关于神经网络中过拟合的问题小记。
在训练的时候你的模型是否会出现训练时速度很慢?或者预测结果与训练结果相差过大的现象?那我们可能就需要处理一下过拟合的问题了。
当你的模型过于复杂时,比如说输入参数过多,你的模型就会出现过拟合问题,该模型虽然会在训练集上表现出较好的预测结果,然而!在预测的时候呢?预测结果就会表现的很差。根据维基的定义以及我平时的一些实验总结,当你observation 的noise 过多,输入维度过大,都可能会导致overfitting。
解决办法就是我们可以启用交叉验证(cross-validation),正则化(regularization),Early Stopping,剪枝(pruning),Bayesian priors,添加Dropout层,这几种方法。
cross-validation:
cross-validation 的原理就是现在它的一个子集上做训练,这个子集就是训练集,再用验证集测试所训练出的模型,来评价模型的性能和指标,最后再用测试集来预测。
Early Stopping就是在每次训练的epoch结束时,将计算出的accuracy 跟上一次的进行比较,如果accuracy 不再变化,那么停止训练。
regularization:
模型假设三层,输入,隐藏,输出。输入层为2个神经元,输出为2个,batchsize为10,下图为当隐藏层神经元个数分别设置为3,6,20时,模型的情况: 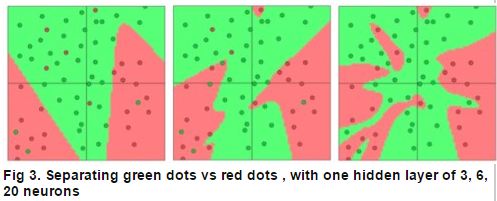
注意看当隐藏神经元为20时,模型的状况,每个红色的点都被完美的归类,没错,这在训练时结果是很好,但是在测试集的表现呢?这就不一定了,谁能保证自己的训练结每点噪声呢?是不是?所以用这个模型去预测未知的,就可能造成预测结果很差,这就是NN的overfitting问题。
所以一般大部分情况,我们在调试模型时很多时候是在跟overfitting做斗争。关于regularization 方法。
简单来说就是在目标函数上加一个λλ 使之变成 Error+λf(θ)Error+λf(θ) ,λλ 用来惩罚那些权重很大的向量,称之为正则系数吧!λ=0λ=0 就意味着没有采用regularization来预防overfitting。
regularization 有 L1 regularization和L2 regularization。如果你想知道哪一个特征对最后的结果产生了比较大的影响,可以采用L1 regularization,如果你不那么在意对特征的分析,那就用L2 regularization吧。
添加Dropout层:
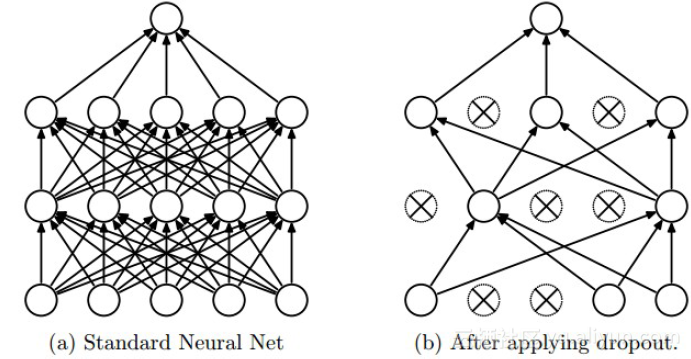
具体实现可参考论文:Dropout: A Simple Way to Prevent Neural Networks from Overfitting