1.1训练,验证,测试集(Train / Dev / Test sets)
测试集和验证集的区别
验证集用于进一步确定模型中的超参数(例如正则项系数、ANN中隐含层的节点个数等)而测试集只是用于评估模型的精确度(即泛化能力)
简而言之就是:
验证集 核对的是 模型可训练参数的 泛化能力
测试集 核对的是 模型超参数的 泛化能力
大家要确保验证集和测试集的数据来自同一分布,因为你们要用验证集来评估不同的模型,尽可能地优化性能。如果验证集和测试集来自同一个分布就会很好。
在机器学习中,我们通常将样本分成训练集,验证集和测试集三部分,数据集规模相对较小,适用传统的划分比例,数据集规模较大的,验证集和测试集要小于数据总量的20%或10%。
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。
如果只有一个训练集和一个验证集,而没有独立的测试集,遇到这种情况,训练集还被人们称为训练集,而验证集则被称为测试集,不过在实际应用中,人们只是把测试集当成简单交叉验证集使用,并没有完全实现该术语的功能,因为他们把验证集数据过度拟合到了测试集中。
1.2 偏差,方差(Bias /Variance)
欠拟合高偏差 过拟合高方差
假定训练集误差是1%,为了方便论证,假定验证集误差是11%,可以看出训练集设置得非常好,而验证集设置相对较差,我们可能过度拟合了训练集,在某种程度上,验证集并没有充分利用交叉验证集的作用,像这种情况,我们称之为“高方差”。
假设训练集误差是15%,验证集误差是16%,假设该案例中人的错误率几乎为0%,人们浏览这些图片,分辨不出是不是猫。算法并没有在训练集中得到很好训练,如果训练数据的拟合度不高,就是数据欠拟合,就可以说这种算法偏差比较高。相反,它对于验证集产生的结果却是合理的,验证集中的错误率只比训练集的多了1%,所以这种算法偏差高,因为它甚至不能拟合训练集.
假设训练集误差是15%,偏差相当高,但是,验证集的评估结果更糟糕,错误率达到30%,在这种情况下,我会认为这种算法偏差高,因为它在训练集上结果不理想,而且方差也很高,这是方差偏差都很糟糕的情况。
假设训练集误差是0.5%,验证集误差是1%,用户看到这样的结果会很开心,猫咪分类器只有1%的错误率,偏差和方差都很低
1.3 机器学习基础(Basic Recipe for Machine Learning)
高偏差
1 更大的网络
2 延长训练时间
3 更好的算法
高方差
1 更多数据
2 正则化
3 更好的算法
1.4 正则化(Regularization)
https://blog.csdn.net/u012162613/article/details/44261657
用backprop计算出的dw值
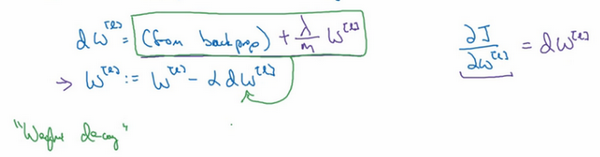
权重衰减了
1.5 为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)
直观上理解就是如果正则化项设置得足够大,权重矩阵W被设置为接近于0的值,直观理解就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
但是正则项会存在一个中间值,于是会有一个接近“Just Right”的中间状态。
1.6 dropout 正则化(Dropout Regularization)
如何实施dropout?方法有几种,最常用的方法即inverted dropout(反向随机失活)
1.8 其他正则化方法(Other regularization methods)
一.数据扩增
有时候我们无法扩增数据,但我们可以通过添加这类图片来增加训练集。例如,水平翻转图片,并把它添加到训练集。所以现在训练集中有原图,还有翻转后的这张图片,所以通过水平翻转图片,训练集则可以增大一倍.这虽然不如我们额外收集一组新图片那么好,但这样做节省了获取更多图片的精力.通过随意翻转和裁剪图片,我们可以增大数据集,额外生成假训练数据。
二.early stopping
early stopping的主要缺点就是你不能独立地处理这两个问题,因为提早停止梯度下降,也就是停止了优化代价函数J,因为现在你不再尝试降低代价函数J,所以代价函数J的值可能不够小,同时你又希望不出现过拟合,你没有采取不同的方式来解决这两个问题,而是用一种方法同时解决两个问题,这样做的结果是我要考虑的东西变得更复杂。
如果不用early stopping,另一种方法就是L2正则化,训练神经网络的时间就可能很长。我发现,这导致超级参数搜索空间更容易分解,也更容易搜索,但是缺点在于,你必须尝试很多正则化参数nameda的值,这也导致搜索大量nameda值的计算代价太高。
Early stopping的优点是,只运行一次梯度下降,你可以找出的较小值,中间值和较大值,而无需尝试正则化超级参数的很多值。
1.9 归一化输入(Normalizing inputs)
训练神经网络,其中一个加速训练的方法就是归一化输入。假设一个训练集有两个特征,输入特征为2维,归一化需要两个步骤:
1 均值归零
2 方差归一化
如果输入特征处于不同范围内,那么归一化特征值就非常重要了。如果特征值处于相似范围内,那么归一化就不是很重要了。执行这类归一化并不会产生什么危害,我通常会做归一化处理,虽然我不确定它能否提高训练或算法速度。
1.10 梯度消失/梯度爆炸(Vanishing / Exploding gradients)
直观理解是,权重W只比1略大一点,或者说只是比单位矩阵大一点,深度神经网络的激活函数将爆炸式增长,如果W比1略小一点,在深度神经网络中,激活函数将以指数级递减,虽然我只是讨论了激活函数以与L相关的指数级数增长或下降,它也适用于与层数L相关的导数或梯度函数,也是呈指数级增长或呈指数递减。
1.11 神经网络的权重初始化(Weight Initialization for Deep NetworksVanishing / Exploding gradients)
我们学习了深度神经网络如何产生梯度消失和梯度爆炸问题,最终针对该问题,我们想出了一个不完整的解决方案,虽然不能彻底解决问题,却很有用,有助于我们为神经网络更谨慎地选择随机初始化参数.
常用的权重初始化放方法
Xavier MSRA等
1.12 梯度的数值逼近(Numerical approximation of gradients)
在实施backprop时,有一个测试叫做梯度检验,它的作用是确保backprop正确实施。因为有时候,你虽然写下了这些方程式,却不能100%确定执行backprop的所有细节都是正确的。为了逐渐实现梯度检验,我们首先说说如何计算梯度的数值逼近,下节,我们将讨论如何在backprop中执行梯度检验,以确保backprop正确实施。
1.13 梯度检验(Gradient checking)
https://blog.csdn.net/u012328159/article/details/80232585

1.14 梯度检验应用的注意事项(Gradient Checking Implementation Notes)
