * (predict_classes - classes)
class_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(class_delta), axis=[1, 2, 3]),
name='class_loss') * self.class_scale
# object_loss confidence=iou*p(object)
# p(object)的值为1或0
object_delta = object_probs * (predict_confidence - iou_predict_truth)
object_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(object_delta), axis=[1, 2, 3]),
name='object_loss') * self.object_scale
# noobject_loss p(object)的值为0
noobject_delta = noobject_probs * predict_confidence
noobject_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(noobject_delta), axis=[1, 2, 3]),
name='noobject_loss') * self.noobject_scale
# coord_loss
coord_mask = tf.expand_dims(object_probs, 4)
boxes_delta = coord_mask * (predict_boxes - boxes_tran)
coord_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(boxes_delta), axis=[1, 2, 3, 4]),
name='coord_loss') * self.coord_scale
}
三、预测
使用predict.py文件来进行预测
def interpret_output(self, output):
class_probs = np.reshape(
output[0:self.boundary1],
(self.cell_size, self.cell_size, self.num_class))
confs = np.reshape(
output[self.boundary1:self.boundary2],
(self.cell_size, self.cell_size, self.boxes_per_cell))
boxes = np.reshape(
output[self.boundary2:],
(self.cell_size, self.cell_size, self.boxes_per_cell, 4))
x_offset = np.transpose(np.reshape(np.array([np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell),
[self.boxes_per_cell, self.cell_size, self.cell_size]), [1, 2, 0])
y_offset = np.transpose(x_offset, [1, 0, 2])
# convert the x, y to the coordinates relative to the top left point of the image
# the predictions of w, h are the square root
# multiply the width and height of image
boxes = tf.stack([(boxes[:, :, :, 0] + tf.constant(x_offset, dtype=tf.float32)) / self.cell_size * self.image_size,
(boxes[:, :, :, 1] + tf.constant(y_offset, dtype=tf.float32)) / self.cell_size * self.image_size,
tf.square(boxes[:, :, :, 2]) * self.image_size,
tf.square(boxes[:, :, :, 3]) * self.image_size], axis=3)
# 对bounding box的筛选分别三步进行
# 第一步:求得每个bounding box所对应的最大的confidence,结果有7*7*2个
# 第二步:根据confidence threshold来对bounding box筛选
# 第三步:NMS
# shape(7,7,2,20)
class_confs = tf.expand_dims(confs, -1) * tf.expand_dims(class_probs, 2)
# 4维变2维 shape(7*7*2,20)
class_confs = tf.reshape(class_confs, [-1, self.num_class])
# shape(7*7*2,4)
boxes = tf.reshape(boxes, [-1, 4])
# 第一步:find each box class, only select the max confidence
# 求得每个bounding box所对应的最大的class confidence,有7*7*2个bounding box,所以个结果有98个
class_index = tf.argmax(class_confs, axis=1)
class_confs = tf.reduce_max(class_confs, axis=1)
# 第二步:filter the boxes by the class confidence threshold
filter_mask = class_confs >= self.threshold
class_index = tf.boolean_mask(class_index, filter_mask)
class_confs = tf.boolean_mask(class_confs, filter_mask)
boxes = tf.boolean_mask(boxes, filter_mask)
# 第三步: non max suppression (do not distinguish different classes)
# 一个目标可能有多个预测框,通过NMS可以去除多余的预测框,确保一个目标只有一个预测框
# box (x, y, w, h) -> nms_boxes (x1, y1, x2, y2)
nms_boxes = tf.stack([boxes[:, 0] - 0.5 * boxes[:, 2], boxes[:, 1] - 0.5 * boxes[:, 3],
boxes[:, 0] + 0.5 * boxes[:, 2], boxes[:, 1] + 0.5 * boxes[:, 3]], axis=1)
# NMS:
# 先将class_confs按照降序排列,然后计算第一个confs所对应的box与其余box的iou,
# 若大于iou_threshold,则将其余box的值设为0。
nms_index = tf.image.non_max_suppression(nms_boxes, class_confs,
max_output_size=10,
iou_threshold=self.iou_threshold)
class_index = tf.gather(class_index, nms_index)
class_confs = tf.gather(class_confs, nms_index)
boxes = tf.gather(boxes, nms_index)
# tensor -> numpy,因为tensor中没有len()方法
class_index = class_index.eval(session=self.sess)
class_confs = class_confs.eval(session=self.sess)
boxes = boxes.eval(session=self.sess)
result = []
for i in range(len(class_index)):
result.append([self.classes[class_index[i]],
boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3],
class_confs[i]])
return result
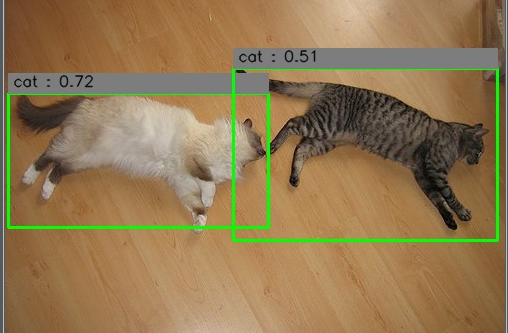
预测结果如下:
完整代码:
https://github.com/1273545169/object-detection/tree/master/yolo
训练过程中更多细节请看:
yolo v1 tensorflow版分类训练与检测训练