什么叫过拟合以及如何解决?
1 过拟合的由来
我们知道,无论是机器学习还是深度学习,都希望达到一个Bias-Variance tradeoff,即偏差和方差的均衡,之前博客中也贴过一个表格:
| 训练集上模型表现 | 测试集上模型表现 | 结论 |
|---|---|---|
| 不好 | 不好 | 欠拟合–对应高偏差或者高方差&高偏差 |
| 好 | 不好 | 过拟合–对应高方差 |
| 好 | 好 | 完美-适度拟合 |
以及一张来自NG课堂的图片:

由上表可以看到,过拟合的由来就是:模型在训练集上表现很好,而在测试集上表现很糟糕,这时候很可能出现了过拟合:即低偏差高方差!也即过拟合的来源!
同时,补充以下破坏了低偏差低方差时候的相应解决方案:
-
高偏差:
- 采用更大的神经网络结构
- 训练次数更多
- 改变网络结构
-
低偏差高方差:即过拟合
- 用更多的数据More Data
- 正则化Regularization
注:可以做到偏差和方差都降,而且一般更大的网络效果会更好,前提是网络已经正则化了!
2 过拟合的原因
之前在:面试 | vivo机器学习提前批面试题 已经总结过,过拟合的原因大概有以下几个:
- 数据集的原因。
- 训练集和测试集的分布不一样。
- 训练集噪音过大。样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系
- 建模时的“逻辑假设”到了模型应用时已经不能成立了。 任何预测模型都是在假设的基础上才可以搭建和应用的,常用的假设包括:假设历史数据可以推测未来,假设业务环节没有发生显著变化,假设建模数据与后来的应用数据是相似的,等等。如果上述假设违反了业务场景的话,根据这些假设搭建的模型当然是无法有效应用的。
- 参数太多、模型复杂度高
- 决策树模型。如果我们对于决策树的生长没有合理的限制和修剪的话,决策树的自由生长有可能每片叶子里只包含单纯的事件数据(event)或非事件数据(no event),可以想象,这种决策树当然可以完美匹配(拟合)训练数据,但是一旦应用到新的业务真实数据时,效果是一塌糊涂。
- 神经网络模型。
- 迭代次数过多。比如权值学习迭代次数足够多(Overtraining)。拟合了训练数据中的噪声和训练样例中没有代表性的特征。
- 或者是由于对样本数据,可能存在隐单元的表示不唯一,即产生的分类的决策面不唯一.随着学习的进行, BP算法使权值可能收敛过于复杂的决策面,并至极致。【不太明白】
3 过拟合的表现
前文已经提到,低偏差高方差,即训练集表现优秀,测试集表现糟糕~
4 如何解决?
上面提到的博客中同样提出了解决过拟合的方法,但是没有细说,下面笔者带着大家来深扒一波~
之前的内容重新总结了一下,大概处理方法归为几大类:数据集处理;正则化;集成方法;交叉验证!
-
数据集处理。
- 增加训练集。即More data。训练集越多,模型过拟合的概率就越小。
- 重新清洗数据。即进行数据清洗包括处理缺失值等等。导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
-
正则化。
- L1/L2正则。对模型复杂度进行惩罚。L1范数使得模型留下更少的变量,L2范数会使得模型更多变量系数为0。
- dropout。这个方法在神经网络里面很常用。dropout方法是ImageNet中提出的一种方法,通俗一点讲就是dropout方法在训练的时候让神经元以一定的概率不工作。具体见下图:
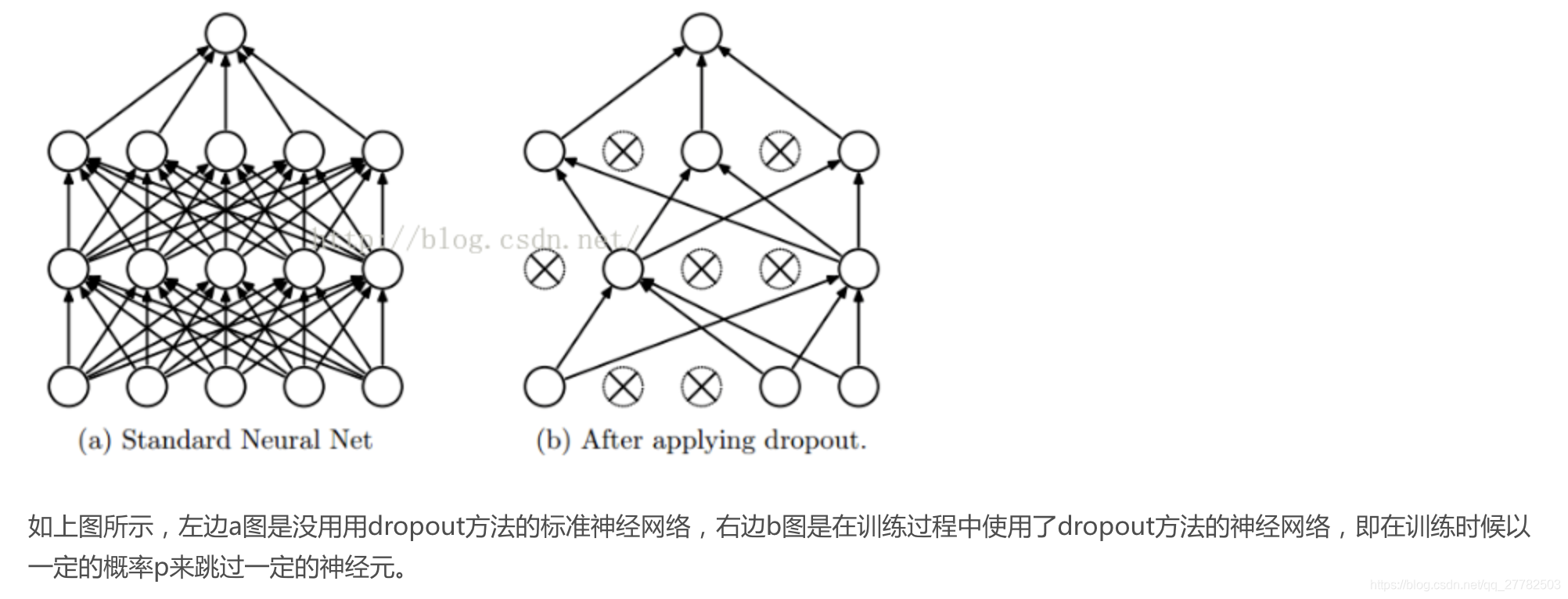
- early stopping。stop的是学习迭代次数。即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
-
ensemble方法。集成学习算法也可以有效的减轻过拟合。上文也提到,过拟合的本质就是低偏差高方差,要解决过拟合,则一方面降低偏差,一方面要降低方差。 Bagging通过平均多个模型的结果,来降低模型的方差。Boosting更多能减小偏差。
-
交叉验证 。详情见之前写的推文:机器学习 | 交叉验证。为什么交叉验证能解决过拟合呢?因为交叉验证能够选择比较好的泛化性的模型,不易于导致过拟合。
下面分开详细来说一下:
4.1 获取更多的数据 More data
比如下图中关于猫的图片,可以通过下面的方式进行数据扩充:
- 图片旋转
- 随意裁剪图片
- 图片的其余处理

优点:成本低。 我们这么做基本没有花费,代价几乎为零,除了一些对抗性代价。以这种方式扩增算法数据,进而正则化数据集,减少过拟合比较廉价。
即获取更多的数据可以有效避免过拟合。
4.2 正则化
关于L1/L2正则是机器学习和深度学习都有的方法,而dropout和early stopping是深度学习特有的处理方式!
4.2.1 L1/L2/Frobenius 弗罗贝尼乌斯范数正则
先上公式:
机器学习L1/L2范数正则:

这时候就要问了,什么叫L1/L2范数呢?以及L0范数?
L0/L1范数
- L0范数:向量中非0元素(指变量的非0系数)的个数
- L1范数:向量中各元素(指每个变量的系数)绝对值之和,也称为稀疏规则算子(目的:特征选择+可解释性更好)。
问题:为什么用L1范数而不用L0范数?
- L0范数不好求。L0范数很难进行优化求解。属于NP难问题
- L1范数好求。L1范数是L0范数的最优凸近似,更易优化求解。

L2范数
- 定义:向量各元素(这里指每个变量的不同系数)的平方和然后求平方根。
- L2范数越小,则向量的每个元素都很小,接近于0,但不会等于0
- L2范数的好处:
- 可以防止过拟合,提升泛化能力。(越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象)
- 有助于处理condition number(矩阵稳定性或者敏感度的度量;1附近较好,远大于1不好)不好的情况下矩阵求逆困难的问题
- 补充1:
什么叫 ill-condition 问题:假设我们有个方程组AX=b,我们需要求解X。如果A或者b稍微的改变,会使得X的解发生很大的改变,那么这个方程组系统就是ill-condition的,反之就是well-condition的。 - 补充2:condition number定义:即矩阵A的行列式乘以A的逆的行列式!

- 优化和求解变得稳定快速。
- L1/L2范数比较:
- L1会趋向于产生少量特征,其余特征均为0(Lasso);L2会选择更多特征,接近于0(Ridge)。
- 下降速度见下图:

- 模型空间限制见下图:

深度学习Frobenius 弗罗贝尼乌斯范数正则:即将每个神经元的权重平方求和。

上面就是L1/L2,Frobenius 弗罗贝尼乌斯范数正则化的原理,细心的小伙伴肯定发现了,这三个范数中都有一个超参数,即
!这个超参数有什么作用呢?要解释这个问题可以首先考虑一个问题:即为什么基于这三种范数的正则化可以防止过拟合?
机器学习中:
- 当 时,完全过拟合!因为只考虑降低偏差了!
- 当 很大时,出于整体要很小的目标,这时候参数就会很少了,很有可能会出现欠拟合的情况!
- 于是在 从很小的数开始逐渐递增的时候,肯定能在中间的某一个 处实现刚好拟合!这样就能解决过拟合问题!完美!
深度学习中:类似机器学习

4.2.2 dropout
什么叫dropout呢?
- 在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作
- 这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图所示:
那如何实现呢? 可以在两个步骤中分别实现
- 模型训练阶段【推荐】
- 大概分为三步:初始化参数引入概率;随机失活;缩放处理
- 缩放处理是除以keep-prob 即留下来的概率

- 模型预测阶段
- 缩放处理是乘以p,即对应上面的keep-prob。
- 具体见下图:

- 为什么是乘以p而不是像上面一样除以p呢? 即为啥两个阶段的缩放方式不同?
- 这是因为是在不同的阶段进行dropout处理! 【很重要】
- 其实本质都是一样,都是为了让失活后的神经元的整体的期望和未失活之前保持一致,进而缩放处理。
- 为什么乘以p呢?因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了。如果丢弃一些神经元,这会带来结果不稳定的问题,也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的,用户可能认为模型预测不准。那么一种“补偿”的方案就是每个神经元的权重都乘以一个p,这样在“总体上”使得测试数据和训练数据是大致一样的。比如一个神经元的输出是x,那么在训练的时候它有p的概率参与训练,(1-p)的概率丢弃,那么它输出的期望是px+(1-p)0=px。因此测试的时候把这个神经元的权重乘以p可以得到同样的期望。
为什么dropout能起到处理过拟合的作用呢?
- 取平均的作用。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
- 减少神经元之间复杂的共适应关系。 dropout导致两个神经元不一定每次都在一个网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
- Dropout类似于性别在生物进化中的角色。物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
4.2.3 early stopping
首先还是灵魂拷问:什么是early stopping?
- 早停法,停止的是训练模型!
- 为了防止过拟合而采取的提前停止模型训练。
那么如何实现呢?
神经网络中具体的做法如下:
- 切分数据集。首先将训练数据划分为训练集和验证集(划分比例为2:1);
- 训练模型。在训练集上进行训练,并且在验证集上获取测试结果(比如每隔5个epoch测试一下),随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练;
- 将停止之后的权重作为网络的最终参数。
为什么不能一直训练下去呢? 而非要提前停止?因为一直训练下去测试集上的准确率会下降!为什么会下降?可能有两个原因:
- 过拟合
- 学习率过大导致不收敛
参考
- https://blog.csdn.net/stdcoutzyx/article/details/49022443#commentBox
- https://zhuanlan.zhihu.com/p/23178423
- 知乎解释dropout:https://zhuanlan.zhihu.com/p/38200980
- L1/L2范数:https://blog.csdn.net/zouxy09/article/details/24971995
- 高大上的范数:https://blog.csdn.net/zouxy09/article/details/24972869#commentBox
- 早停法:https://blog.csdn.net/xizero00/article/details/46715225
- https://blog.csdn.net/qq_27782503/article/details/91902404#23_Early_Stopping_72