1.1 为什么是ML策略?(Why ML Strategy?)
当你尝试优化一个深度学习系统时,你通常可以有很多想法可以去试,问题在于,如果你做出了错误的选择,你完全有可能白费6个月的时间,往错误的方向前进,在6个月之后才意识到这方法根本不管用。
例如
收集更多训练数据
训练集的多样性不够,收集更多的具有多样性的实验数据和更多样化的反例集.
使用梯度下降法训练更长的时间
尝试一个不同的优化算法,例如Adam优化算法.
尝试更大的神经网络或者更小的神经网络
尝试dropout
尝试L2正则化
改变神经网络的结构:
修改激活函数
改变隐藏单元的数目
希望在这门课程中,可以教给你们一些策略,一些分析机器学习问题的方法,可以指引你们朝着最有希望的方向前进。这门课中,我会和你们分享我在搭建和部署大量深度学习产品时学到的经验和教训,我想这些内容是这门课程独有的。比如说,很多大学深度学习课程很少提到这些策略。事实上,机器学习策略在深度学习的时代也在变化,因为现在对于深度学习算法来说能够做到的事情,比上一代机器学习算法大不一样。我希望这些策略能帮助你们提高效率,让你们的深度学习系统更快投入实用。
1.2 正交化(Orthogonalization)
正交性或正交性是一种系统设计属性,它确保修改指令或算法的组成部分不会对系统的其他组件产生或传播副作用。独立地验证算法变得更加容易,它减少了测试和开发的时间。
当一个受监督的学习系统在设计时,这四个假设必须是正确的和正交的。
我们回到电视调节的例子,如果你的电视图像太宽或太窄,你想要一个旋钮去调整,你可不想要仔细调节五个不同的旋钮,它们也会影响别的图像性质,你只需要一个旋钮去改变电视图像的宽度。
所以类似地,如果你的算法在成本函数上不能很好地拟合训练集,你想要一组特定的旋钮,这样你可以用来确保你的可以调整你的算法,让它很好地拟合训练集,所以你用来调试的旋钮是你可能可以训练更大的网络,或者可以切换到更好的优化算法,比如Adam优化算法等等。
相比之下,如果发现算法对开发集的拟合很差,你希望有一组独立的旋钮去调试。比如说,你的算法在开发集上做的不好,它在训练集上做得很好,但开发集不行,然后你有一组正则化的旋钮可以调节,尝试让系统满足第二个条件。类比到电视,就是现在你调好了电视的宽度,如果图像的高度不太对,你就需要一个不同的旋钮来调节电视图像的高度,然后你希望这个旋钮尽量不会影响到电视的宽度。增大训练集可以是另一个可用的旋钮,它可以帮助你的学习算法更好地归纳开发集的规律,现在调好了电视图像的高度和宽度。
如果它不符合第三个标准呢?如果系统在开发集上做的很好,但测试集上做得不好呢?如果是这样,那么你需要调的旋钮,可能是更大的开发集。因为如果它在开发集上做的不错,但测试集不行这可能意味着你对开发集过拟合了,你需要往回退一步,使用更大的开发集。
最后,如果它在测试集上做得很好,但无法给你的猫图片应用用户提供良好的体验,这意味着你需要回去,改变开发集或成本函数。因为如果根据某个成本函数,系统在测试集上做的很好,但它无法反映你的算法在现实世界中的表现,这意味着要么你的开发集分布设置不正确,要么你的成本函数测量的指标不对。
1.3 单一数字评估指标(Single number evaluation metric)
评估你的分类器的一个合理方式是观察它的查准率(precision)和查全率(recall)。
查准率(precision):在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(recall):在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
查准率和查全率之间往往需要折衷,两个指标都要顾及到。
结合查准率和查全率的标准方法是F1 score
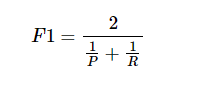
你可以将它看成是某种查准率和查全率的平均值,通过这个指标快速选出好的分类器。
1.4 满足和优化指标(Satisficing and optimizing metrics)
要把你顾及到的所有事情组合成单实数评估指标有时并不容易,这种情况下我发现设立满足和优化指标是很重要的。
假设你除了需要精准率还需要识别时间,你可以将准确度和运行时间组合成一个整体评估指标。例如cost=accuracy - 0.5*T。或者设定一个时间要求例如小于100ms。
通过定义优化和满足指标,就可以给你提供一个明确的方式,去选择“最好的”分类器。
更一般地说,如果你要考虑个N指标,有时候选择其中一个指标做为优化指标是合理的。所以你想尽量优化那个指标,然后剩下N-1个指标都是满足指标,意味着只要它们达到一定阈值,例如运行时间快于100毫秒,但只要达到一定的阈值,你不在乎它超过那个门槛之后的表现,但它们必须达到这个门槛。
1.5 训练/开发/测试集划分(Train/dev/test distributions)
集中讨论如何设立开发集和测试集,开发(dev)集也叫做开发集(development set),有时称为保留交叉验证集(hold out cross validation set)。
在设立开发集和测试集时,要选择这样的开发集和测试集,能够反映你未来会得到的数据,认为很重要的数据,必须得到好结果的数据,特别需要注意的是这里的开发集和测试集要来自同一个分布。所以不管你未来会得到什么样的数据,一旦你的算法效果不错,要尝试收集类似的数据,而且,不管那些数据是什么,都要随机分配到开发集和测试集上。因为这样,你才能将瞄准想要的目标,让你的团队高效迭代来逼近同一个目标,希望最好是同一个目标。
1.6 开发集和测试集的大小(Size of dev and test sets)
你可能听说过一条经验法则,在机器学习中,把你取得的全部数据用70/30比例分成训练集和测试集。或者如果你必须设立训练集、开发集和测试集,你会这么分60%训练集,20%开发集,20%测试集。机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。
但在现代机器学习中,我们更习惯操作规模大得多的数据集,比如说你有1百万个训练样本,这样分可能更合理,98%作为训练集,1%开发集,1%测试集。1%就是10,000个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时我们拥有大得多的数据集,所以使用小于20%的比例或者小于30%比例的数据作为开发集和测试集也是合理的。
测试集的目的是完成系统开发之后,测试集可以帮你评估投产系统的性能。方针就是,令你的测试集足够大,能够以高置信度评估系统整体性能。所以除非你需要对最终投产系统有一个很精确的指标,一般来说测试集不需要上百万个例子。对于你的应用程序,也许你想,有10,000个例子就能给你足够的置信度来给出性能指标了,也许100,000个之类的可能就够了,这数目可能远远小于比如说整体数据集的30%,取决于你有多少数据。
对于某些应用,你也许不需要对系统性能有置信度很高的评估,也许你只需要训练集和开发集。我认为,不单独分出一个测试集也是可以的。事实上,有时在实践中有些人会只分成训练集和测试集,他们实际上在测试集上迭代,所以这里没有测试集,他们有的是训练集和开发集,但没有测试集。如果你真的在调试这个集,这个开发集或这个测试集,这最好称为开发集。
总结一下,在大数据时代旧的经验规则,这个70/30不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集。
1.7 什么时候该改变开发/测试集和指标?(When to change dev/test sets and metrics)
总体方针就是,如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大,那就应该更改你的指标或者你的开发测试集,让它们能更够好地反映你的算法需要处理好的数据。
1.8 为什么是人的表现?(Why human-level performance?)
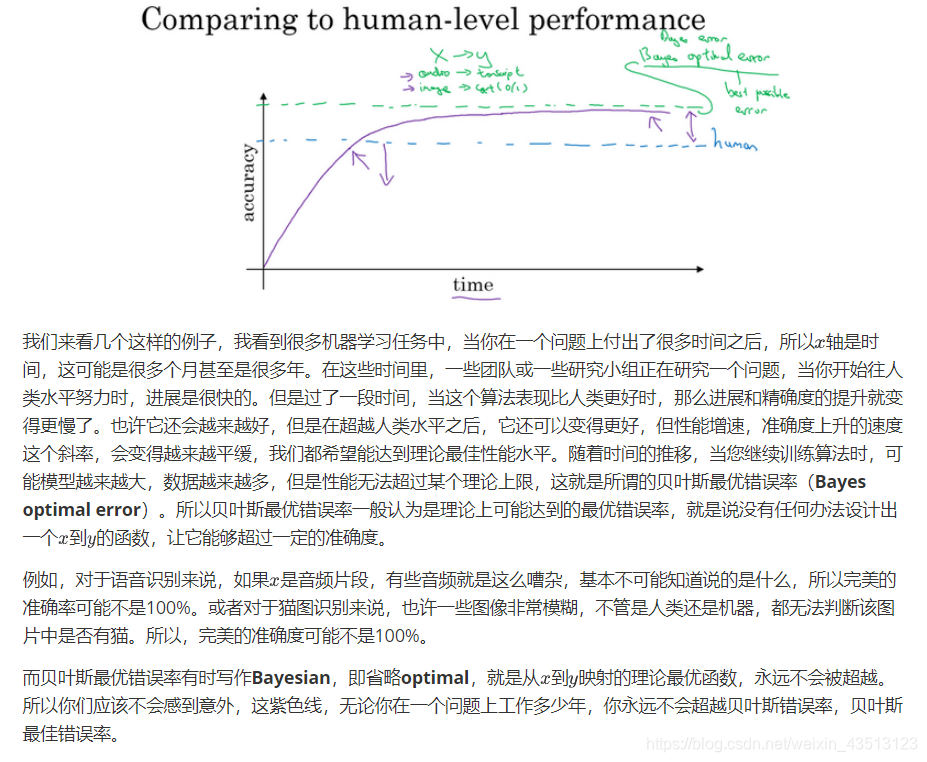
1.9 可避免偏差(Avoidable bias)
贝叶斯错误率或者对贝叶斯错误率的估计和训练错误率之间的差值称为可避免偏差,你可能希望一直提高训练集表现,直到你接近贝叶斯错误率,但实际上你也不希望做到比贝叶斯错误率更好,这理论上是不可能超过贝叶斯错误率的,除非过拟合。

可避免偏差这个词说明了有一些别的偏差,或者错误率有个无法超越的最低水平,那就是说如果贝叶斯错误率是7.5%。你实际上并不想得到低于该级别的错误率,所以你不会说你的训练错误率是8%,然后8%就衡量了例子中的偏差大小。你应该说,可避免偏差可能在0.5%左右,或者0.5%是可避免偏差的指标。而这个2%是方差的指标,所以要减少这个2%比减少这个0.5%空间要大得多。而在左边的例子中,这7%衡量了可避免偏差大小,而2%衡量了方差大小。所以在左边这个例子里,专注减少可避免偏差可能潜力更大。所以在这个例子中,当你理解人类水平错误率,理解你对贝叶斯错误率的估计,你就可以在不同的场景中专注于不同的策略,使用避免偏差策略还是避免方差策略。在训练时如何考虑人类水平表现来决定工作的重点。
1.10 理解人的表现(Understanding human-level performance)
假设一个普通的人类,未经训练的人类,在此任务上达到3%的错误率。普通的医生,也许是普通的放射科医生,能达到1%的错误率。经验丰富的医生做得更好,错误率为0.7%。还有一队经验丰富的医生,就是说如果你有一个经验丰富的医生团队,让他们都看看这个图像,然后讨论并辩论,他们达成共识的意见达到0.5%的错误率。所以我想问你的问题是,你应该如何界定人类水平错误率?人类水平错误率3%,1%, 0.7%还是0.5%

如图第一个框 你的训练错误率是5%,你的开发错误率是6%,不管你怎么定义人类水平错误率,结果是4%还是4.5%,这明显比都比方差问题更大。所以在这种情况下,你应该专注于减少偏差的技术,例如培训更大的网络。
如图第一个框 你的训练错误率是1%,开发错误率是5%,4%左右的差距比任何一种定义的可避免偏差都大。所以他们就建议,你应该主要使用减少方差的工具,比如正则化或者去获取更大的训练集。
这两种情况和你怎么定义人类表现无关,那么怎样才有关呢?
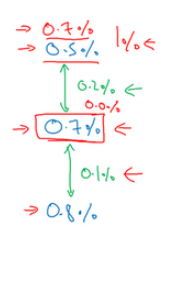
这时你的训练错误率是0.7%,你的开发错误率是0.8%。你用0.5%来估计贝叶斯错误率关系就很大。因为在这种情况下,你测量到的可避免偏差是0.2%,这是你测量到的方差问题0.1%的两倍,这表明也许偏差和方差都存在问题。但是,可避免偏差问题更严重。
这就说明了,为什么当你们接近人类水平时,更难分辨出问题是偏差还是方差。所以机器学习项目的进展在你已经做得很好的时候,很难更进一步。
1.11 超过人的表现(Surpassing human- level performance)

1.12 改善你的模型的表现(Improving your model performance)
学习了正交化、设立开发集和测试集、用人类水平错误率来估计贝叶斯错误率以及估计可避免偏差和方差。我们现在把它们全部组合起来写成一套指导方针,如何提高学习算法性能的指导方针。
想要让一个监督学习算法达到实用,基本上希望或者假设你可以完成两件事情。首先,你的算法对训练集的拟合很好,这可以看成是你能做到可避免偏差很低。还有第二件事你可以做好的是,在训练集中做得很好,然后推广到开发集和测试集也很好,这就是说方差不是太大。
总结一下前几段视频我们见到的步骤,如果你想提升机器学习系统的性能,我建议你们看看训练错误率和贝叶斯错误率估计值之间的距离,让你知道可避免偏差有多大。换句话说,就是你觉得还能做多好,你对训练集的优化还有多少空间。然后看看你的开发错误率和训练错误率之间的距离,就知道你的方差问题有多大。换句话说,你应该做多少努力让你的算法表现能够从训练集推广到开发集,算法是没有在开发集上训练的。
如果你想用尽一切办法减少可避免偏差,我建议试试这样的策略:比如使用规模更大的模型,这样算法在训练集上的表现会更好,或者训练更久。使用更好的优化算法,比如说加入 momentum 或者 RMSprop,或者使用更好的算法,比如 Adam。你还可以试试寻找更好的新神经网络架构,或者说更好的超参数。这些手段包罗万有,你可以改变激活函数,改变层数或者隐藏单位数,虽然你这么做可能会让模型规模变大。或者试用其他模型,其他架构,如循环神经网络和卷积神经网络。在之后的课程里我们会详细介绍的,新的神经网络架构能否更好地拟合你的训练集,有时也很难预先判断,但有时换架构可能会得到好得多的结果。